





上一篇在说redis的bit位操作时候,有一个同学在评论区问到如果mysql有一个g的数据,全部加载到redis需要多大的内存?本文就来一起探讨一下redis中数据是如何存储的,使用内存又是如何计算的,力求讲清楚以下几点内容:
- 从源码看redis的字典
- redis写入一个key,内存增加了多少?
- 使用redis-benchmark压测看redis内存变化,掌握预估内存的办法
本文基于如下环境:
操作系统:Mac OS
版本:Redis 5.0.7 (00000000/0) 64 bit
运行模式:Running in standalone mode
文章内容较长,建议大家收藏后持续阅读~点击右上方关注,阅读更多技术文章!
redis字典
说起redis的数据结构,字典是最底层的数据结构了。《redis设计与实现》一书中对字典的定义:
字典,又称为符号表(Symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
redis构建了自己的字典实现,redis中的数据库就是使用字典来作为底层实现的,redis中的哈希键(Hash)也使用字典来实现的。
而redis的字典又是使用哈希表来作为底层实现的。哈希算法采用的是MurmurHash2算法,一个优秀的哈希算法有如下要求:
- 雪崩效应(任何输入的微小变化都会导致巨大的差异)
- 低碰撞率
- 高性能
关于Murmurhash算法详情以及实际应用可阅读我的文章:MurmurHash算法及应用场景
在安装的redis/src文件夹下可以看到有很多后缀名为.h、.c、.o的文件,其中.h代表的是.c文件中用到的变量、数组、函数的声明,.c文件是.h文件中声明的变量、数组、函数具体的定义,而.o就是编译后的汇编文件。
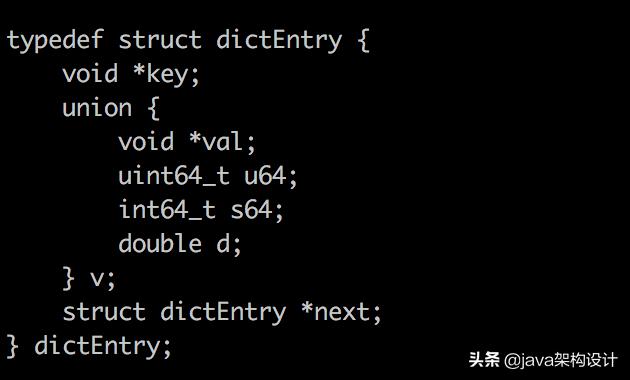
大家可以看到有dict.h文件,这个文件里面即定义了字典的数据结构,我们打开源码可以看到如下四个C语言的结构体(struct):
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next;} dictEntry;typedef struct dictType { uint64_t (*hashFunction)(const void *key); void *(*keyDup)(void *privdata, const void *key); void *(*valDup)(void *privdata, const void *obj); int (*keyCompare)(void *privdata, const void *key1, const void *key2); void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj);} dictType;typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used;} dictht;typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */} dict;用一张图来表述他们之间的关系如下:
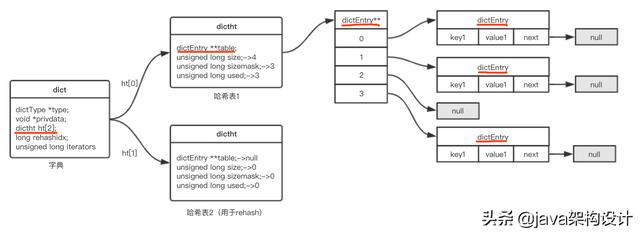
当我们执行一条如下语句的时候:
set testKey testValue如果是首次redis写入,会创建一个dict字典对象,字典对象的数据如下:
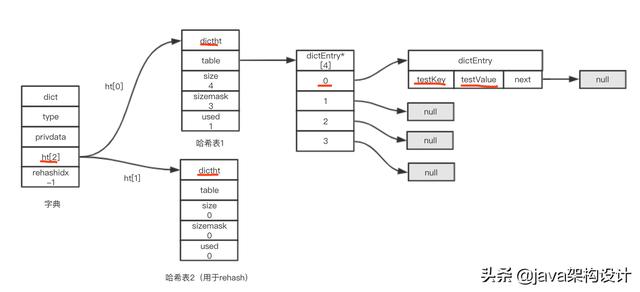
当然如果你写入的不是字符串类型的数据类型,而是List、Hash、Set、ZSet四种数据,也和上图的数据结构一样,只是dictEntry里面的值对象*val指针会指向不同的对象,不同的对象会有不同的数据结构,强烈推荐大家阅读《redis设计与实现》这本书,深读此书将会彻底搞清楚redis。
redis内存计算
上节从redis的字典说了redis的底层数据结构是如何保存我们写入的key的,那么当我们执行命令写入key到redis中,redis的内存具体是如何分配的呢?我们一起来实验一下:
首先执行FLUSHALL命令来清空我们的redis,保证没有其他key干扰,然后执行:
src/redis-cli info | grep mem获取redis初始内存信息:
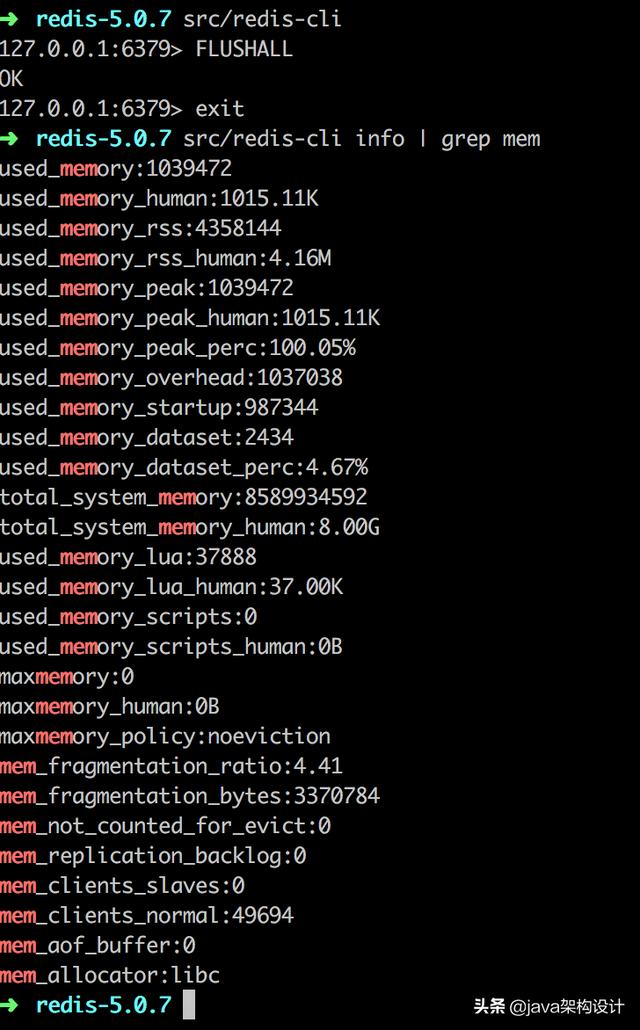
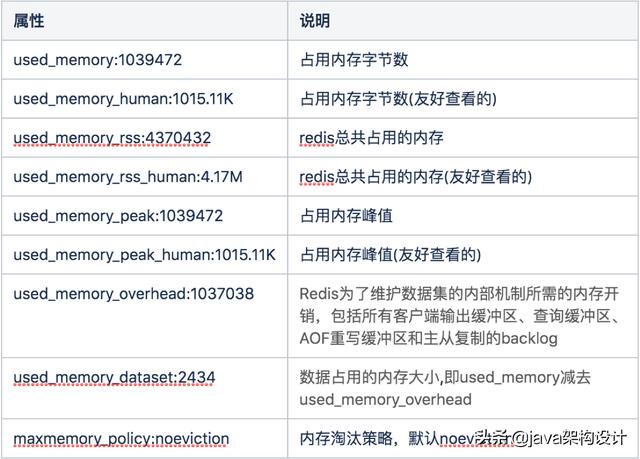
关键属性说明如下(更多属性说明请查阅redis官网):
redis初始占用内存:1039472字节,当我们执行:
set testKey testValue再查看内存变化为:
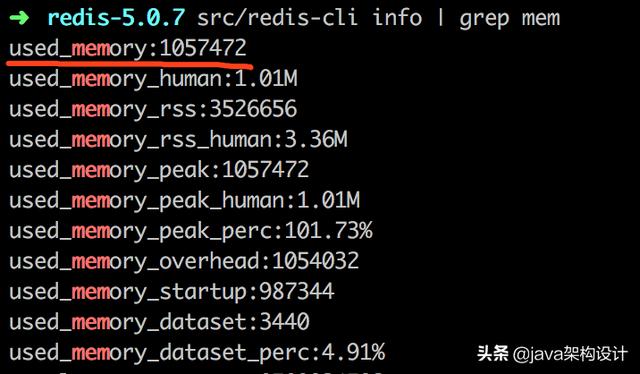
也就是说上面的语句执行后吃了redis内存为:1057472-1039472=18000b=17.58K,那是不是代表上面的执行吃了18K的内存呢?
