






上一小节总结了离散型随机变量,这个小节总结连续型随机变量。离散型随机变量的可能取值只有有限多个或是无限可数的(可以与自然数一一对应),连续型随机变量的可能取值则是一段连续的区域或是整个实数轴,是不可数的。最常见的一维连续型随机变量有三种:均匀分布,指数分布和正态分布。
数理统计与概率论及Python实现(1)——概率论中基本概念
数理统计与概率论及Python实现(2)——随机变量
数理统计与概率论及Python实现(3)——随机变量概述
数理统计与概率论及Python实现(4)—— 一维离散型随机变量及其Python实现
1. 均匀分布
均匀分布算是最简单的连续型概率分布。因为其概率密度是一个常数,不随随机变量X取值的变化而变化。
1.1 定义
如果连续型随机变量 X 具有如下的概率密度函数,则称 X 服从 [a,b] 上的均匀分布(uniform distribution),记作 X∼U(a,b) 或 X∼Unif(a,b)
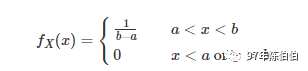
均匀分布具有等可能性,也就是说,服从 U(a,b) 上的均匀分布的随机变量 X 落入 (a,b) 中的任意子区间上的概率只与其区间长度有关,与区间所处的位置无关。
由于均匀分布的概率密度函数是一个常数,因此其累积分布函数是一条直线,即随着取值在定义域内的增加,累积分布函数值均匀增加。
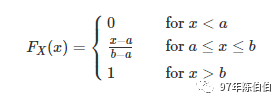
1.2 主要用途
设通过某站的汽车10分钟一辆,则乘客候车时间 X 在 [0,10] 上服从均匀分布;
某电台每个20分钟发一个信号,我们随手打开收音机,等待时间 X 在 [0,20] 上服从均匀分布;
随机投一根针与坐标纸上,它和坐标轴的夹角 X 在 [0,π] 上服从均匀分布。
1.3 Python实现
从定义可以看出来,定义一个均匀分布需要两个参数,定义域区间的起点 a 和终点 b,但是在Python中是 location 和 scale, 分别表示起点和区间长度。
def uniform_distribution(loc=0, scale=1):""" 均匀分布,在实际的定义中有两个参数,分布定义域区间的起点和终点[a, b] :param loc: 该分布的起点, 相当于a :param scale: 区间长度, 相当于 b-a :return: """ uniform_dis = stats.uniform(loc=loc, scale=scale) x = np.linspace(uniform_dis.ppf(0.01), uniform_dis.ppf(0.99), 100) fig, ax = plt.subplots(1, 1)# 直接传入参数 ax.plot(x, stats.uniform.pdf(x, loc=2, scale=4), 'r-', lw=5, alpha=0.6, label='uniform pdf')# 计算ppf分别等于0.001, 0.5, 0.999时的x值 vals = uniform_dis.ppf([0.001, 0.5, 0.999]) print(vals) # [ 2.004 4. 5.996]# Check accuracy of cdf and ppf print(np.allclose([0.001, 0.5, 0.999], uniform_dis.cdf(vals))) # Ture r = uniform_dis.rvs(size=10000) ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2) plt.ylabel('Probability') plt.title(r'PDF of Unif({}, {})'.format(loc, loc+scale)) ax.legend(loc='best', frameon=False) plt.show()uniform_distribution(loc=2, scale=4)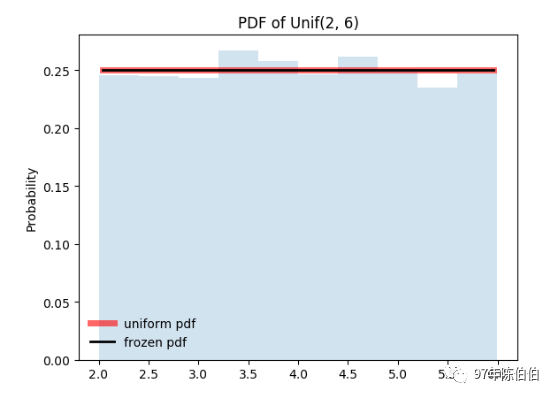
2. 指数分布
其实指数分布和离散型的泊松分布之间有很大的关系。泊松分布表示单位时间(或单位面积)内随机事件的平均发生次数,指数分布则可以用来表示独立随机事件发生的时间间隔。由于发生次数只能是自然数,所以泊松分布自然就是离散型的随机变量;而时间间隔则可以是任意的实数,因此其定义域是 (0,+∞)。
2.1 定义
如果一个随机变量 X 的概率密度函数满足一下形式,就称 X 为服从参数 λ 的指数分布(Exponential Distribution),记做 X∼E(λ) 或 X∼Exp(λ).
指数分布只有一个参数 λ,且 λ>0.
