





经常有人说,数据库单表不要超过500万行,这有没有道理呢?本文我们不谈数据库技巧也不谈优化方式,只是用实例来给大家演示一下,数据表数据激增给查询性能带来的影响。
测试环境
之前阿里云活动,刚好搞了1个“云数据库 RDS版”,本次刚好拿来测试,配置如下:
数据库类型:MySQL 5.7
CPU:1核
数据库内存:1024MB模拟“用户信息表”来进行测试,建立以下数据表:
CREATE TABLE `user_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`name` varchar(32) NULL COMMENT '姓名',
`phone_number` varchar(32) NULL COMMENT '电话号码',
`email` varchar(32) NULL COMMENT '电子邮箱',
`birthday` varchar(32) NULL COMMENT '生日',
`constellation` varchar(32) NULL COMMENT '星座',
`edu_back` varchar(32) NULL COMMENT '学历',
PRIMARY KEY (`id`)
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci;数据生成
得益于阿里云DMS自带的“自动生成测试数据”功能,使得可以批量生成测试数据,大大方便了测试流程。后续将直接使用该功能生成原始数据。
测试说明
本次测试内容是:测试行数的增加对检索性能的影响,测试维度有2个,一是带索引字段,二是不带索引字段。
由于主键的id字段默认带唯一索引,因此不再额外增加索引。表中其他字段均不带索引。使用时分别使用 id 和 email 字段进行测试。
测试数据
1000行
首先我们自动生成1000行测试数据,使用:
SELECT * FROM user_info where id=345;进行检索,测试结果为:

