





xue
学
tu
途
Hello,各位小伙伴们大家早上好呀,这期,博主给大家分享如何用BP神经网络回归去拟合波士顿的房价数据,从而训练出一个可以预测波士顿房价的神经网络模型。
神经网络回归
BP神经网络+回归

神经网络回归(Quantile RegressionNeural Network ,QRNN)是由Talor提出来的非参数非线性方法。它结合了神经网络和回归的两大优势,具有强大功能,能够揭示数据分布规律。
这里我们用到BP神经网络做回归,博主在之前的推文中已经给大家详细地介绍了BP神经网络,还不熟悉理论的小伙伴们可以翻一下之前的文章。
深度学习开端---BP神经网络
回归是确定两种或两种以上的变量间相互依赖的定量关系的方法。这里我们通过波士顿地区的13个特征与其房价,来确定这13个特征(自变量)和房价(因变量)之间的关系(模型)。
理论是指导实践的基础,实践又是巩固理论的利器。下面,博主就和小伙伴们通过一个简单的实验来巩固之前所学的BP神经网络吧。
实验
实验环境
Anaconda Python 3.7
Jupyter Notebook
Keras
环境安装在之前的推文中已经介绍,还没安装的小伙伴可以翻一下。
Python开发环境---Windows与服务器篇
Python深度学习开发环境---Keras
实验步骤
加载数据
划分训练集和验证集 # 用验证集去评估模型的稳健性,防止过拟合。
数据归一化 # 目的是消除数据间量纲的影响,使数据具有可比性
构建神经网络与训练
训练历史可视化
保存模型
模型的预测功能与反归一化
代码
核心代码
model = Sequential() # 初始化,很重要!model.add(Dense(units = 10, # 输出大小 activation='relu', # 激励函数 input_shape=(x_train_pd.shape[1],) # 输入大小, 也就是列的大小 ) )model.add(Dropout(0.2)) # 丢弃神经元链接概率model.add(Dense(units = 15,# kernel_regularizer=regularizers.l2(0.01), # 施加在权重上的正则项# activity_regularizer=regularizers.l1(0.01), # 施加在输出上的正则项 activation='relu' # 激励函数# bias_regularizer=keras.regularizers.l1_l2(0.01) # 施加在偏置向量上的正则项 ) )model.add(Dense(units = 1, activation='linear' # 线性激励函数 回归一般在输出层用这个激励函数 ) )print(model.summary()) # 打印网络层次结构model.compile(loss='mse', # 损失均方误差 optimizer='adam', # 优化器 )history = model.fit(x_train, y_train, epochs=200, # 迭代次数 batch_size=200, # 每次用来梯度下降的批处理数据大小 verbose=2, # verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:输出训练进度,2:输出每一个epoch validation_data = (x_valid, y_valid) # 验证集 )参数
Dense: 全连接层。
Dropout: 以一定概率放弃两层之间的一些神经元链接,防止过拟合,可以加在网络层与层之间。
regularizer: 正则化,防止过拟合,可以加在权重、输出、偏置上。
optimizer: 优化器,梯度下降的优化方法
这些都在之前的推文中有所介绍,小伙伴们可以去翻阅一下。
码前须知---TensorFlow超参数的设置
activation: 激励函数,‘linear’一般用在回归任务的输出层,而‘softmax’一般用在分类任务的输出层。
loss: 拟合损失方法,这里用到了‘mse’均方误差,keras还有别的误差,在后续的推文会一一介绍。
epochs 与 batch_size:前者是迭代次数,后者是用来更新梯度的批数据的大小,iteration = epochs / batch_size, 也就是完成一个epoch需要跑多少个batch。这这两个参数可以用控制变量法来调参,控制一个参数,调另外一个,看损失曲线的变化。
小伙伴们可以去keras官网查看更多的参数含义与用途,博主也会在后续的课程中通过实验的方法将这些参数涉及进来,让大家的知识点串联起来。
Keras官网
https://keras.io/
Git链接
代码
https://github.com/ChileWang0228/DeepLearningTutorial/tree/master/MLP
训练结果
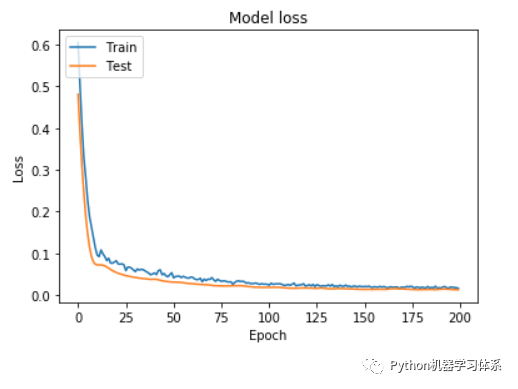
训练过程
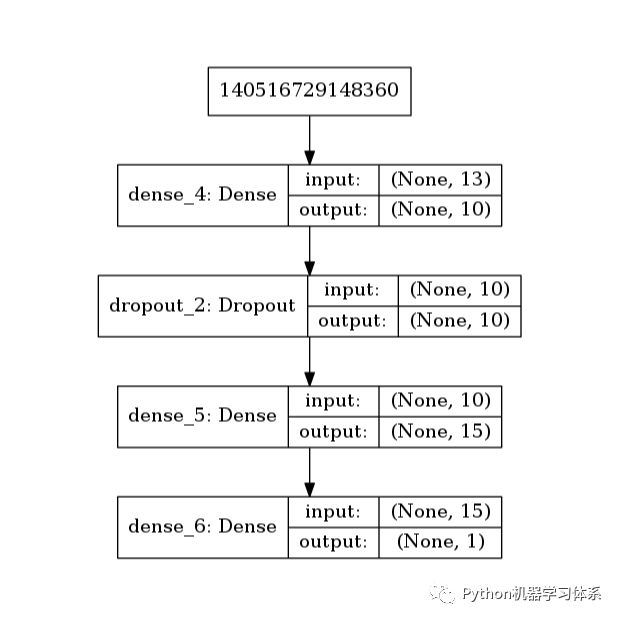
网络结构
结果分析
在迭代了200个epochs之后,训练集和验证集的损失loss,趋于平稳,这时,我们得到的模型已经是最优的了。所以讲epoch设置为200即可。
代码实践视频
视频卡顿?bilibili值得拥有~(っ•̀ω•́)っ✎⁾⁾ 我爱学习
https://www.bilibili.com/video/av55542068/
总结
好了,到这里,我们就已经将BP神经网络回归的知识点讲完了,上面的实验步骤并不是每一步都是必须的,不过博主还是给大家都过了一遍,学习嘛,最重要的当然是整整齐齐。大家在掌握了整个流程之后,就可以在博主的代码上修修补补,训练自己的神经网络来做回归任务了。
下一期,博主就带领大家用BP神经网络来做文本分类,敬请期待把~
留言

博主刚弄的一个留言功能,欢迎各位小伙伴踊跃留言。
有啥建议或者意见都可以提出来~


















 2212
2212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









