





有没有一些办法能够预测我们应用性能和可用性呢?我们是否能够预测我们应用在20分钟之后处于什么状态?我们能不能预测在接下来的20分钟,我们系统是否会出现OOM异常,CPU峰值,系统崩溃?好像是不行的,因为我们总是在意一些宏观指标:
- 内存利用率
- 响应时间
- CPU利用率
这些都是很重要的系统指标,但它们不能作为预测应用程序性能/可用性特征的主要指标。现在,让我们讨论几个可以预测应用程序性能/可用性特征的微观指标。
示例
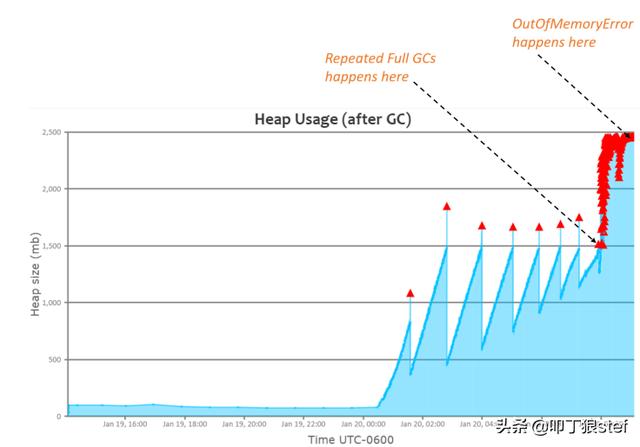
注意后面时间段重复执行的完全GC
我们先来看一个例子。图例中的应用,遇到了OOM异常。查看堆使用图(由GC日志生成),可以从图中注意到,虽然重复的执行着完全GC,但是堆的使用率越来越高。从8点左右开始,完全GC不断被执行,在10点左右,应用抛出了OOM异常。从8点到10点之间,应用一直在完全GC。如果运维团队能够注意到GC的异常活动,就可以预见应用在几个小时之内,就会抛出OOM异常。
内存相关的微观指标
有四个和内存/GC相关的微观指标,值得我们关注:
- GC吞吐量
- GC暂停时间
- 对象创建频率
- 堆峰值大小
下面分别阐述。
1. GC吞吐量
GC吞吐量是指,在单位时间内,应用花在处理用户业务的时间和应用花在GC的时间比。
假设我们的应用运行了60分钟,在这60分钟内,我们检测到有2分钟时间,是花在了GC上。那么,意味着应用花费了3.33%(2/60*100%)时间在GC上,那么我们说GC的吞吐量为96.67%(100%-3.33%) 。
当我们注意到在一段时间内,GC吞吐量在持续下降,那么可能以为着某些内存问题正在出现,需要引起持续的关注了。
2. GC延迟
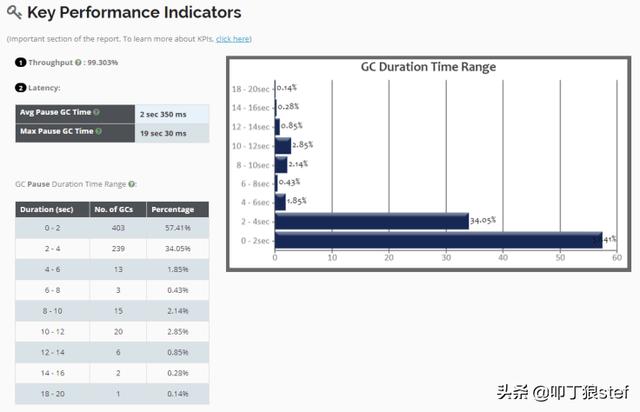
吞吐量&GC延迟时间 指标
当GC运行到某些阶段的时候,整个应用程序将暂停等待。这种暂停被称为延迟。有些GC阶段可能需要几毫秒,而有些GC阶段可能需要几秒到几分钟。持续监视GC暂停时间,如果GC暂停时间开始变长,可能意味着出现了某些内存问题。
3. 对象创建频率
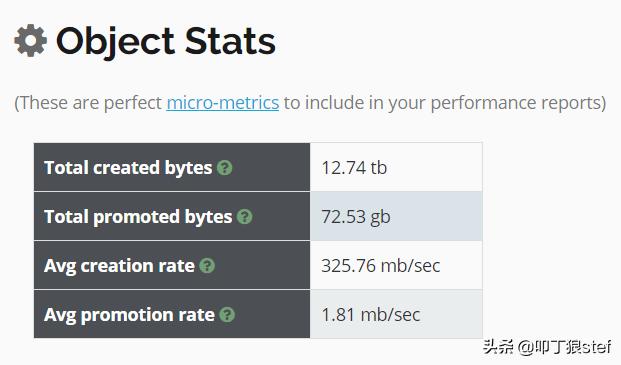
对象创建频率
对象创建频率,是我们应用单位时间内创建对象的平均数量。假如一段时间内,应用创建对象的频率是100MB/秒,在没有任何明显流量增加的情况下,对象创建频率增加到了150MB/秒,那需要注意,是否应用出现了某些问题。这些额外的对象创建频率有可能触发更多的GC活动,增加CPU消耗并降低应用响应时间。
同样,还可以在CI/CD管道中使用相同的指标来度量代码提交的质量。假设在以前的代码版本中,应用对象创建频率为50mb/秒。最近提交了代码,假设应用程序在相同流量下,对象创建频率变成了75mb/秒,那么这表明最近提交的代码中,可能存在需要review的问题代码。
4. 堆峰值大小

堆峰值大小
堆峰值即应用消耗的最大内存量。如果堆峰值大小超出了限制,则必须对其进行检查。可能的问题:应用程序中存在潜在的内存泄漏,新引入的代码(或第三方库)正在消耗大量内存。
如何搜集这些信息?
