







Abstract
一个用来组织特定领域概念,及其别称和关系的领域术语库,对于知识获取和软件开发是必要的。现有的方法采用语言启发法 & 基于词频的统计方法从软件文档中识别特定领域的词汇,但准确率通常很低。本论文中,我们提出一种由源代码和软件文档自动化构建领域术语库的学习方法。该方法使用一组从代码标识符和自然语言概念定义中识别出来的高质量种子词汇,来训练一个特定领域预测模型,根据提及特定领域概念的句子的词汇和语义上下文,来识别领域术语。然后,将相同概念的别称进行合并,为每一个概念选择一组解释性语句,并在这些概念间建立“is a”,“has a”和“related to”的关系。我们将此方法应用到深度学习领域和Hadoop领域,分别获得了5,382个概念和2,069个概念,16,962个关系和6,815个关系。我们的评估验证了所抽取领域术语库的准确性,以及它对从不同项目的不同文档中获取、融合知识的有用性。1 Introduction
软件项目通常属于特定领域,例如,TensorFlow和PyTorch是深度学习库,Hadoop和HBase是分布式数据库系统。每个领域都有一组业务或技术概念,这些概念在领域的软件项目源代码和文档中经常被提到。它们会以全称或者别称(缩写和其他形态的变体)的形式被提及。许多概念是相互关联的,如hypernym-hyponym、whole-part等。组织特定领域的概念,以及它们在领域术语库中的别称和关系,对知识获取和软件开发是至关重要的。此外,基于领域术语库,我们可以从语义上来链接来自不同工件的元素(例如,类/方法、API、问答帖子、文档片段等)。这些链接可以帮助许多软件工程任务,如开发人员问题回答、可追溯性恢复和维护、特征定位、API推荐和代码搜索。由于领域的复杂性和快速发展,手工构建一个综合领域术语库往往是费力而昂贵的,因此从不同种类的软件工件中自动提取词汇术语或领域概念的研究被提倡。一些研究从需求文档中提取词汇术语。这些方法使用语言启发法或基于词频的统计方法,从名词短语中识别领域特定词汇,通常准确性很低。并且,这些方法只能聚类相关术语,并不能识别别称,及其与特定概念之间的关系。一些研究从Stack Overflow这类问答网站上提取领域概念,但对领域相关性的估计依赖于Stack Overflow上的标签和人工标记。本文中,我们的目标是从同一领域软件项目的源代码和文档中,以一种无监督的方式提取特定领域的概念,以及它们的别称和关系。这项任务的挑战体现在几个方面:首先,领域概念和它们之间关系的知识通常被分散在不同的文档,甚至是不同的项目中;其次,相同的概念通常在不同的地方,以不同的别称被提及;最后,概念和特定领域的相关性不能由词汇启发法或术语频率被可靠确定。在这项工作中,我们提出一种由源代码和软件文档自动化构造领域术语表的学习方法。我们方法的基本思想是双重的:首先,文档中特定领域的概念经常作为源代码中的标识符使用,概念之间的关系可以从对应代码元素间的结构关系中推断出来。其次,使用提及从代码标识符和自然语言概念定义中识别出的高质量种子术语的句子作为训练数据,我们可以得到一个特定领域的预测模型,从而根据提到特定领域概念的句子的词汇和语义上下文,去识别更多的领域术语。基于这两种思想,我们的方法首先从目标领域不同项目的源代码和文档中提取一组候选术语,然后将相同概念的别名合并为它们的规范名称。在此之后,我们的方法为每个概念选择一组解释性句子,进一步识别概念之间的“is a”(hypernym-hyponym)、“has a”(whole-part) 和 “related to”关系。我们在两个技术领域(deep learning 和 Hadoop)实现了该方法并开展了实证研究。研究得出了以下结论:一、我们的方法在基于文档的领域术语库提取方面要优于最新方法;二、领域术语库提取为从不同项目的不同文档中领域知识的融合提供了一种有效的方法。三、提取的领域术语库能够对WikiPedia等通用知识库进行补充。四、提取的领域术语表可以帮助开发人员更有效地从文档中获取所需知识。本文的主要贡献如下:
1. 我们提出一种由源代码和文档自动化构建领域术语库的学习方法
2. 我们将此方法应用于 deep learning 领域和 Hadoop 领域,分别获得了5,382个概念和2,069个概念,16,962个关系和6,815个关系。
