





pyhton|爬取彩票数据
背景:作者之前看到过不少朋友介绍利用python环境来爬取彩票数据的文章,方法大致都很类似,今天我也讲一下关于传统方法解析网页获得数据,同时给大家介绍一种可能被大家忽略的方法,对于网页结构化的表的数据可以获得比较高的数据获取效率。
环境:Python3.7/MongoDB
目标爬取页面:http://kaijiang.zhcw.com/zhcw/html/3d/list.html
简要说明一下爬虫的步骤:
1.选取目标网页
2.观察结构(网页结构、数据结构)
3.选用解析工具(虽然有很多朋友喜欢使用Beautyfulsoup,但是在下还是建议使用xpath,因为效率比较高一点)
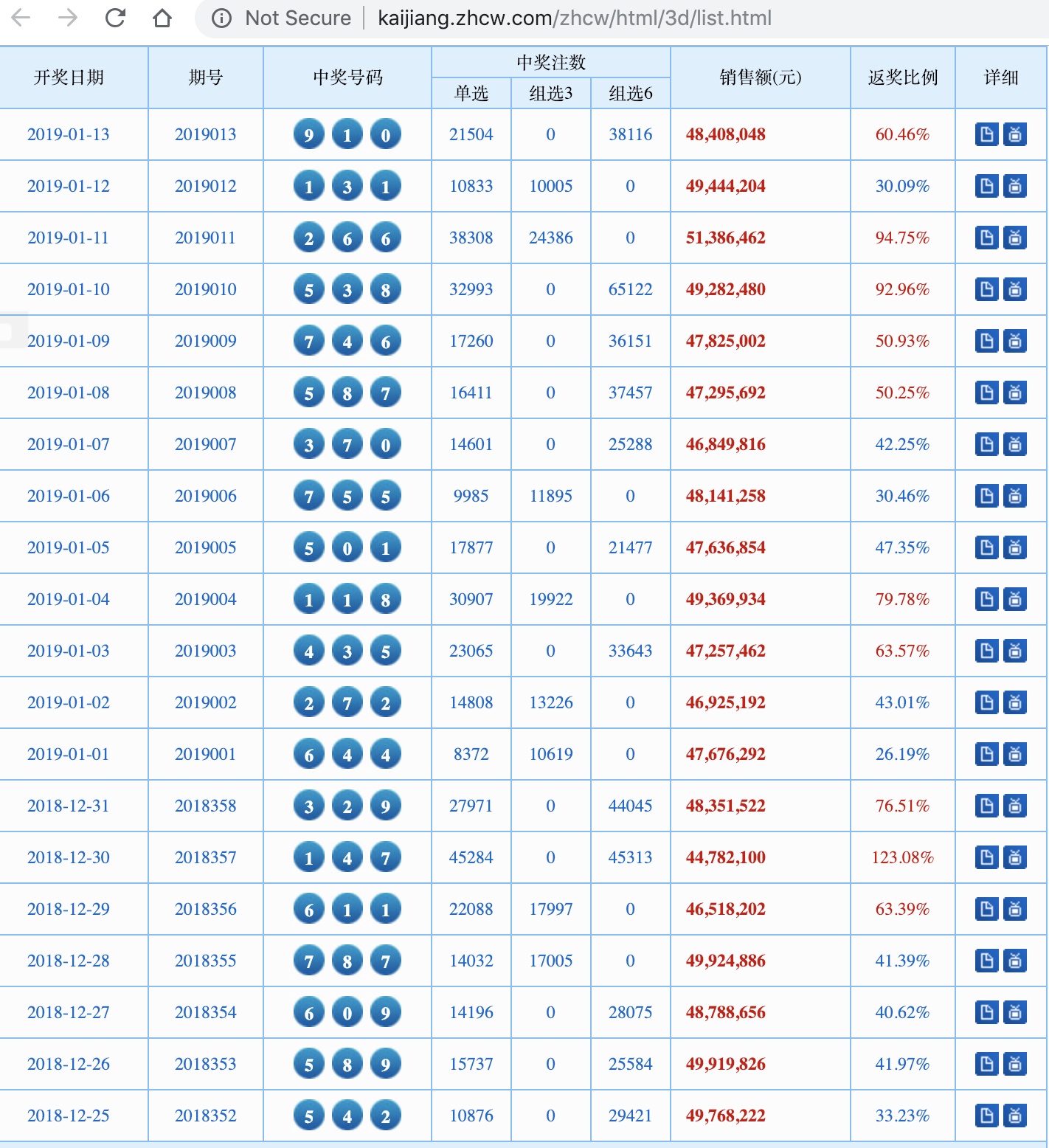
4.数据的持久化(俗话说光爬数据不储存就是在耍流氓.需要考虑用什么方式储存从页面上获取的信息,Excel、MySql还是MongoDB,本例将使用MongoDB做为储存工具) 在正式开始工作之前我们来看看我们需要爬取的页面是什么样子 !
方法一:
方法一我们将直接通过常规方法对页面进行解析获取数据。下面我们通过翻页来查看网页地址都发生了些什么变化:
page1:http://kaijiang.zhcw.com/zhcw/html/3d/list_1.html
page2:http://kaijiang.zhcw.com/zhcw/html/3d/list_2.html
page3:http://kaijiang.zhcw.com/zhcw/html/3d/list_3.html
通过上面的观察,我们可以发现在我们翻页获取新的网页信息的时候,只有list_x这个地方发生了变化,那么我们的工作就变得简单了,我们只需要替换到list_x中x的值就可以获取到新的一页的数据了。那么我们的思路就是我们只需要解析一个网页的数据并获取,最后做个轮询,那么我们就可以获取整个网站的彩票数据了,想想就有点小激动。
那么接下来我们来看一看我们需要的数据都是放在什么样的地方,我们怎么样才能提取出来,现在观察网页结构,仔细一看也是相当的简单。我可以看到每一期的彩票信息都是放在一个tr标签对中,发现这个信息那么接下来代码工作就可以开始了。

