





1.文档编写目的
Fayson在最近写了很多关于NameNode恢复,或者NameNode角色迁移相关的文章,但都是基于HDFS已经启用HA的情况来操作的包括你将要阅读的本文,这也是Hadoop作为一个生产系统所必须的,当然假如万一你没有启用HDFS HA,涉及单个NameNode的备份恢复或者迁移节点,可以参考Fayson很早之前的一篇文章《0360-NameNode Metadata备份和恢复最佳实践》。
在前面的文章中,主要是《0526-6.1-如果你不小心删了一个NameNode1》和《0527-6.1-如果你不小心删了一个NameNode2》,我们假定的一个场景是你不小心删掉了某个NameNode节点上的所有角色包括NameNode,JournalNode和Failover Controller,或者你不小心通过Cloudera Manager直接从主机管理列表里移除了该NameNode节点,然后你想再把这个节点加回去,具体该如何操作。
这次我们将这种假定场景的恶劣程度进行升级,你的集群中的NameNode,JournalNode和Failover Controller三个角色所在的硬件服务器突然遭遇天灾人祸,完全损坏了,而且没办法恢复,这时我们如何将一台全新的服务器重新加入集群并分配这些角色还能保证HDFS服务正常启动并运行呢。Fayson在接下来的本文将会进行细致的描述说明。
- 测试环境
1.CDH6.1
2.Redhat7.4
3.HDFS已经启用HA
4.采用root进行操作
2.模拟异常
1.首先Fayson准备一个正常的CDH6.1的集群,并且HDFS已经启用了HA。
