





这是学习笔记的第 2111 篇文章

在之前整理过一版MySQL的数据字典,整理了一圈,发现远比想象的复杂。
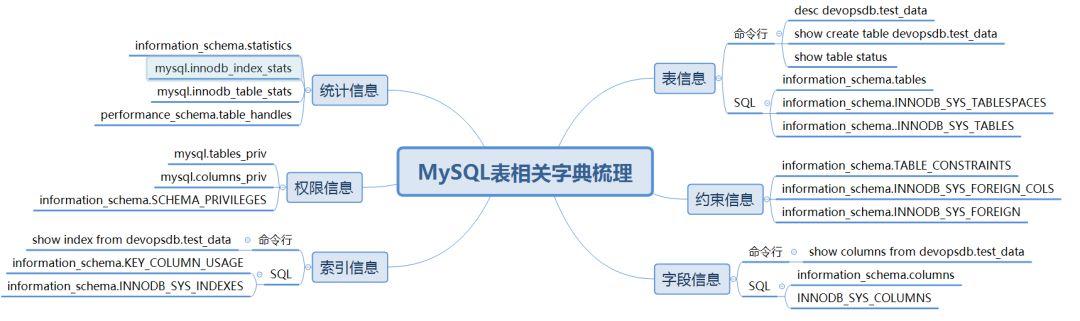
当然整理的过程不光是知识梳理的过程,也是转化为实践场景的一个过程,通过这样一个体系,对于整个MySQL对象生命周期管理有了较为深入的认识,这里我来抛砖引玉,来作为深入学习MySQL数据字典的一个入口,这个问题就是:如何较为准确的计算MySQL碎片情况?
我想碎片的情况在数据库中是很少有清晰的界定,不过它的的确确会带来副作用,通过修复碎片情况我们可以提高SQL的执行效率,同时能够释放大量的空间。
最近在思考中感悟到:我们所做的很多事情,难点主要都在于查找,比如我告诉你test库的表test_data存在大量碎片,需要修复一下,这个难度是完全可控的,我们可以很麻利的处理好,但是如果我告诉你需要收集下碎片情况,然后做一下改进,而不告诉你具体的情况,其实难度就会高几个层次。
我们这个场景主要会用到两个数据字典表:
information_schema.tables
information_schema.INNODB_SYS_TABLESPACES
我们依次来看一下两个数据字典的输出信息:
查询常规的数据字典tables得到的信息基本可以满足我们的大多数需求。
mysql> select *from information_schema.tables where table_name='tgp_redis_command'G
*************************** 1. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: tgp_db
TABLE_NAME: tgp_redis_command
TABLE_TYPE: BASE TABLE
ENGINE: InnoDB
VERSION: 10
ROW_FORMAT: Dynamic
TABLE_ROWS: 477103
AVG_ROW_LENGTH: 111
DATA_LENGTH: 53035008
MAX_DATA_LENGTH: 0
INDEX_LENGTH: 0
DATA_FREE: 5242880
AUTO_INCREMENT: 478096
CREATE_TIME: 2019-08-16 10:54:02
UPDATE_TIME: 2019-09-23 21:12:05
CHECK_TIME:
TABLE_COLLATION: utf8_general_ci
CHECKSUM:
CREATE_OPTIONS:
TABLE_COMMENT: redis命令执行记录表
1 row in set (0.00 sec)
通过tables字典我们可以得到通过逻辑计算出来的预估表大小,包括数据和索引的空间情况,还有平均行长度来作为校验。
但是在这里我们总是会感觉有些隔靴搔痒,因为我们通过计算得到了逻辑大小,但是我们还是无从得知物理文件的大小,如果逐个去通过du方式计算,这个成本是很高的,而且如果有很多的表,这种模式的效率和代价是不大合理的,所幸MySQL 5.7版本中的innodb_sys_tablespaces这个数据字典做了扩容,有了新的字段FILE_SIZE,可以完美的解决我们的疑虑,使用innodb_sys_tablespaces得到的结果如下:
mysql> select *from INNODB_SYS_TABLESPACES where name like 'tgp_db/tgp_redis_command'G
*************************** 1. row ***************************
SPACE: 818
NAME: tgp_db/tgp_redis_command
FLAG: 33
FILE_FORMAT: Barracuda
ROW_FORMAT: Dynamic
PAGE_SIZE: 16384
ZIP_PAGE_SIZE: 0
SPACE_TYPE: Single
FS_BLOCK_SIZE: 4096
FILE_SIZE: 62914560
ALLOCATED_SIZE: 62918656
1 row in set (0.00 sec)
比如常规来说我们要得到表tgp_redis_command的物理文件大小(即.ibd文件),可以通过INNODB_SYS_TABLESPACES 来查询得到,这是一个缓存中刷新得到的实时的值,远比我们通过du等方式计算要快捷方便许多。
可以做一个简单的计算,表里的数据量为:
mysql> select count(*) from tgp_redis_command;
+----------+
| count(*) |
+----------+
| 478093 |
+----------+
1 row in set (0.06 sec)
物理文件的大小,和innodb_sys_tablespaces的结果是完全一致的。
# ll *redis*
-rw-r----- 1 mysql mysql 9176 Aug 16 10:54 tgp_redis_command.frm
-rw-r----- 1 mysql mysql 62914560 Sep 23 21:14 tgp_redis_command.ibd