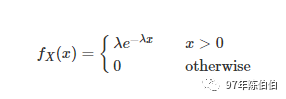
2.2 主要用途
表示独立随机事件发生的时间间隔,比如旅客进机场的时间间隔、中文维基百科新条目出现的时间间隔等;
在排队论中,一个顾客接受服务的时间长短也可以用指数分布来近似;
无记忆性的现象(连续时间)。
2.3 性质
指数分布的一个显著的特点是其具有无记忆性。例如如果排队的顾客接受服务的时间长短服从指数分布,那么无论你已经排了多久时间的队,在排 t 分钟的概率始终是相同的。
用公式表示就是:
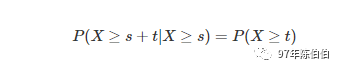
def exponential_dis(loc=0, scale=1.0):""" 指数分布,exponential continuous random variable 按照定义,指数分布只有一个参数lambda,这里的scale = 1/lambda :param loc: 定义域的左端点,相当于将整体分布沿x轴平移loc :param scale: lambda的倒数,loc + scale表示该分布的均值,scale^2表示该分布的方差 :return: """ exp_dis = stats.expon(loc=loc, scale=scale) x = np.linspace(exp_dis.ppf(0.000001), exp_dis.ppf(0.999999), 100) fig, ax = plt.subplots(1, 1)# 直接传入参数 ax.plot(x, stats.expon.pdf(x, loc=loc, scale=scale), 'r-', lw=5, alpha=0.6, label='uniform pdf')# 计算ppf分别等于0.001, 0.5, 0.999时的x值 vals = exp_dis.ppf([0.001, 0.5, 0.999]) print(vals) # [ 2.004 4. 5.996]# Check accuracy of cdf and ppf print(np.allclose([0.001, 0.5, 0.999], exp_dis.cdf(vals))) r = exp_dis.rvs(size=10000) ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2) plt.ylabel('Probability') plt.title(r'PDF of Exp(0.5)') ax.legend(loc='best', frameon=False) plt.show()exponential_dis(loc=0, scale=2)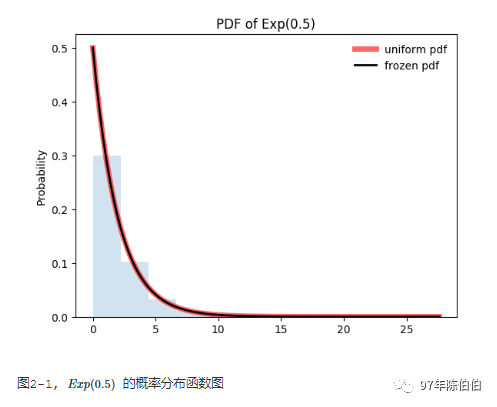
3. 正态分布
正态分布也许是出现频率最高的分布,其他人对正态分布的熟悉程度应该也是所有分布中最高的。由于中心极限定理的存在,正态分布也是所有分布应用最广泛的分布,没有之一。
3.1 定义
若随机变量 X 的概率密度符合下面的形式,就称 X 服从参数为 μ,σ 的正态分布(或高斯分布),记为 X∼N(μ,σ2).
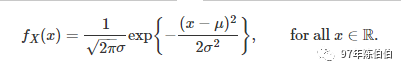
如果上面公式中 μ=0,σ=1,就叫做标准正态分布,一般记做 Z∼N(0,1)。
由于标准正态分布在统计学中的重要地位,它的累积分布函数(CDF)有一个专门的表示符号:Φ. 一般在统计相关的书籍附录中的“标准正态分布函数值表”就是该值与随机变量的取值之间的对于关系。
正态分布中两个参数含义:
当固定 σ,改变 μ 的大小时,f(x) 图形的形状不变,只是沿着 x 轴作平移变换,因此 μ 被称为位置参数(决定对称轴的位置);
当固定 μ,改变 σ 的大小时, f(x) 图形的对称轴不变,形状改变, σ 越小,图形越高越瘦, σ 越大,图形越矮越胖,因此 σ 被称为尺度参数(决定曲线的分散程度)
3.2 性质
f(x) 关于 x=μ 对称;
当x≤μ时,f(x)是严格单调递增函数;
fmax=f(μ)=12π√σ;
当 X∼N(μ,σ2) 时,X−μσ∼N(0,1)
利用第4条性质,在计算一般正态分布的概率时,可以转化为标准正态分布函数来计算。
3.3 Python实现
def diff_normal_dis():""" 不同参数下的指数分布 :return: """ norm_dis_0 = stats.norm(0, 1) # 标准正态分布 norm_dis_1 = stats.norm(0, 0.5) norm_dis_2 = stats.norm(0, 2) norm_dis_3 = stats.norm(2, 2) x0 = np.linspace(norm_dis_0.ppf(1e-8), norm_dis_0.ppf(0.99999999), 1000) x1 = np.linspace(norm_dis_1.ppf(1e-10), norm_dis_1.ppf(0.9999999999), 1000) x2 = np.linspace(norm_dis_2.ppf(1e-6), norm_dis_2.ppf(0.999999), 1000) x3 = np.linspace(norm_dis_3.ppf(1e-6), norm_dis_3.ppf(0.999999), 1000) fig, ax = plt.subplots(1, 1) ax.plot(x0, norm_dis_0.pdf(x0), 'r-', lw=2, label=r'miu=0, sigma=1') ax.plot(x1, norm_dis_1.pdf(x1), 'b-', lw=2, label=r'miu=0, sigma=0.5') ax.plot(x2, norm_dis_2.pdf(x2), 'g-', lw=2, label=r'miu=0, sigma=2') ax.plot(x3, norm_dis_3.pdf(x3), 'y-', lw=2, label=r'miu=2, sigma=2') plt.ylabel('Probability') plt.title(r'PDF of Normal Distribution') ax.legend(loc='best', frameon=False) plt.show()diff_normal_dis()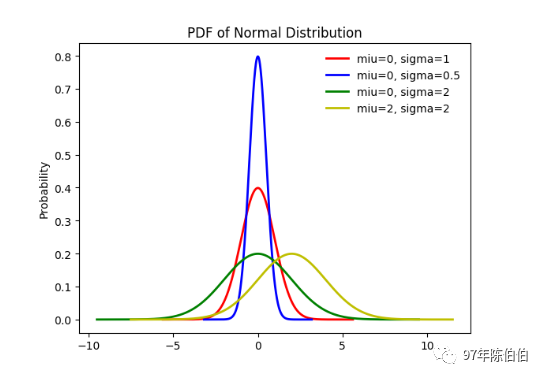
更多内容,欢迎交流
亦有学习社群
















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