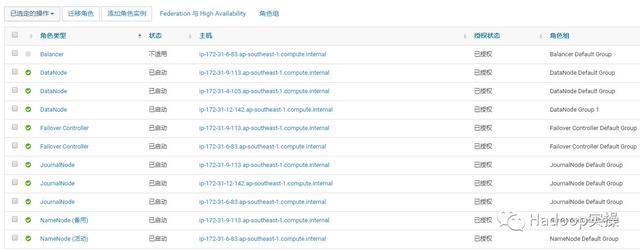
2.我们停止ip-172-31-9-113.ap-southeast-1.compute.internal节点上的NameNode,JournalNode和Failover Controller服务。


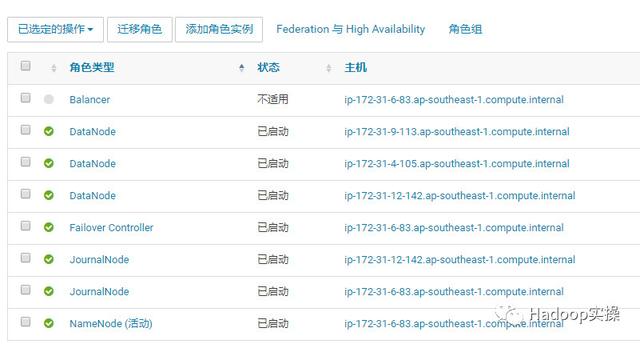
3.删除这三个角色,注意下表已经少了这三个角色。
4.这是HDFS服务直接报错了。
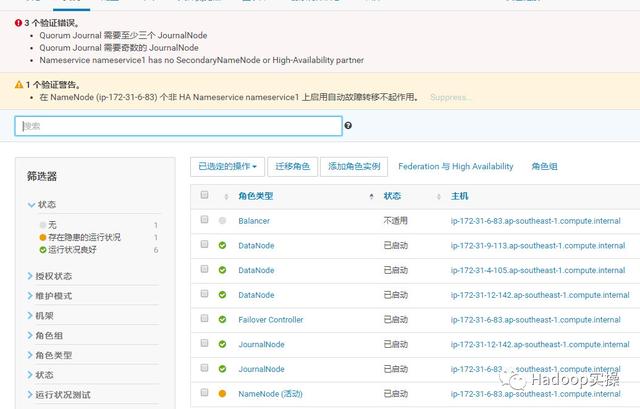
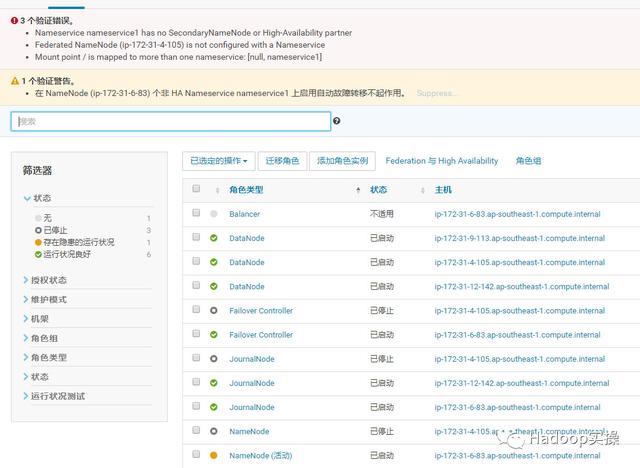
3 个验证错误。 Quorum Journal 需要至少三个 JournalNode Quorum Journal 需要奇数的 JournalNode Nameservice nameservice1 has no SecondaryNameNode or High-Availability partner1 个验证警告。 在 NameNode (ip-172-31-6-83) 个非 HA Nameservice nameservice1 上启用自动故障转移不起作用。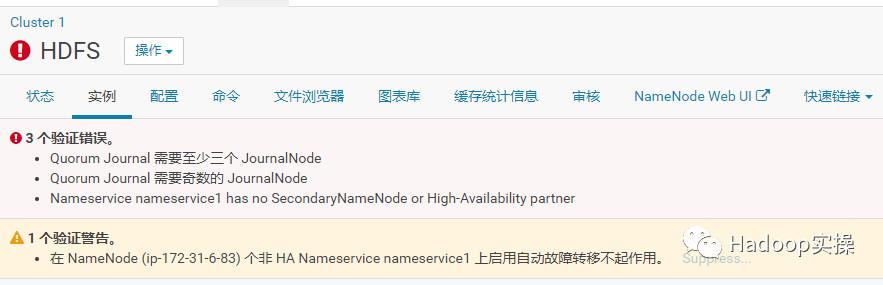
5.这里模拟的是ip-172-31-9-113这个节点完全损坏,因为Fayosn的集群机器个数有限,ip-172-31-9-113这个节点实际还有DataNode角色,请忽略。然后我们将会在一个新的节点ip-172-31-4-105上重新设置NameNode相关角色并且尝试进行恢复HDFS服务。