def 简单解释一下上面的代码,上面我们使用到的解析网页的工具是xpath,先不说解析的效率,语法个人觉得比Beautyfulsoup好一些,当然这因人而异,也有不少人觉soup好用。既然我们之前分析得出我们需要的信息在tr的每个标签中,我们先获取到每个网页中的所有tr标签,做个轮询我们就可以获取到每个标签对应的信息了。
下面可以写一个存数据库的函数了:
def 万事具备,先可以写一个main函数了,直接把所有的数据存入mongodb数据库了。
def 打完收工,是不是相当简单!!!
方法二:
这个是一个我感觉被大家忽略了的方法。遇到类似这样的网页表单,可能比上面方法仔细去分析网页结构,查找数据在网页中存放的位置和特点来的更简单一点,那么这个方法就是什么呢? 千呼万唤始出来,这个方法就是pandas中的read_html方法了,是不是很容易被大家忽略掉了,接下来就为大家介绍这种方法。
import pandas as pd
def 我们先来查看一下返回打印出来的结果:
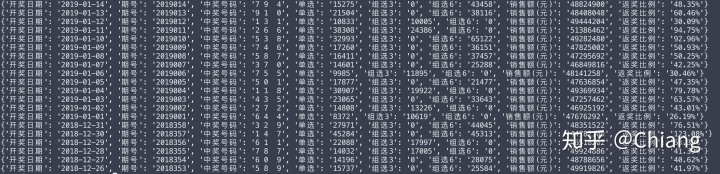
这样的结果就是我想要的结果了,其实代码中df这部就可以获取到一个dataframe数据表单,我把它转换成了一个个的字典是为了往MongoDB数据库存取方便,如果你没有这样需要,直接到pd.read_html(r.text)就可以了。重复上面的main函数就可以直接存数据库,这样的操作是不是比上面的解析网页结构要简单了不少,以后遇到类似这样的网页表单结构,也可以采取类似的骚操作,就比大家熟悉的方法效率高一些。















 2780
2780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









