








 Spark中的OOM问题不外乎以下两种情况
Spark中的OOM问题不外乎以下两种情况
map执行中内存溢出
shuffle后内存溢出
execution内存是执行内存,文档中说join,aggregate都在这部分内存中执行,shuffle的数据也会先缓存在这个内存中,满了再写入磁盘,能够减少IO。其实map过程也是在这个内存中执行的。
storage内存是存储broadcast,cache,persist数据的地方。
other内存是程序执行时预留给自己的内存。
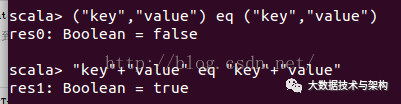 这个例子说明("key","value")和("key","value")在内存中是存在不同位置的,也就是存了两份,但是"key"+"value"虽然出现了两次,但是只存了一份,在同一个地址,这用到了JVM常量池的知识.于是乎,如果RDD中有大量的重复数据,或者Array中需要存大量重复数据的时候我们都可以将重复数据转化为String,能够有效的减少内存使用.
优化:
这一部分主要记录一下笔者觉得有优化性能作用的一些参数配置和一些代码优化技巧,在参数优化部分,如果笔者觉得默认值是最优的了,这里就不再记录。
代码优化技巧:
1.使用mapPartitions代替大部分map操作,或者连续使用的map操作:
这里需要稍微讲一下RDD和DataFrame的区别。
RDD强调的是不可变对象,每个RDD都是不可变的,当调用RDD的map类型操作的时候,都是产生一个新的对象,这就导致了一个问题,如果对一个RDD调用大量的map类型操作的话,每个map操作会产生一个到多个RDD对象,这虽然不一定会导致内存溢出,但是会产生大量的中间数据,增加了gc操作。
另外RDD在调用action操作的时候,会出发Stage的划分,但是在每个Stage内部可优化的部分是不会进行优化的,例如rdd.map(_+1).map(_+1),这个操作在数值型RDD中是等价于rdd.map(_+2)的,但是RDD内部不会对这个过程进行优化。
DataFrame则不同,DataFrame由于有类型信息所以是可变的,并且在可以使用sql的程序中,都有除了解释器外,都会有一个sql优化器,DataFrame也不例外,有一个优化器Catalyst,具体介绍看后面参考的文章。
上面说到的这些RDD的弊端,有一部分就可以使用mapPartitions进行优化,mapPartitions可以同时替代rdd.map,rdd.filter,rdd.flatMap的作用,所以在长操作中,可以在mapPartitons中将RDD大量的操作写在一起,避免产生大量的中间rdd对象,另外是mapPartitions在一个partition中可以复用可变类型,这也能够避免频繁的创建新对象。
使用mapPartitions的弊端就是牺牲了代码的易读性。
2.broadcast join和普通join:
在大数据分布式系统中,大量数据的移动对性能的影响也是巨大的。
基于这个思想,在两个RDD进行join操作的时候,如果其中一个RDD相对小很多,可以将小的RDD进行collect操作然后设置为broadcast变量,这样做之后,另一个RDD就可以使用map操作进行join,这样能够有效的减少相对大很多的那个RDD的数据移动。
3.先filter在join:
这个就是谓词下推,这个很显然,filter之后再join,shuffle的数据量会减少,这里提一点是spark-sql的优化器已经对这部分有优化了,不需要用户显示的操作,个人实现rdd的计算的时候需要注意这个。
4.combineByKey的使用:
这个操作在Map-Reduce中也有,这里举个例子:rdd.groupByKey().mapValue(_.sum)比rdd.reduceByKey的效率低,原因如下两幅图所示:
这个例子说明("key","value")和("key","value")在内存中是存在不同位置的,也就是存了两份,但是"key"+"value"虽然出现了两次,但是只存了一份,在同一个地址,这用到了JVM常量池的知识.于是乎,如果RDD中有大量的重复数据,或者Array中需要存大量重复数据的时候我们都可以将重复数据转化为String,能够有效的减少内存使用.
优化:
这一部分主要记录一下笔者觉得有优化性能作用的一些参数配置和一些代码优化技巧,在参数优化部分,如果笔者觉得默认值是最优的了,这里就不再记录。
代码优化技巧:
1.使用mapPartitions代替大部分map操作,或者连续使用的map操作:
这里需要稍微讲一下RDD和DataFrame的区别。
RDD强调的是不可变对象,每个RDD都是不可变的,当调用RDD的map类型操作的时候,都是产生一个新的对象,这就导致了一个问题,如果对一个RDD调用大量的map类型操作的话,每个map操作会产生一个到多个RDD对象,这虽然不一定会导致内存溢出,但是会产生大量的中间数据,增加了gc操作。
另外RDD在调用action操作的时候,会出发Stage的划分,但是在每个Stage内部可优化的部分是不会进行优化的,例如rdd.map(_+1).map(_+1),这个操作在数值型RDD中是等价于rdd.map(_+2)的,但是RDD内部不会对这个过程进行优化。
DataFrame则不同,DataFrame由于有类型信息所以是可变的,并且在可以使用sql的程序中,都有除了解释器外,都会有一个sql优化器,DataFrame也不例外,有一个优化器Catalyst,具体介绍看后面参考的文章。
上面说到的这些RDD的弊端,有一部分就可以使用mapPartitions进行优化,mapPartitions可以同时替代rdd.map,rdd.filter,rdd.flatMap的作用,所以在长操作中,可以在mapPartitons中将RDD大量的操作写在一起,避免产生大量的中间rdd对象,另外是mapPartitions在一个partition中可以复用可变类型,这也能够避免频繁的创建新对象。
使用mapPartitions的弊端就是牺牲了代码的易读性。
2.broadcast join和普通join:
在大数据分布式系统中,大量数据的移动对性能的影响也是巨大的。
基于这个思想,在两个RDD进行join操作的时候,如果其中一个RDD相对小很多,可以将小的RDD进行collect操作然后设置为broadcast变量,这样做之后,另一个RDD就可以使用map操作进行join,这样能够有效的减少相对大很多的那个RDD的数据移动。