3.故障修复方法1
1.我们选择HDFS服务,然后点击“操作”,发现虽然是HDFS HA的集群,操作列表显示却是“启用High Availability”,实际应该是“禁用High Availability”,应该是因为手动删除了一个NameNode后引起的。
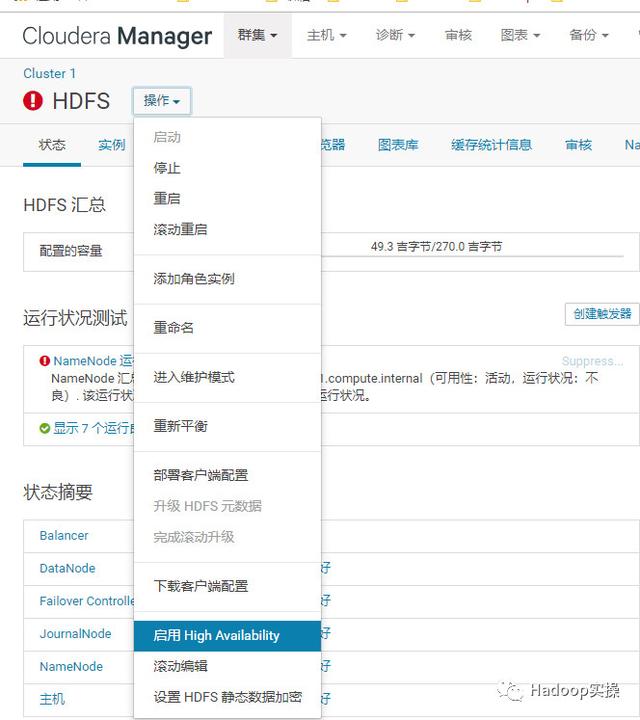
2.我们先尝试点击该按钮,尝试重新启用HDFS的HA。
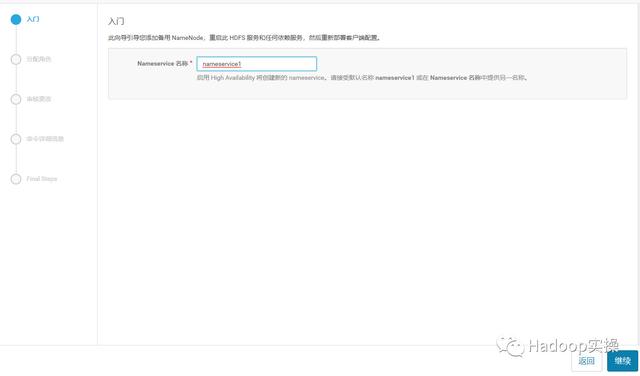
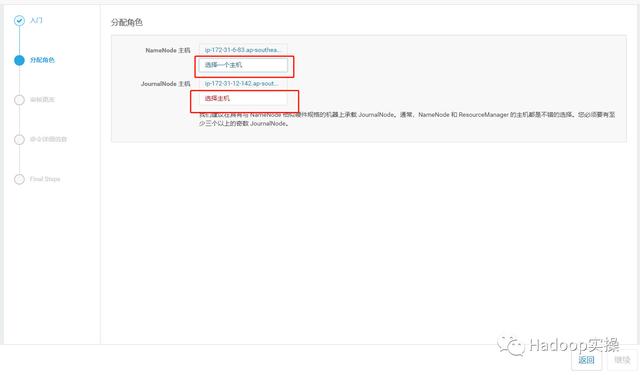
这里我们选择之前的删掉的NameNode和JournalNode节点
ip-172-31-4-105.ap-southeast-1.compute.internal
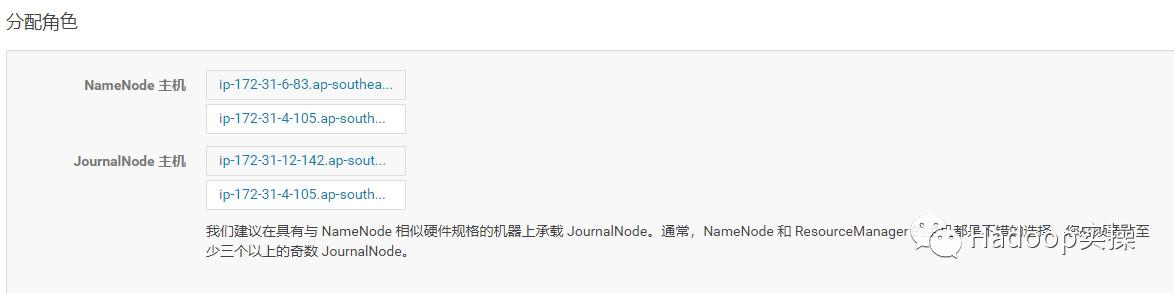
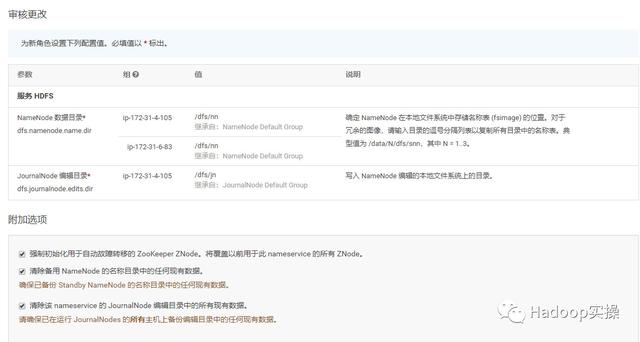

报错,启用失败,实际其实我们已经选择了三个JournalNode,但仍旧报错需要3个JournalNode,返回,我们继续尝试。
4.故障修复方法2
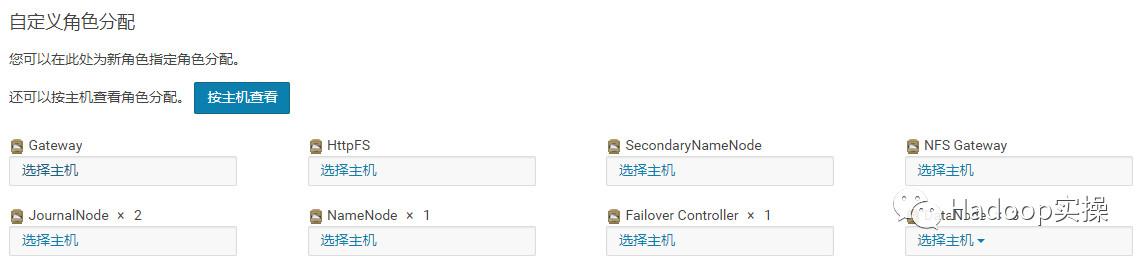
1.从以下界面把删掉的NameNode,JournalNode和Failover Controller的三个角色再给加回去。注意是加到新的节点ip-172-31-4-105。