耗时 4 毫秒。
下面使用同一行的email值进行检索:
SELECT * FROM user_info where email='h3l_q_iozoi@dmstest.com.cn';测试结果也是耗时 4 毫秒,两者没有差距。
接下去我们增加数据量。
10000行
我们增加9000行数据,使数据量达到10000行,同时为避免数据库缓存数据影响测试结果,后续均使用不同的id行来进行测试。(email也是随机找到一个)
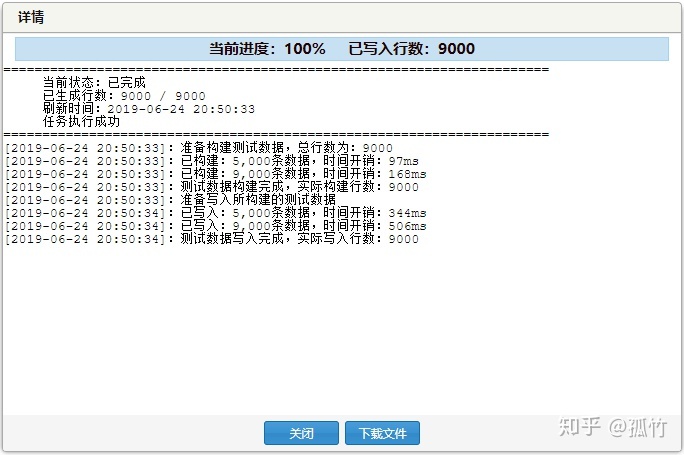
我们继续测试:
(1)使用 id 进行检索,耗时 2 毫秒(居然比1000行时还要少,有点不科学)
(2)使用 email 进行检索,耗时 6 毫秒。
10万行
我们再增加90000行数据,使数据量达到100000行。
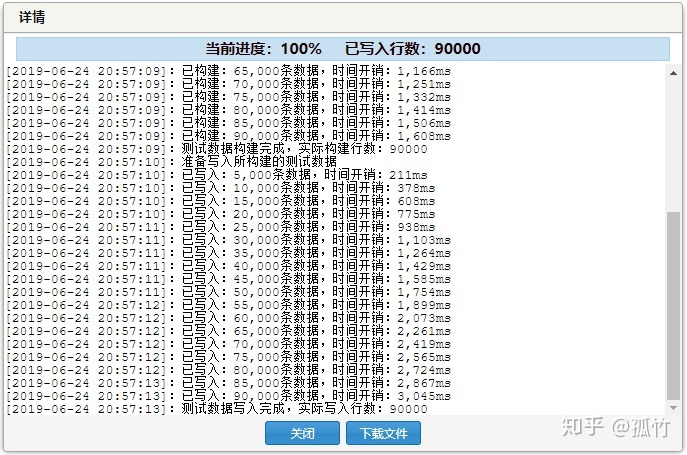
测试结果为:
(1)使用 id 进行检索,耗时 8 毫秒
(2)使用 email 进行检索,耗时 78 毫秒。
100万行
我们再增加900000行数据,是数据量达到1000000行。
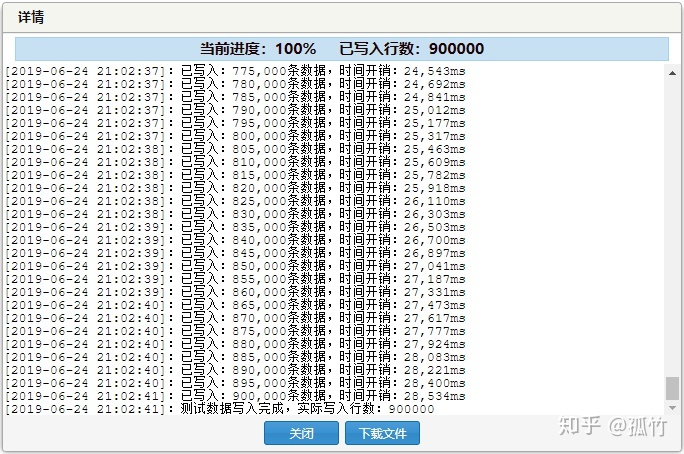
测试结果为:
(1)使用 id 进行检索,耗时 3 毫秒
(2)使用 email 进行检索,耗时 387 毫秒。
200万行
由于阿里云DMS自带的工具一次最多只能生成100万行记录,遇到了瓶颈,后面为了能够一次性插入更多的数据,这里用了一个奇技淫巧,我们使用相同的表结构新增一个中转表(命名:temp_copy,以下简称“副表”),先将主表数据拷贝一份过去,再把数据拷贝回来,这相当于一来一回操作能够将主表数据翻倍,后面我们就使用这个方法来增加数据。
先将数据从主表拷贝到副表(耗时 13338 毫秒):
INSERT INTO temp_copy (name,phone_number,email,birthday,constellation,edu_back) (SELECT name,phone_number,email,birthday,constellation,edu_back FROM user_info) ;然后再将数据从副表拷贝一份至主表(耗时 11041 毫秒):
INSERT INTO user_info (name,phone_number,email,birthday,constellation,edu_back) (SELECT name,phone_number,email,birthday,constellation,edu_back FROM temp_copy) ;继续进行之前的测试,测试结果为:
(1)使用 id 进行检索,耗时 5 毫秒
(2)使用 email 进行检索,耗时 6739 毫秒。
第2项数据突变有点明显,我再使用其他数据测试了几遍,依然在这个范围徘徊,因此这个数据还是可靠的。
500万行
我们将数据继续在主表和副表之间倒腾了一遍,数据量达到了5000000行,我们继续测试:
(1)使用 id 进行检索,耗时 5 毫秒
(2)使用 email 进行检索,耗时 20289 毫秒。
1300万行
后面继续增加数据,可以很明显的感觉到插入数据的时间越来越多,这一次从主表拷贝至副表,500万行,耗时 61624 毫秒。我们继续从副表拷贝至主表,800万行,耗时 100028 毫秒。
继续测试,测试结果为:
(1)使用 id 进行检索,耗时 7 毫秒
(2)使用 email 进行检索,耗时 57498 毫秒。
3400万行
我们继续,再“左右到右手”进行一次拷贝:
(1)主表拷贝至副表,插入1300万行,耗时 169816 毫秒。
(2)副表拷贝至主表,插入2100万行,耗时 263856 毫秒。
数据量达到3400万行时,储存容易已经达到了3G,非常恐怖。
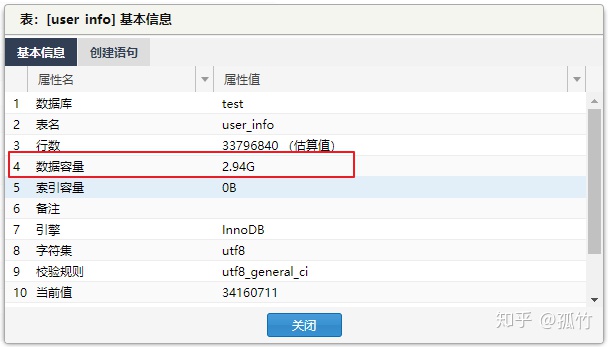
继续测试,测试结果为:
(1)使用 id 进行检索,耗时 6 毫秒
(2)使用 email 进行检索,耗时 153407 毫秒。
测试结果
我们整理一遍以上的测试结果:
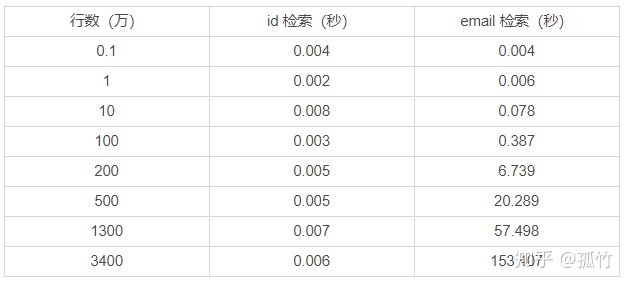
从100万行开始,email检索项的时间开始激增,事实上,这个检索时间已经大大超出能够接受的范围了。从以上的结果也可以看出建立索引的重要性。
后续我再测测同样数据量在其他数据库(Oracle、postgreSQL等)中的表现,敬请期待。
作者:赖一鸣
出自:孤竹说(微信公众号ID:iam1ming)
原文:MySQL亿级数据性能测试















 4643
4643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









