





底层有一个函数叫Py_Unicode_New的函数,为Unicode字符串申请空间,借助这个函数看一下unicode字符串的内存分布情况。像这样的特性API很多。

特性API的作用
PyObject *
PyUnicode_New(Py_ssize_t size, Py_UCS4 maxchar)//这个函数负责为Unicode字符串申请空间
{/* 传入两个参数,size表示字符的个数,多出来一个maxchar;
最大字符,最大字符不同,申请的空间不同*/
/* 对空字符串的优化 */
if (size == 0) {
return unicode_new_empty();//字符个数为0,则不用申请空间
}
PyObject *obj; //所有对象的父类
PyCompactUnicodeObject *unicode;//字符型对象
void *data;//空类型,需要时将数据转化为实际存储的类型
enum PyUnicode_Kind kind;//字符实际编码使用的类型
int is_sharing, is_ascii;
Py_ssize_t char_size; //实际编码需要几个字符
Py_ssize_t struct_size;//PyASCIIObject基本类型结构体的大小
is_ascii = 0;
is_sharing = 0;
struct_size = sizeof(PyCompactUnicodeObject);
//如果maxchar不小于128,基本类型为PyCompactUnicodeObject
//最大字符小于128,并且字符位宽为1个字节,即标准的ASCII可识别的有效字符仅有128个
//此时创建PyASCIIObject对象,字符实际编码使用的类型为PyUnicode_1BYTE_KIND()
if (maxchar < 128) {
kind = PyUnicode_1BYTE_KIND;
char_size = 1;
is_ascii = 1;
struct_size = sizeof(PyASCIIObject);
}
//最大字符大于128小于256,并且字符位宽为1个字节,即标准的ASCII可识别的有效字符仅有128个
//此时创建PyCompactUnicodeObject对象,字符实际编码使用的类型为PyUnicode_1BYTE_KIND()
else if (maxchar < 256) {
kind = PyUnicode_1BYTE_KIND;
char_size = 1;
}
//最大字符大于256小于65536,并且字符位宽为2个字节
//此时创建PyCompactUnicodeObject对象,字符实际编码使用的类型为PyUnicode_2BYTE_KIND()
else if (maxchar < 65536) {
kind = PyUnicode_2BYTE_KIND;
char_size = 2;
if (sizeof(wchar_t) == 2)
is_sharing = 1;
}
//最大字符大于65536,并且字符位宽为4个字节
//此时创建PyCompactUnicodeObject对象,字符实际编码使用的类型为PyUnicode_4BYTE_KIND()
else {
if (maxchar > MAX_UNICODE) {
PyErr_SetString(PyExc_SystemError,
"invalid maximum character passed to PyUnicode_New");
return NULL;
}
kind = PyUnicode_4BYTE_KIND;
char_size = 4;
if (sizeof(wchar_t) == 4)
is_sharing = 1;
}
/*确保字符个数没有溢出. */
if (size < 0) {
PyErr_SetString(PyExc_SystemError,
"Negative size passed to PyUnicode_New");
return NULL;
}
if (size > ((PY_SSIZE_T_MAX - struct_size) / char_size - 1))
return PyErr_NoMemory();
/* 来自_PyObject_New()的重复分配代码,而不是对PyObject_New()的调用,
因此我们能够为对象及其数据缓冲区分配空间。
*/
obj = (PyObject *) PyObject_MALLOC(struct_size + (size + 1) * char_size);
if (obj == NULL) {
return PyErr_NoMemory();
}
//绑定PyUnicode_Type的类型信息
_PyObject_Init(obj, &PyUnicode_Type);
//根据使用的不同结构体头,通过指针偏移找到实际字符串data的开始位置
unicode = (PyCompactUnicodeObject *)obj;
if (is_ascii)
data = ((PyASCIIObject*)obj) + 1;
else
data = unicode + 1;
//设定state内部类的状态信息
_PyUnicode_LENGTH(unicode) = size;
_PyUnicode_HASH(unicode) = -1;
_PyUnicode_STATE(unicode).interned = 0;
_PyUnicode_STATE(unicode).kind = kind;
_PyUnicode_STATE(unicode).compact = 1;
_PyUnicode_STATE(unicode).ready = 1;
_PyUnicode_STATE(unicode).ascii = is_ascii;
//实际data使用的编码字节
if (is_ascii) {
((char*)data)[size] = 0;
_PyUnicode_WSTR(unicode) = NULL;
}
//一个字节
else if (kind == PyUnicode_1BYTE_KIND) {
((char*)data)[size] = 0;
_PyUnicode_WSTR(unicode) = NULL;
_PyUnicode_WSTR_LENGTH(unicode) = 0;
unicode->utf8 = NULL;
unicode->utf8_length = 0;
}
//两个字节
else {
unicode->utf8 = NULL;
unicode->utf8_length = 0;
if (kind == PyUnicode_2BYTE_KIND)
((Py_UCS2*)data)[size] = 0;
//四个字节
else /* kind == PyUnicode_4BYTE_KIND */
((Py_UCS4*)data)[size] = 0;
if (is_sharing) {
_PyUnicode_WSTR_LENGTH(unicode) = size;
_PyUnicode_WSTR(unicode) = (wchar_t *)data;
}
else {
_PyUnicode_WSTR_LENGTH(unicode) = 0;
_PyUnicode_WSTR(unicode) = NULL;
}
}
#ifdef Py_DEBUG
unicode_fill_invalid((PyObject*)unicode, 0);
#endif
assert(_PyUnicode_CheckConsistency((PyObject*)unicode, 0));
return obj;
}
这个函数通过maxchar的不同创建了两个字符串对象,PyASCIIObject和PyCompactUnicodeObject,通过源码可以发现,PyCompactUnicodeObject是继承PyASCIIObject的。整个函数流程为:maxchar小于128,并且字符位宽为1个字节,创建PyASCIIObject对象;maxchar小于256,并且字符位宽为1个字节,创建PyCompactUnicodeObject对象。maxchar小于65536,并且字符位宽为2个字节,创建PyCompactUnicodeObject对象;码位个数大于65536且小于MAX_UNICODE,,创建PyCompactUnicodeObject对象。通过这句代码obj = (PyObject *) PyObject_MALLOC(struct_size + (size + 1) * char_size);实际分配了内存。调用PyObject_INIT(obj, &PyUnicode_Type)函数来将PyUnicode_Type实例绑定到字符串对象的头部。就赋予了字符串对象实际类型和属性。
根据不同的maxchar对应不同的kind