2.点击添加角色实例,并相应的选择之前删掉NameNode,JournalNode和Failover Controller角色所在的主机ip-172-31-4-105.ap-southeast-1.compute.internal
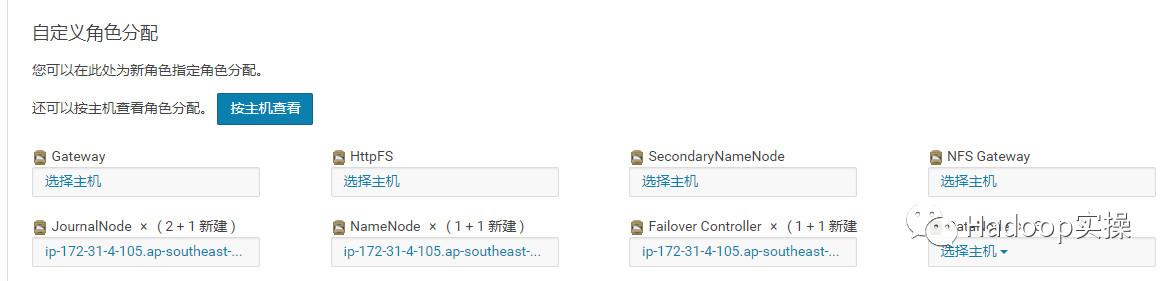
3.点击“继续”
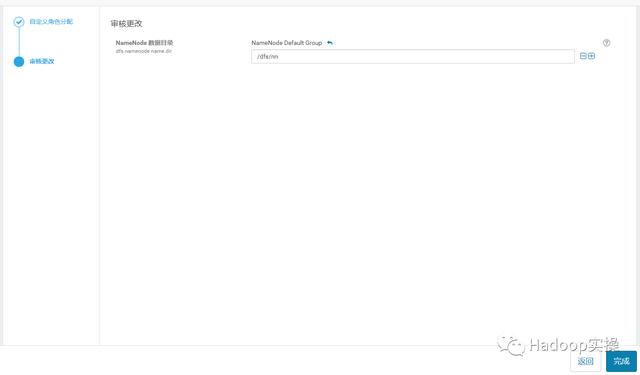
4.点击“完成”
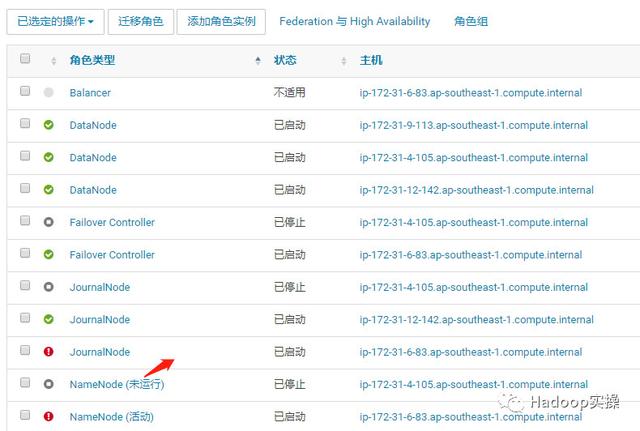
5.直接重启HDFS服务,尝试拉起刚刚新加的三个角色

还是失败。
6.进入ip-172-31-4-105.ap-southeast-1.compute.internal节点所在的NameNode配置页面。
选择“配置”标签页
在“NameNode Nameservice”配置项中输入nameservice1,这里根据你集群启用HA后的实际情况nameservice的名字输入,然后保存。
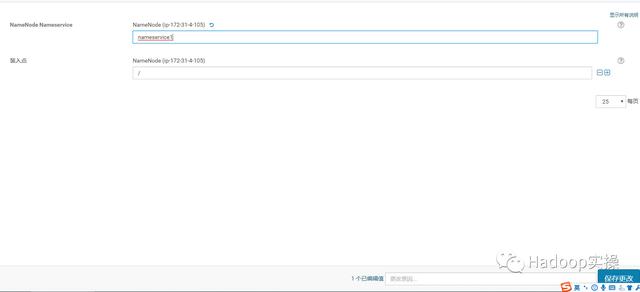
7.在“Quorum Journal 名称”配置项也输入nameservice1,这里根据你集群启用HA后的实际情况nameservice的名字输入,然后保存。
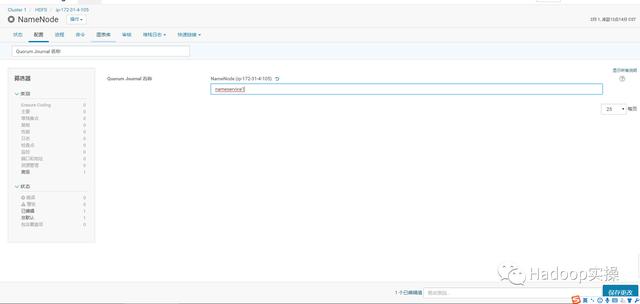
8.勾选“启用自动故障转移”,然后保存。

9.回到HDFS服务的实例页面,发现之前的错误已经消失了。
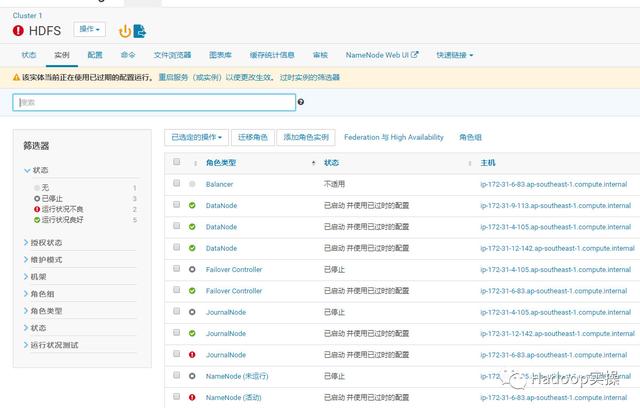
10.回到CM主页重新部署客户端,并重启集群所有服务。