3.先filter在join:
这个就是谓词下推,这个很显然,filter之后再join,shuffle的数据量会减少,这里提一点是spark-sql的优化器已经对这部分有优化了,不需要用户显示的操作,个人实现rdd的计算的时候需要注意这个。
4.combineByKey的使用:
这个操作在Map-Reduce中也有,这里举个例子:rdd.groupByKey().mapValue(_.sum)比rdd.reduceByKey的效率低,原因如下两幅图所示:
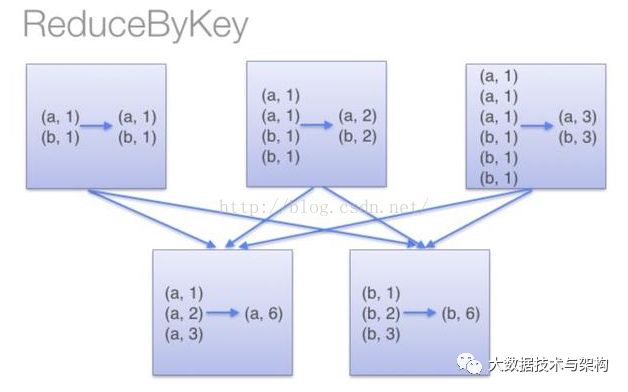 上下两幅图的区别就是上面那幅有combineByKey的过程减少了shuffle的数据量,下面的没有。combineByKey是key-value型rdd自带的API,可以直接使用。
5. 在内存不足的使用,使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache():
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
6.在spark使用hbase的时候,spark和hbase搭建在同一个集群:
在spark结合hbase的使用中,spark和hbase最好搭建在同一个集群上上,或者spark的集群节点能够覆盖hbase的所有节点。hbase中的数据存储在HFile中,通常单个HFile都会比较大,另外Spark在读取Hbase的数据的时候,不是按照一个HFile对应一个RDD的分区,而是一个region对应一个RDD分区。所以在Spark读取Hbase的数据时,通常单个RDD都会比较大,如果不是搭建在同一个集群,数据移动会耗费很多的时间。
参数优化部分:
7. spark.driver.memory (default 1g):
这个参数用来设置Driver的内存。在Spark程序中,SparkContext,DAGScheduler都是运行在Driver端的。对应rdd的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这个时候就需要调大Driver的内存。
8. spark.rdd.compress (default false) :
这个参数在内存吃紧的时候,又需要persist数据有良好的性能,就可以设置这个参数为true,这样在使用persist(StorageLevel.MEMORY_ONLY_SER)的时候,就能够压缩内存中的rdd数据。减少内存消耗,就是在使用的时候会占用CPU的解压时间。
9. spark.serializer (default org.apache.spark.serializer.JavaSerializer )
建议设置为 org.apache.spark.serializer.KryoSerializer,因为KryoSerializer比JavaSerializer快,但是有可能会有些Object会序列化失败,这个时候就需要显示的对序列化失败的类进行KryoSerializer的注册,这个时候要配置spark.kryo.registrator参数或者使用参照如下代码:
上下两幅图的区别就是上面那幅有combineByKey的过程减少了shuffle的数据量,下面的没有。combineByKey是key-value型rdd自带的API,可以直接使用。
5. 在内存不足的使用,使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache():
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
6.在spark使用hbase的时候,spark和hbase搭建在同一个集群:
在spark结合hbase的使用中,spark和hbase最好搭建在同一个集群上上,或者spark的集群节点能够覆盖hbase的所有节点。hbase中的数据存储在HFile中,通常单个HFile都会比较大,另外Spark在读取Hbase的数据的时候,不是按照一个HFile对应一个RDD的分区,而是一个region对应一个RDD分区。所以在Spark读取Hbase的数据时,通常单个RDD都会比较大,如果不是搭建在同一个集群,数据移动会耗费很多的时间。
参数优化部分:
7. spark.driver.memory (default 1g):
这个参数用来设置Driver的内存。在Spark程序中,SparkContext,DAGScheduler都是运行在Driver端的。对应rdd的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这个时候就需要调大Driver的内存。
8. spark.rdd.compress (default false) :
这个参数在内存吃紧的时候,又需要persist数据有良好的性能,就可以设置这个参数为true,这样在使用persist(StorageLevel.MEMORY_ONLY_SER)的时候,就能够压缩内存中的rdd数据。减少内存消耗,就是在使用的时候会占用CPU的解压时间。
9. spark.serializer (default org.apache.spark.serializer.JavaSerializer )
建议设置为 org.apache.spark.serializer.KryoSerializer,因为KryoSerializer比JavaSerializer快,但是有可能会有些Object会序列化失败,这个时候就需要显示的对序列化失败的类进行KryoSerializer的注册,这个时候要配置spark.kryo.registrator参数或者使用参照如下代码:
valconf=newSparkConf().setMaster(...).setAppName(...)conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2]))valsc =newSparkContext(conf)

文章不错?点个【在看】吧! ?















 4242
4242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