根据不同的maxchar选择不同的kind
根据不同的kind对应不同的底层结构体,和字符存储单元

根据不同的kind对应不同的底层结构体,和字符存储
typedef struct {
PyObject_HEAD//不可变长对象公用头
Py_ssize_t length; //字符串长度
Py_hash_t hash; /* 字符串哈希值 */
struct {
unsigned int interned:2;//是否interned机制开启
unsigned int kind:3; //字符类型,根据maxchar区分
unsigned int compact:1;//是否紧凑,实际数据域对象头是否分离
unsigned int ascii:1;//是否为纯ASCII
unsigned int ready:1;//针对传统字符串,使用ready函数复制到data块中
unsigned int :24;//保留字段
} state;//Unicode对象标志位
wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject;
PyASCIIObject内存结构,是纯ASCII字符串通过PyUnicode_New函数申请的。申请时state.ascii和state.compact赋值为1,数据紧跟在头部结构后面,叫做紧凑型。
我们以纯ASCII字符串“hua”,看一下它的底层数据结构

纯ASCII字符串底层存储结构PyASCIIObject
从这个结构可以看出,Unicode字符串应该是可以变长的,但是实际没有使用可变长的PyVarObject头,而是使用了不可变长PyObject头,又增加了length这个字段。PyObject_VAR_HEAD用于描述每个元素大小都一样的变长对象,元素的大小由ob_size字段描述;而Unicode字符串对象,每个字符到底用多大的存储单元,与字符范围(maxchar)决定,底层做了特殊处理。
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding thterminating 0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;
当maxchar大于128小于256 时,虽然一个字节可以存储,此时为非ASCII,Unicode字符串对象由PyCompactUnicodeObject结构体保存。但是它的state中的字段ascii为0,举例图示一下“xiaohuaê”

非纯ASCII字符串底层存储结构PyCompactUnicodeObject
当maxchar大于256小于65536 时,Unicode字符串对象由PyCompactUnicodeObject结构体保存。但是它的state中的字段ascii为0,state中的字段kind为2举例图示一下“xiaohua”
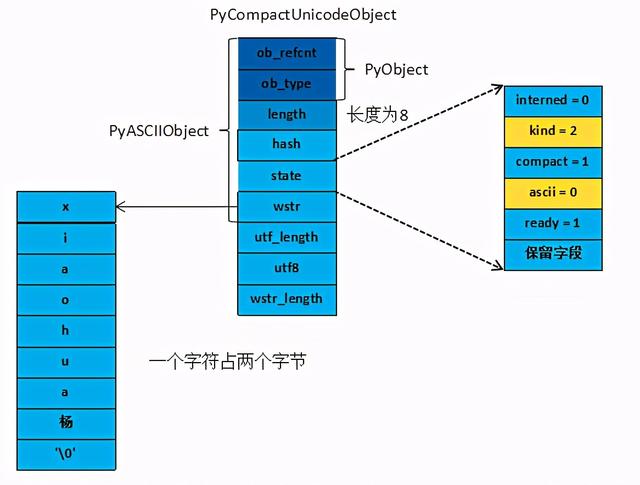
字符串中包含中文底层存储结构PyCompactUnicodeObject
当maxchar大于65536小于2^32 时,Unicode字符串对象由PyCompactUnicodeObject结构体保存。但是它的state中的字段ascii为0,state中的字段kind为4,举例图示一下“xiaohua+表情符号”
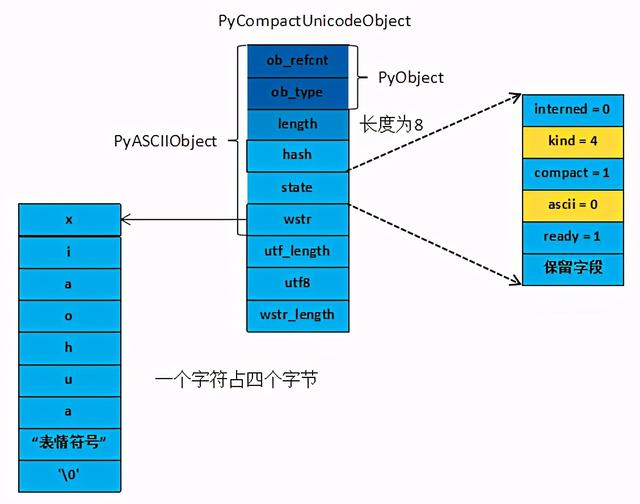
字符串中包含表情符号底层存储结构PyCompactUnicodeObject















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