3. 我们评估了领域术语提取方法的有效性,以及所提取的领域词汇在知识融合和软件知识获取方面的有用性。
3 Approach
图1给出了方法的概述,它包括预处理、概念提取和关系/解释识别这三个阶段。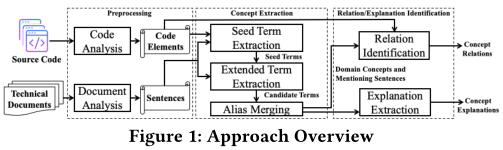
3.1 预处理
我们的实现包括Java和Python的代码分析器,它们分别基于javalang和Python的内建模块ast来实现。代码分析器从源代码中提取包、模块、类以及它们之间的各种关系。许多项目的技术文档都是可在线获取的网页,我们为此实现了一个基于Scrapy的爬虫来获取文档。我们使用BeautifulSoup来解析所获得的web页面,然后通过处理不同类型的特殊HTML元素来清理所获得的网页内容,复原被“p ”、“li ”等标签破坏的句子。 最后,我们从内容中提取出纯文本,并根据标点符号将文本分割成句子。3.2 种子术语提取
种子术语提取使用启发式方法自动识别一小组具有高置信度的术语。为了找到一组最优的启发式,我们尝试不同的启发式组合( eg. 提取文本中的全大写单词、代码中的局部变量/参数名作为种子术语),并根据结果进行调整。最后,我们选择了以下两个启发式规则,用于从源代码和文档中提取高质量术语。首字母缩略词在文档中以全称出现
B. [acronym] ([full name])
eg. “Feed forward neural networks are comprised of dense layers, while recurrent neural networks can include Graves LSTM (long short-term memory) layers.”
C. [acronym]:[full name]
eg. “Enumeration used to select the type of regression statistics to optimize on, with the various regression score functions - MSE: mean squared error -MAE: mean absolute error - RMSE: root mean squared error - RSE: relative squared error - CorrCoeff: correlation coefficient.”。
为了实现这一规则,首先我们将句子与上述三个模式相匹配,然后根据缩略词确定全称。例如,根据首字母缩写“RNN”,我们可以识别出括号前的由三个单词构成的短语“recurrent neural network”,作为其全称。对于每一个匹配的首字母缩略词,其本身和全称都被视作种子术语。包/类名出现在文档中
3.3 扩展术语提取
扩展术语抽取使用机器学习方法从句子中识别出更多的术语。它将术语识别看作一个序列标记任务,即预测一个观察序列对应的标签序列。有许多NLP问题可以通过序列标记来解决,例如词性标记(POS)、分块和命名实体识别(NER)等。针对这个任务,我们采用的标记方法是IOBES,它被广泛应用于序列标记任务中。 在IOBES模式中,“B”、“I”和“E”分别表示当前标记是一个术语的开始、中间 和结束; “S”(“Single”)表示当前标记本身构成一个术语; “O”(“Outside”)则表示普通标记。 例如,一个包含两个术语(即“recurrent neural network”和“RNN”)的句子的标记如下所示。
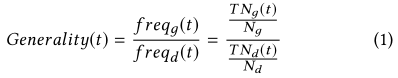
3.4 别称合并
这一步的目的在于从候选术语中识别相同概念的别称,并将它们合并在一起形成一个概念。这一步骤主要处理技术文档中广泛存在的两种概念别名,即形态同义词和缩写。首先对所有候选术语进行归类,然后识别并合并形态同义词,最后识别并合并缩写词。 3.4.1 形态同义词 的识别和合并技术文档中典型的形态同义词包括:1)仅在大小写或者单/复数形式上不同的单词或短语,如“Deeplearning4J” 和 “Deeplearning4j”,“RNN” 和 “RNNs”。2)拼写不同 & 拼写错误的单词或短语,例如“Deeplearning4J”和“Deeplearnning4J”。3)以不同方式使用连字符的单词或短语,例如“t-SNE” 和 “tSNE”。