我们再写入一个key:
set testKey1 testValue1通过上文对字典的描述可以知道testKey1在redis中的存储应该如下图所示:

查看内存变化为:
used_memory:1057552
才发现吃了80字节的内存。
所以我们可以知道的是redis启动之后需要占用一部分内存,这部分内存1039472字节用于redis服务的运行以及初始化一些数据。另外首次写入redis的key之后,需要构造上文所说的redis字典结构,因此需要占用一些内存。
我们需要知道的是当我们写入一个key的时候占用的内存到底是多少,由于我们写的值都没有超过44个字节,所以采用EMBSTR数据结构存储。所以我们可以查看object.c源码里面是如何创建对象的:
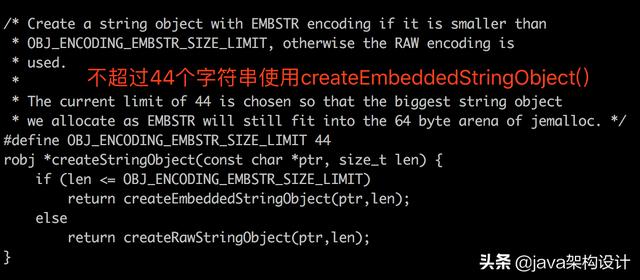
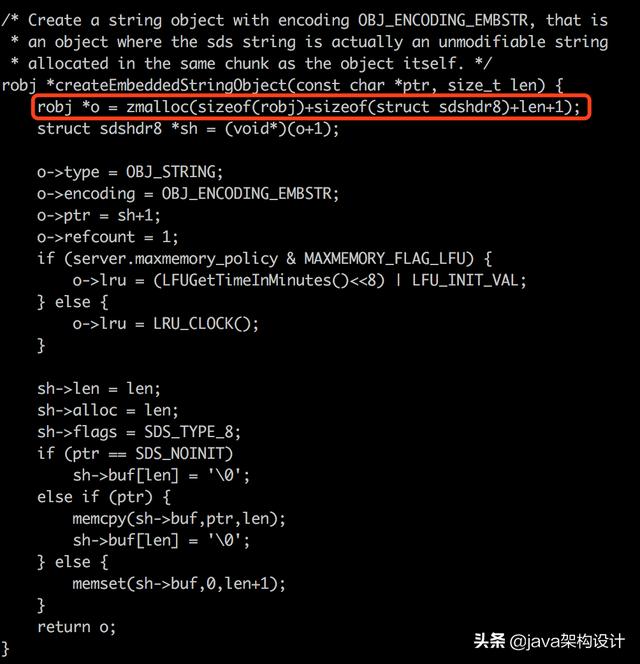
分配内存的代码:
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);可以看到redis为我们分配了:
sizeof(robj)+sizeof(struct sdshdr8)+len+1这么大的内存,其中的robj代表的是redisObject,查看server.h中关于redisObject对象的定义:

因此sizeof(robj) = 16字节。
sdshdr8即上图中的sdshdr中的头部3个字节。
因此testValue1这个采用EMBSTR编码的存储需要内存:16+3+10+1=30字节,redis内存分配器为其分配32字节。
我们再来计算testKey1占用的内存,testKey1存储的就是一个SDS简单动态对象,少了robj的内存占用,因此需要内存:3+8+1 = 12字节,redis分配器为其分配16字节。
总共需要内存为32+16=48字节,那为什么占用的是80字节呢?剩下的32字节谁吃了呢?大家不要忘记了dictEntry这个结构还有三个指针呢:
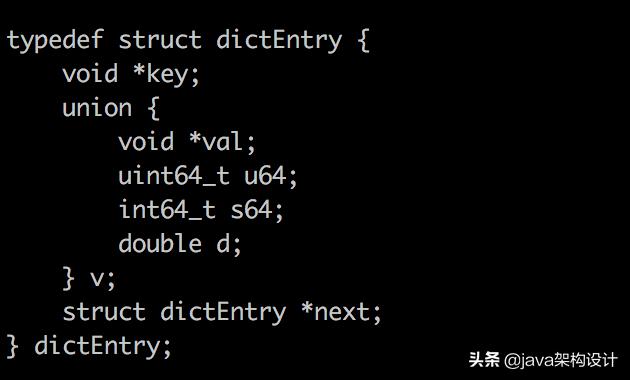
三个指针占用内存:3*8-24字节,jemalloc会为其分配32个字节。
至此,我们便能清晰的知道当我们执行一个字符串对象(字符串长度不超过44!)写入的时候,需要占用内存多少了。
即80-18(testKey1&testValue1) = 62的长度。但是我们需要知道这62个长度都吃在什么地方了。
上面说的是当写入String类型的数据且长度值不超过44的时候占用的内存计算方法。其他数据类型如List、Hash、Set、Zset大家可以参考我上面的方法和思路并查看相关redis源码以及redis技术资料即可得知。
redis-benchmark压测
src目录下redis-benchmark是redis自带的压测工具,压测语法格式:
redis-benchmark [option] [option value]option可选参数如下:
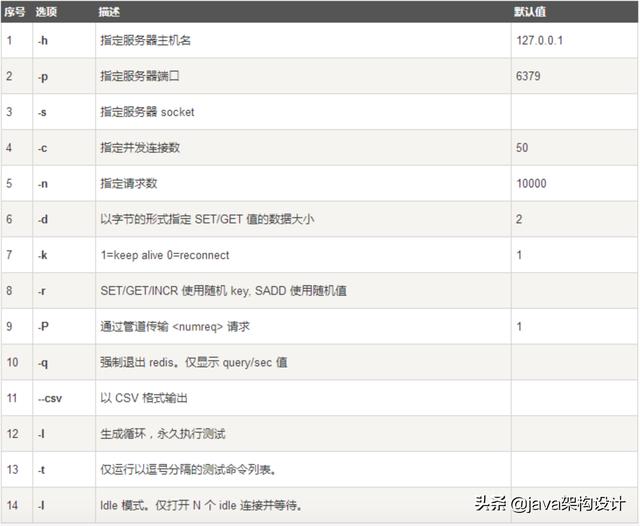
执行压测语句:
src/redis-benchmark -p 6379 -t set -c 100 -n 1000000 -r 1000000输出压测结果:
➜ redis-5.0.7 src/redis-benchmark -p 6379 -t set -c 100 -n 1000000 -r 1000000====== SET ====== 1000000 requests completed in 20.04 seconds 100 parallel clients 3 bytes payload keep alive: 144.04% <= 1 milliseconds96.99% <= 2 milliseconds98.73% <= 3 milliseconds99.29% <= 4 milliseconds99.53% <= 5 milliseconds99.68% <= 6 milliseconds99.76% <= 7 milliseconds99.81% <= 8 milliseconds99.85% <= 9 milliseconds99.90% <= 10 milliseconds99.92% <= 11 milliseconds99.93% <= 12 milliseconds99.94% <= 13 milliseconds99.95% <= 14 milliseconds99.96% <= 15 milliseconds99.96% <= 16 milliseconds99.96% <= 17 milliseconds99.97% <= 18 milliseconds99.97% <= 19 milliseconds99.97% <= 20 milliseconds99.97% <= 21 milliseconds99.98% <= 22 milliseconds99.98% <= 23 milliseconds99.98% <= 24 milliseconds99.98% <= 25 milliseconds99.98% <= 26 milliseconds99.98% <= 27 milliseconds99.98% <= 28 milliseconds99.98% <= 31 milliseconds99.98% <= 32 milliseconds99.98% <= 33 milliseconds99.99% <= 34 milliseconds99.99% <= 35 milliseconds99.99% <= 36 milliseconds99.99% <= 37 milliseconds99.99% <= 38 milliseconds100.00% <= 