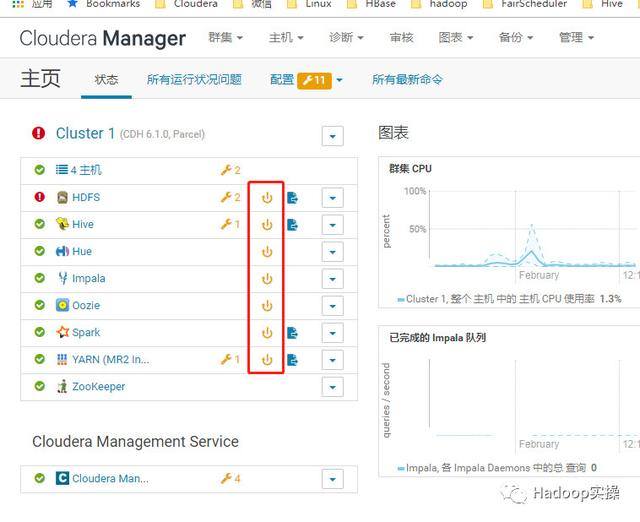
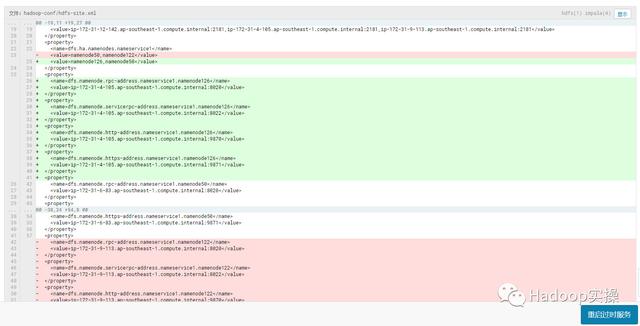
点击“立即重启”,开始重启整个集群,并且会部署客户端配置。

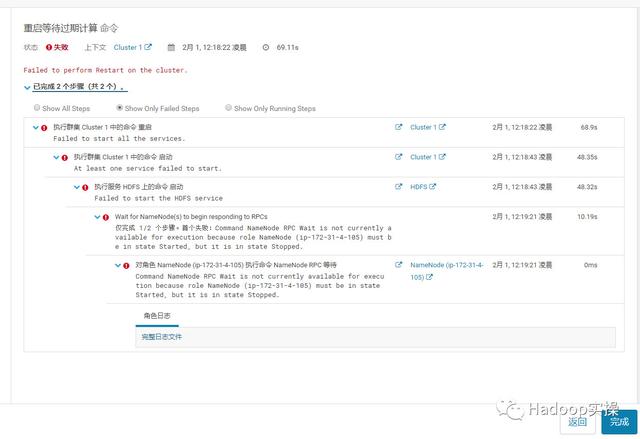
重启失败,主要是新加的节点ip-172-31-4-105作为NameNode角色起不来,查看角色日志报错如下:
Failed to start namenode.java.io.IOException: NameNode is not formatted. at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:237) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1082) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:707) at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:665) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:727) at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:950) at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:929) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1653) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1720)
11.先手动只是部署客户端配置
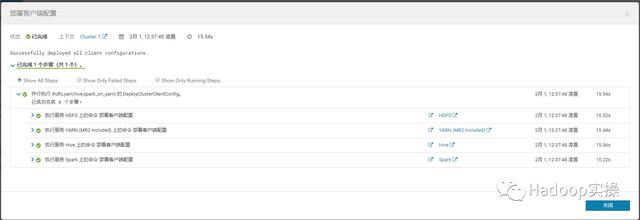
部署成功
12.因为新加的节点ip-172-31-4-105上虽然划分了NameNode和JournalNode角色,但是没有JournalNode的edits数据,我们从之前正常的节点ip-172-31-6-83拷贝相应的数据到ip-172-31-4-105
cd /dfstar czvf jn.tar.gz jn/scp jn.tar.gz root@ip-172-31-4-105:/dfs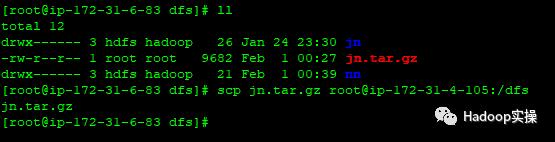
注:/dfs/jn目录为Fayson集群的HDFS配置的JournalNode目录。
13.登录到ip-172-31-4-105节点进入/dfs目录进行确认。
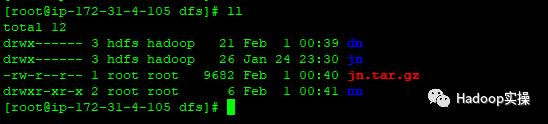
已经有nn和jn目录,实际是空的,因为ip-172-31-4-105为一个新的节点,我们先删除掉nn和jn目录,然后解压从ip-172-31-6-83传过来的2个压缩文件。
[root@ip-172-31-4-105 dfs]# rm -rf nn[root@ip-172-31-4-105 dfs]# rm -rf jn[root@ip-172-31-4-105 dfs]# tar xvzf jn.tar.gz