所以表的大小逻辑计算为data_length+index_length=53035008+0,大约是50M左右,而物理文件大小是60M左右,那么碎片率大约是(60-50)/60约等于16.7%
我们做一下数据的truncate操作,发现物理文件的大小很快收缩了。
mysql> select *from INNODB_SYS_TABLESPACES where name like 'tgp_db/tgp_redis_command'G
*************************** 1. row ***************************
SPACE: 818
NAME: tgp_db/tgp_redis_command
FLAG: 33
FILE_FORMAT: Barracuda
ROW_FORMAT: Dynamic
PAGE_SIZE: 16384
ZIP_PAGE_SIZE: 0
SPACE_TYPE: Single
FS_BLOCK_SIZE: 4096
FILE_SIZE: 98304
ALLOCATED_SIZE: 102400
1 row in set (0.00 sec)
mysql> select *from information_schema.tables where table_name='tgp_redis_command'G
*************************** 1. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: tgp_db
TABLE_NAME: tgp_redis_command
TABLE_TYPE: BASE TABLE
ENGINE: InnoDB
VERSION: 10
ROW_FORMAT: Dynamic
TABLE_ROWS: 0
AVG_ROW_LENGTH: 0
DATA_LENGTH: 16384
MAX_DATA_LENGTH: 0
INDEX_LENGTH: 0
DATA_FREE: 0
AUTO_INCREMENT: 1
CREATE_TIME: 2019-08-16 10:54:02
UPDATE_TIME: 2019-09-24 09:51:22
CHECK_TIME:
TABLE_COLLATION: utf8_general_ci
CHECKSUM:
CREATE_OPTIONS:
TABLE_COMMENT: redis命令执行记录表
1 row in set (0.00 sec)
[root@hb30-dba-mysql-tgp-124-34 tgp_db]# ll *redis*
-rw-r----- 1 mysql mysql 9176 Aug 16 10:54 tgp_redis_command.frm
-rw-r----- 1 mysql mysql 98304 Sep 24 09:55 tgp_redis_command.ibd
当然这种计算方式是不够完整的,而且不够清晰,我们可以写一个简单的SQL来做下统计,就是把那些需要修复的表列出来即可。
SQL如下:
SELECT
t.table_schema,
t.table_name,
t.table_rows,
t.data_length+
t.index_length data_size,
t.index_length index_size,
t.avg_row_length,
t.avg_row_length * t.table_rows logic_size,
s.FILE_SIZE,
truncate(s.FILE_SIZE/ (t.data_length+ t.index_length)*1.1*2 ,0)tab_frag
FROM
information_schema.tables t,
information_schema.INNODB_SYS_TABLESPACES s
WHERE
t.table_type = 'BASE TABLE'
and concat(t.table_schema,'/',t.table_name)=s.name
and t.table_schema not in ('sys','information_schema','mysql','test')
-- and t.table_schema in('tgp_db','test')
and s.FILE_SIZE >102400000
and (t.data_length+ t.index_length)*1.1*2 < s.FILE_SIZE
order by s.FILE_SIZE;
以如下的输出为例,我们可以看到整个碎片率极高,基本就是逻辑大小为100M,实际大小为500M,类似这种情况。

其中对于逻辑大小的计算做了一些取舍,默认在MySQL中变化的数据在10%以外是会重新去统计计算的,所以我们可以把基数调整的稍大一些为1.1,然后以这个为基线,如果碎片率超过了200%则计入统计结果中。
通过这种方式我们可以很快的分析出那些要具体修复的表,而整个性能的分析也可以更加清晰。
稍后,把它包装为一个批量异步任务,通过异步任务来得到尽可能完整的碎片表列表,然后集中去处理就好了。
个人新书 《MySQL DBA工作笔记》















 5558
5558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