所有这些微观指标都可以从GC日志得到。在Java8之前,使用:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:从Java9开始,使用:
-Xlog:gc*:file=得到GC日志数据之后,可以使用fastThread等来完成日志的分析。
示例
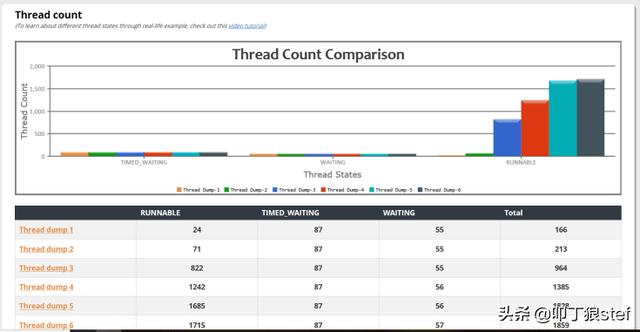
几个小时运行之后,一个主要的金融项目抛出异常:“OutOfMemoryError: unable to create new native thread”。这个应用在重启之前,开启了一个JDBC新的功能。显然,这个新特性有一个bug,JDBC驱动程序开始重复生成新线程(而不是重新使用相同的线程)。因此,在很短的时间内,应用程序开始遇到“OutOfMemoryError: unable to create new native thread”。如果团队能够监视线程数量和线程状态,那么他们就可以很早地发现问题并防止出现这样的严重问题。下图是运行过程中真实的Thread dumps,可以注意到,在每一个时间段中,RUNNABLE状态的线程数量,都在持续增长。
线程相关微观指标
有四个线程相关的微观指标值得关注:
- 线程数量
- 线程状态
- 线程组
- 线程运行模式
在下面分别讨论。
1. 线程数量
线程数量是一个很有趣的微观指标。当线程数量超过一个限制,CPU,内存都会出问题,导致应用挂掉。过多的线程数量,可能会导致: ‘java.lang.OutOfMemoryError: unable to create new native thread’ 异常。所以,一旦发现线程数量在持续增长,则需要警惕是否应用出现了一些问题(如上面例子)。
2. 线程状态
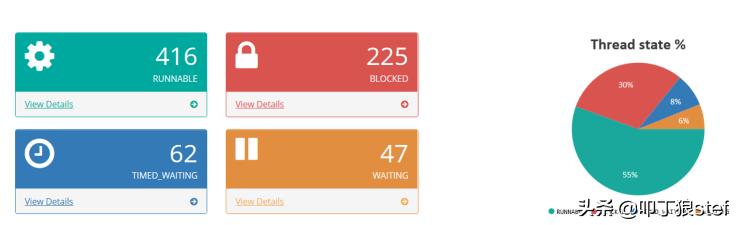
应用线程有6中不同状态,包括:NEW, RUNNABLE, WAITING, TIMED_WAITING, BLOCKED, TERMINATED。若有太多线程处于RUNNABLE状态,则可能导致CPU过载。过多线程处于BLOCKED状态,极有可能导致应用出现无响应。如果处于特定线程状态的线程数超过了应用程序的标准阈值,则需要极度关注该指标的变化,是可以对应用状态进行预估的一个重要指标。
3. 线程组
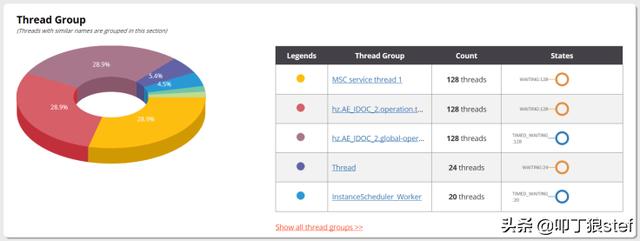
线程组是运行相似任务的线程的集合。比如一个包含处理所有HTTP请求的Servlet容器线程组,或者是在统一处理JMS发送/接受任务的JMS线程组,等等。除此之外,应用程序中可能还有其他一些敏感线程组。监视这些线程组的大小。设定预期的线程组阈值范围,并尽量将线程组大小控制在其中。线程组中的线程数越少,则可能会造成处理阻塞,线程过多,有可能会导致内存、CPU问题。
4. 线程运行模式
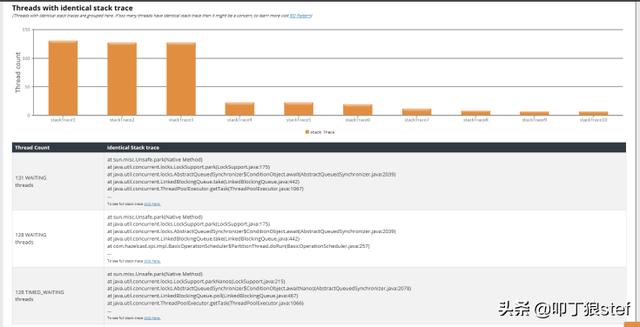
如果监控中,发现大量线程开始显示相同/重复的堆栈跟踪信息,它可能表示出现了性能问题。考虑以下情况:
(a). 假设你的SOR或外部服务正在降低响应速度,那么大量线程将开始等待其响应。在这种情况下,这些线程将显示相同的堆栈跟踪信息。
(b). 假设一个线程获得了一个锁,但它从未释放过该锁,那么处于相同执行路径的其他几个线程将进入阻塞状态,并显示处相同的堆栈跟踪信息。
(c). 如果出现了死循环,则执行该循环的多个线程将显示相同的堆栈跟踪信息。
当上述任何一种情况发生时,应用程序的性能和可用性都将受到影响。这时候就需要关注线程运行模式了。
网络相关微指标
有三个网络相关的微观指标值得关注:
- TCP/IP 链接数量
- TCP/IP 状态
- OPEN FILE DESCRIPTORS
在下面分别讨论。
1 . TCP/IP 链接数量
现在的应用一定会和大量外部应用链接(就正常的外部应用,还不说微服务了)。各种各样的链接协议在应用中使用:HTTP, HTTPS, SOAP, REST, JDBC, JMS, Kafka等等。在这种生态系统中,应用程序的响应性和可用性在一定程度上依赖于外部应用程序的可用性和响应性。因此,你需要监视从应用程序到外部应用程序建立的连接数。如果您看到连接计数的增长超过了正常的流量增长速度,那么这可能是一个问题。每当外部应用程序中的速度变慢时,应用程序就有可能打开越来越多到外部应用程序的连接来处理传入的事务,造成内部请求的阻塞。
可以使用netstat来检查链接到外部系统的连接数:
$ netstat -an | grep ESTABLISHED | grep '162.187.223.11' | wc -l这个命令会显示链接到162.187.223.11主机的链接数。
2 . TCP/IP 状态
有11种TCP/IP状态:LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2, CLOSE-WAIT, CLOSING, LAST-ACK, TIME-WAIT, CLOSED。您需要监视应用程序连接的每个外部系统在每个状态下的连接数。如果您注意到特定状态的链接数量开始增长,比如CLOSE-WAIT或LAST-ACK…则可能表明可能由于外部链接的问题,系统在出现一些不良状况。
$ netstat -an | grep 'TIME_WAIT' | wc -l上面的命令,展示了处于TIME_WAIT状态的连接数。
3 . OPEN FILE DESCRIPTORS
文件描述符是用来处理访问:
(a). 文件
(b). 管道 (i.e. ls -l | grep key | less)
(c). 网络链接
如果发现应用中文件描述符数量持续增长,可能的原因是应用没有正确的关闭某些资源。未关闭的文件描述符数量若超过一定阈值,会造成应用性能和稳定性的问题。
下面的命令会展示PDI:5666 打开的文件描述符情况:
lsof -p 5666如果想统计该PID打开的文件描述符数量,可以使用下面的命令:
$ lsof -p 5666 | wc -l153存储相关微指标
有三个存储相关的微观指标值得关注:
- IOPS
- Storage Throughput
- Storage Latency
在下面分别讨论。
1 . IOPS
每秒IO操作数,即每秒可以执行的读或写操作的数量。对于某些IO操作,IO请求大小可能非常小。IO大小的示例可以是4KB、8KB、32KB等等。因此,较大的IO请求大小可能意味着更少的IOPS。
2 . Storage Throughput
存储吞吐量显示了一个存储设备可以提供多少存储能力。此数字通常以兆字节/秒(MB/s)表示,例如140 MB/s。下面的公式导出吞吐量。
平均IO大小x IOPS=吞吐量(MB/s)
3 . 存储延迟
每个IO请求都需要一些时间才能完成,这称为平均延迟。此延迟以毫秒为单位进行测量,应尽可能将延迟低,不过存储延迟一般由硬件造成,可以通过使用内存存储来改善。
总结
在生产环境中,可以对这种微指标进行监测,以预测可能产生的生产问题,并做好提前防范。除此之外,它们还可以在CI/CD中用于监控代码质量。















 2993
2993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