第一类形态的同义词可以通过词形还原来直接识别。 对于另外两种类型,我们使用编辑距离来确定两个单词或短语是否为形态同义词。我们使用Damerau-Levenshtein距离(DL距离)来度量两个单词或短语的相似性。DL距离是将一个单词或短语转换为另一个单词或短语所需的最小操作数(插入、删除或替换单个字符,或转置两个相邻字符)。考虑到不同长度的单词或短语,我们计算两个单词或两个短语(s1和s2)之间的相对距离RDistance(s1,s2),如下式所示。其中,Distance(s1,s2)是s1和s2之间的DL距离,length(s)是一个字符串s的长度。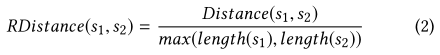
3.5 关系抽取
所提取领 域概念之间的关系往往隐藏在文档的特定句型,以及代码元素的结构化关系中。 通过对文档和代码的分析,我们识别了被抽取概念间的"is a",“has a”和“related to”关系。 对于两个概念 C1 和 C2 ,我们从以下几个方面来确定它们之间的"is a",“has a”和“related to”关系。 首先根据Hearst Patterns,从提及C1 和 C2的句子中识别 "is a" 关系。 该模式广泛用于从不受限制的文本中自动获取上下位词汇关系。 我们当前实现所用的模式如表一所示,其中C1和C2可以是对应概念的任何别称。 其次,根据包和类之间的结 构化关系,识别“is a”和“has a”关系。 对于两个名称分别是C1和C2别称的包或类E1和E2: 1)如果E1包含E2,或者将E2作为一个属性聚合,在C1到C2间加一个“has a”关系。 2)如果E1继承E2,在C1到C2间加一个“is a”关系。 最后,基于概念别称间的前后缀关系,识别“is a”和“has a”关系。 1)如果C1的一个别称是C2的一个别称的前缀,在C1到C2间加一个“has a”关系。 2)如果C1的一个别称是C2的一个别称的后缀,在C2到C1间加一个“is a”关系。为了提供更丰富的概念关系,我们进一步识别所提取概念间的“related to”关系,这种关系要弱于"is a"和“has a”关系。“related to”关系的识别基于两个概念之间的相似度:如果两个概念间的相似度高于预定义的阈值,则在它们之间添加一条双向的“related to”关系。上下文相似度的计算基于以下等式,它结合了两个概念的词汇相似度以及上下文相似度。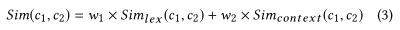
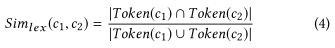
{SGD, is, a, optimizer}提取自句子“torch.optim: Contains optimizers such as SGD.”,基于Hearst Patterns。
{NN, has a, Activation Layer} 基于包之间的包含关系被提取,例如 org.deeplearning4j.nn 和 org.deeplearning4j.nn.layers.ActivationLayer。
{RNN, has a, RNN Layer}和{recurrent neural network, is a, neural network}是基于概念名称间的前后缀关系被提取的。
{L1, related to, Regularizer}是基于概念的上下文相似度被提取的。
3.6 解释抽取
解释抽取的目的是为每个领域概念选择一组有助于用户理解该概念的句子。这些句子通常可以分为以下几类。概念定义:为概念和相关技术提供定义,例如分类法、含义解释;
技术评论:对某一概念和相关技术的特点进行评论,如优点和缺点,与其他技术的比较;
用法指导:建议使用概念和相关技术的正确方法,例如适用场景、相关设置的指导、常见问题解决方案。
RQ1: 所提取的领域概念、关系和解释有多精确?在领域词汇表提取方面,该方法是否优于现有方法?