39 milliseconds100.00% <= 41 milliseconds100.00% <= 50 milliseconds100.00% <= 58 milliseconds100.00% <= 58 milliseconds49907.67 requests per second压测完毕后执行src/redis-cli info | grep mem命令查看内存占用情况:
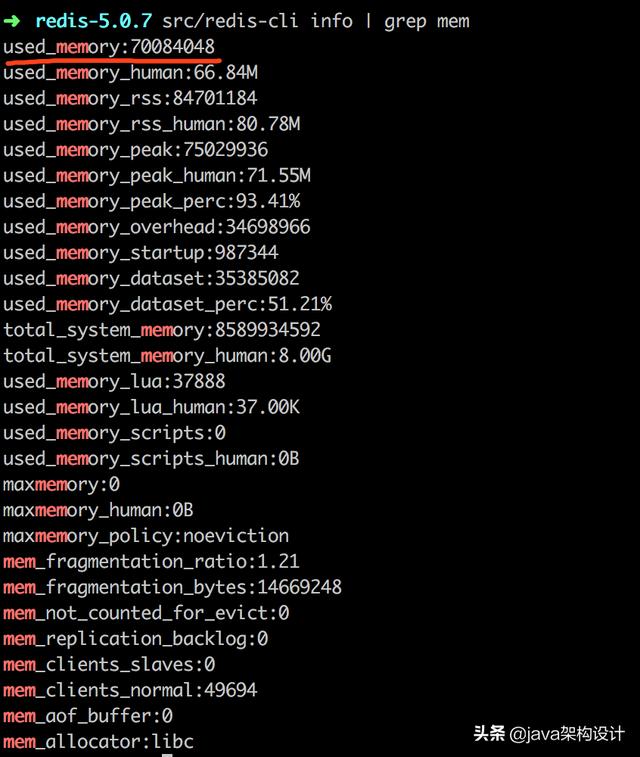
共占用内存:70084048-1039472=69044576字节=65.85M
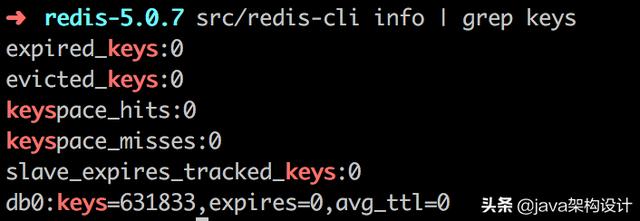
总共写入631833个key,每个key的内容格式如下:
set key:000000075890 xxx
即每个key占用内存为:32+32+32=96字节,共消耗:631833*96=57.85M,我们压测的info总共消耗65.85M,还差8M去哪里了呢?
还记得第一部分说的字典结构里面的ht[0]和ht[1]么?初始ht[0]为4,分配的内存就是4*8b=32b,当需要存储的数据超过4个的时候就会触发rehash动作,将ht[1]扩容为ht[0]的2倍,然后将h[0]里的数据全部rehash至ht[1],再互相交换一下,ht[1]变成ht[0],ht[0]变成ht[1]。那么当我们写入的631833个key将会产生rehash多少次呢?
realsize=4realsize=8realsize=16realsize=32realsize=64realsize=128realsize=256realsize=512realsize=1024realsize=2048realsize=4096realsize=8192realsize=16384realsize=32768realsize=65536realsize=131072realsize=262144realsize=524288realsize=1048576所以目前realsize是1048576,那么总共需要分配的内存就是1048576*8= 8388608,8388608/1024/1024=8MB,刚好和我们压测的结果对上了!
总结
以上就是redis关于内存分配的相关知识了。上面只是对redis的字符串类型的数据进行解说,通过对字符串类型的部分源码解读我们可以清楚的知道一个key的写入到redis需要多大的内存。其他的数据结构这里没有做详细说明,但其实思路是一致的。让我们再看一下下图dictEntry对象的定义,从字典开始,前面的都一致,只是dictEntry里面的*val指向不同而已。















 1160
1160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