注意:务必保证jn解压后的权限与属组正确,可以与健康节点ip-172-31-6-83中的相应目录进行比对。
14.回到CM主页,再次重启HDFS服务
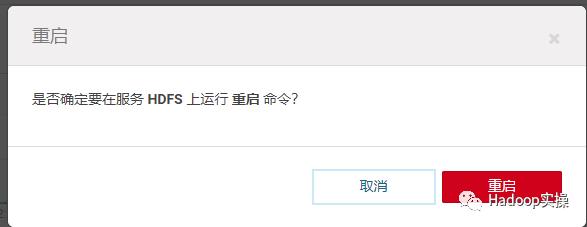
还是重启失败,失败错误与之前一致。
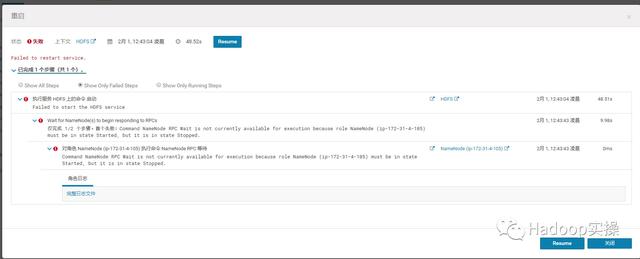
15.回到HDFS服务页面,我们发现只是ip-172-31-4-105上的NameNode服务没起来,JN服务比之前好一点,还是启动成功了。

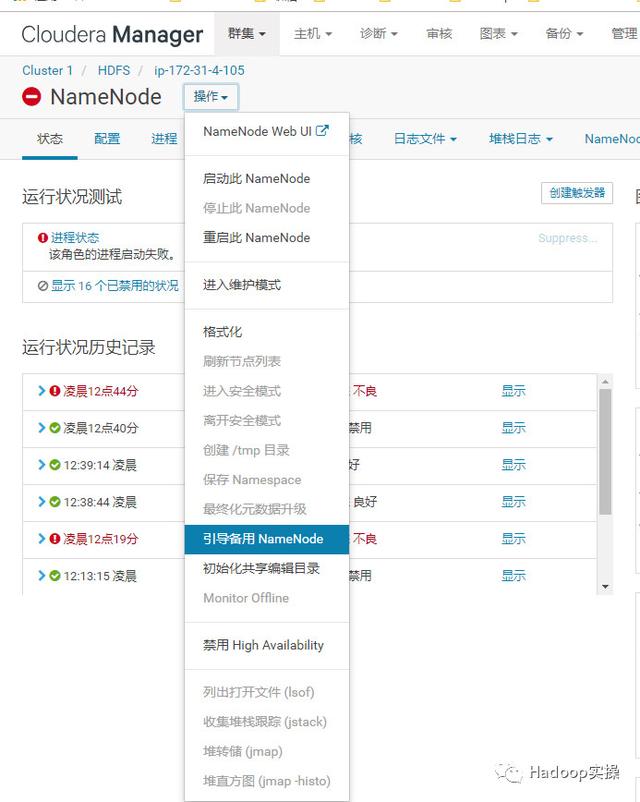
16.进入ip-172-31-4-105的NameNode页面,选择“操作” – > “引导备用NameNode”,这个操作会将之前的NameNode ip-172-31-6-83上的fsimage拷贝到新的NameNode节点上。
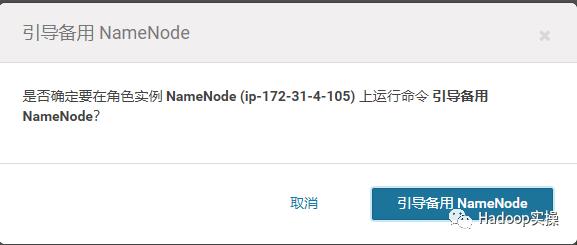
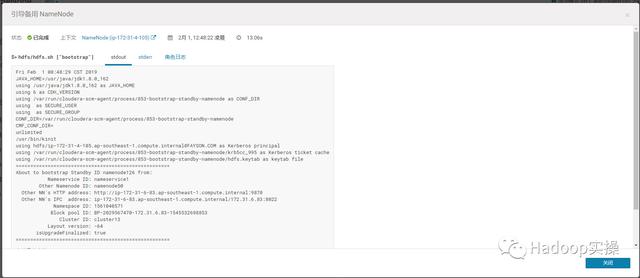
引导成功:
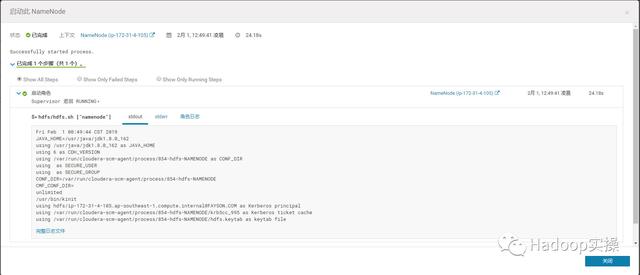
17.启动ip-172-31-4-105节点上失败的NameNode服务
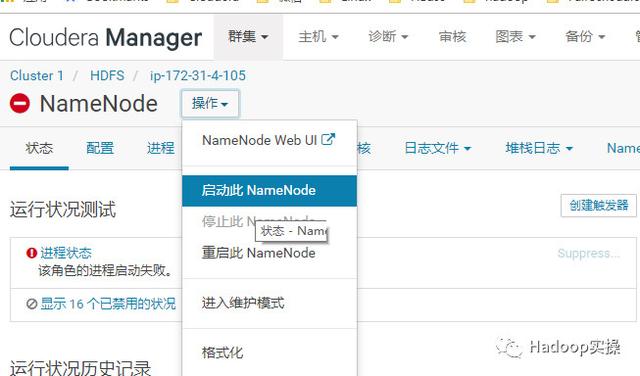
启动成功:
18.进入HDFS服务页面,选择“操作”->“滚动编辑”,该步骤是为了同步3个JournalNode