RQ2: 所提取的领域词汇表如何融合来自不同项目和文档的知识?提取的概念如何对WIkiPedia等通用知识库进行补充?
RQ3: 提取的领域词汇表是否能够帮助开发人员获得所需知识?
4.2 基本结果
对于深度学习领域,我们识别出471个种子术语,在扩展术语提取中识别出6,645个附加术语。这些候选术语在别称合并后,最终会被转变为5,382个概念。这些概念总共有7,116个别称,每个概念有1到22个别称(平均1.32个)。从这些概念中提取16,962个关系,其中包括119个 “is a” 关系,709个 “has a” 关系,16,134个 “related to” 关系,每个概念有1到115个关系(平均6.30个)。为这些概念提取了1,689个解释句子,每个概念对应0到69个句子(平均0.31个)。对于Hadoop领域,我们识别出了202个种子术语,在扩展术语提取中识别出2,537个附加术语。这些候选术语经过别称合并后,最终转化为2,069个概念。这些概念总共有2,739个别称,每个概念有1到12个别称(平均1.32个)。为这些概念提取了6815个关系,其中135个“is a”关系,479个“has a”关系,6201个“related to”关系,每个概念有1到150个关系(平均6.59)。为这些概念提取1,311个解释句子,每个概念对应0到68个句子(平均0.63个)。图2显示了为深度学习领域提取的概念和关系的片段。这个片段解释了一组深度学习概念之间的关系,如NN、RNN、CNN、LSTM、LSTM Cell、RNN Cell、Seq2Seq。表2显示了部分概念的别称和解释性句子。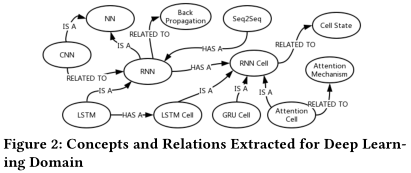

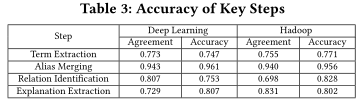
4.3 准确率(RQ1)
如表3所示,我们的方法在术语提取、别称合并、关系识别、解释提取等方面都取得了较高的准确率。 对于术语提取,错误提取的术语包括:1)非概念短语,如“network learn”(deep learning) 和 “table exists(Hadoop)”;
2)与领域无关的概念,如“Google Cloud”(deep learning) 和 “Webapp”(Hadoop);
3)带有无意义限定符的概念,如“second tensors”(deep learning),“given rows”(Hadoop)。
对于别称合并,错误识别的别称关系包括:
1)相似但含义不同的术语,如“opencl”和“opencv”(deep learning);
2)错误合并的缩写和全称,如“RR”和“random row”(Hadoop,正确的全称是“Record Reader”)
对于关系识别,错误提取的概念关系包括:
1)错误概念间的错误关系,如{contrib, has a, Early Stopping} (deep learning,“contrib”不是一个术语)
2)词汇相似术语间错误的“related to”关系,如{specified nodes, related to, specified metric} (Hadoop, 这两个术语在词法上相似但并不相关)
对于解释提取,错误提取的句子不能提供有用的解释和指导,如对于“reparameterized sample”的句子“The reparameterized sample therefore becomes differentiable.”。
4.4 知识融合(RQ2)