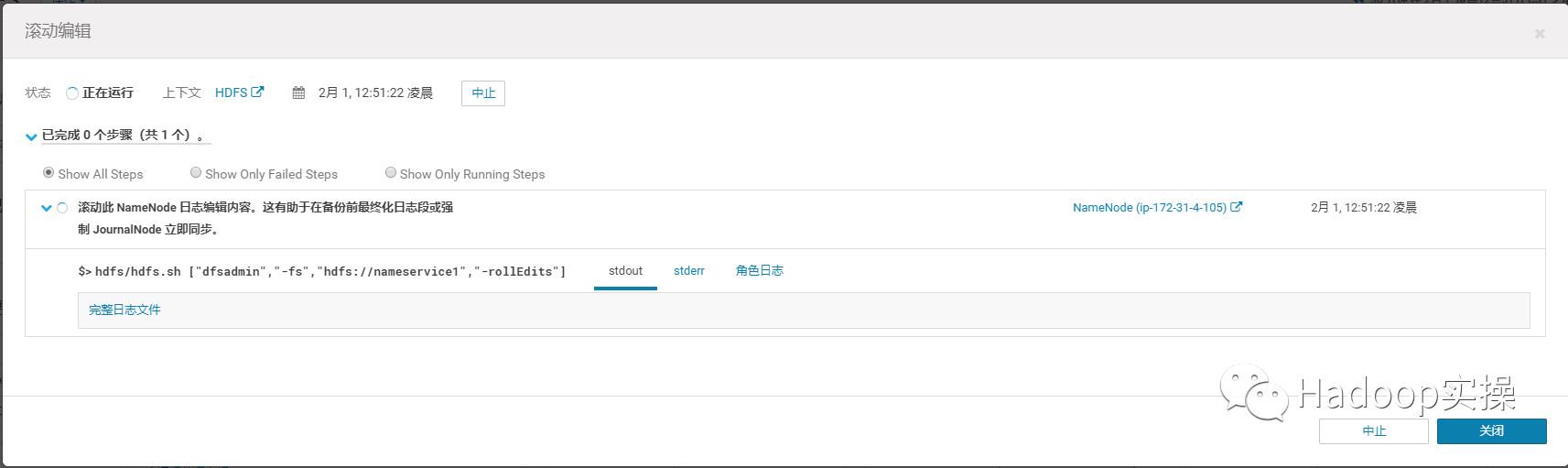
同步成功

至此,HDFS服务已经恢复了正常:
19.HDFS简单功能测试
5.总结
1.因为涉及管理节点NameNode相关的操作,所以你如果出现本文假设的情况,在按照本文进行操作前,最好备份NameNode的元数据以及JournalNode的edits数据,本文节省篇幅省略了该步骤。
2.本文有很多内容是与《0526-6.1-如果你不小心删了一个NameNode1》文章相同的,但是我们需要注意的是本文新加的NameNode角色节点ip-172-31-4-105是没有相关的NameNode元数据目录和JournalNode的edits目录的,包括这些目录中的数据,本文是通过手动的方式来进行恢复的。
3.首先是从另外一个NameNode上拷贝JournalNode的edits目录到新节点ip-172-31-4-105(拷贝过程中请务必注意目录的属组与权限),拉起该节点的JN服务后,通过CM界面化命令“引导备用NameNode”,将NameNode的元数据从ip-172-31-6-83节点拷贝到新的NameNode ip-172-31-4-105。然后启动ip-172-31-4-105节点上的NameNode服务才能成功。
4.最后请不要忘记执行JournalNode的Roll Edits操作,以强制同步3个JournalNode节点,因为ip-172-31-4-105上的JN角色也是新加入的。















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