我们的方法收集了来自不同项目和文档的术语、概念和解释。为了评估我们的方法是如何融合来自不同项目和文档的,我们分析了在不同项目和文件中提取的术语、概念以及解释的分布。表5统计了不同项目中的知识融合情况,即不同项目的不同文档中包含了多少术语、概念和解释性句子。对于深度学习领域,如果一个人阅读某个具体项目的单个文档,他最多可以学到58%的术语、53.7%的概念和29.5%的解释性句子;对于Hadoop领域,相应的比率是45.7%,40.9%和40.6%。从分析中可以看出,要融合来自不同项目的不同文档中的知识,对特定领域的概念就必须有个全面的理解。例如,缩写“GAN”出现在Tensorflow的文档中,但其全称“Generative Adversarial Networks” 只能在 Deeplearning4j中找到,其解释只能在Pytorch中找到。

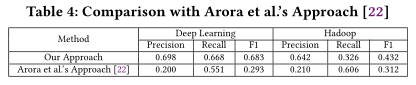
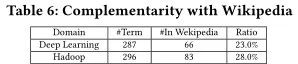
我们进一步分析了在每个领域中抽取的384个词汇与维基百科的互补性,以此来对术语抽取进行评估。对于每一个术语,我们都要手动去维基百科中检查,看它是否包含相同的含义。表6显示了互补性分析的结果,包括确认的词汇数量、维基百科中包含的词汇词汇数量和比例。从表中可以看出,我们所提取的,两个领域的术语分别只有23.0%、28.0%包含在维基百科中,与维基百科的互补性很强。维基百科包含了一些特定领域的术语,比如深度学习领域的“RNN”和“LSTM”,但是漏掉了更多特定领域的术语。例如,我们的方法将“computation graph”定义为深度学习领域的一个术语并提供了有用的解释,但它并没有包含在维基百科中。因此,我们的方法提取的概念、关系和解释能够很好地补充维基百科等通用知识库。
4.5 有用性(RQ2)
我们设计了一个实验来研究所提取的领域词汇表是否可以帮助回答实际开发人员的查询。对于一个查询,我们使用一个文档搜索引擎来搜索目标领域的文档语料库,然后使用基于所提取的领域词汇表的查询扩展再次执行文档搜索,并比较查询扩展前后的性能。
我们从100个最高投票数的Stack Overflow上的问题中选择12个,标签为“deep learning”或“Hadoop”的问题。这些问题与领域概念相关,并且可以由文档来回答。所选择的句子如表7所示,其中Q1-Q8与deep learning相关,Q9-Q12与Hadoop相关。对于每个问题,将其标题作为查询,并计算查询结构的三个指标:准确度(P),表示相关句子在排名前10的句子中所占的比例;平均精度(AP),所有相关结果检索后得到的精度分数的平均值。排名倒数,第一个正确结果位置的倒数。

表8给出了查询扩展的评价结果,比较累每个问题查询拓展前后的性能。可以看出,在领域词汇表的帮助之下,查询扩展极大地提高了深度学习和Hadoop领域的文档搜索表现。
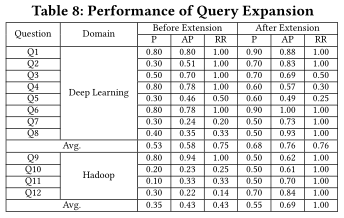
在问题Q2、Q7、Q8、Q10、Q11、Q12上,查询扩展表现得很好。我们可以看到,这些查询与概念的理解非常相关。相反,查询扩展在Q3、Q9上的表现不太有效。这两种查询都要求使用对应软件库、系统的具体技术解决方案。造成这种差异的一个原因可能是,具体的技术解决方案与特定项目和基本技术相关,而不是整个领域和高层概念。这促使我们考虑将领域词汇表与更通用的背景知识库集成起来,为软件知识的获取提供更好的支持。
5 结论
本文中,我们提出了一种由源代码和软件文档自动化构造领域术语库的学习方法。我们在deep learning领域和Hadoop领域进行了实证研究,研究证实了所提取领域术语的准确性,以及它对获取和融合不同项目的不同文档中知识的有用性。未来工作中,我们计划改进该方法,细化提取的过程,并与通用知识图谱集成,将构造的领域术语应用到更多的软件工程任务。














 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









