





1.背景
java复制文件的方式其实有很多种,可以分为 - 传统的字节流读写复制FileInputStream,FileOutputStream,BufferedInputStream,BufferedOutputStream - 传统的字符流读写复制FileReader,FileWriter,BufferWriter,BufferedWriter,BufferedReader - NIO系列的FileChannel - FileChannel+缓冲 - java.nio.Files.copy() - 第三方包中的FileUtils.copy方法,比如org.apache.commons.io.FileUtils,org.codehaus.plexus.util.FileUtils等等.
所以呢,看看各种方法效率怎么样,主要衡量的标准就是时间,另外的一些标准包括大文件的复制时的内存溢出等问题.
2.概述
由于很多时候复制文件都包括了文件夹下的所有子目录及文件的复制,所以作者采用的遍历+复制方法去复制文件.就是把整个复制过程分为先遍历,遍历的过程中遇到文件夹就创建,遇到文件就调用不同的复制方法. 遍历的5种方法:
- (1)File.listFiles()
- (2)File.list()
- (3)org.codehaus.plexus.util.FileUtils.getFiles()
- (4)org.apache.commons.io.FileUtils.listFiles()
- (5)java nio中的java.nio.file.Files.walkFileTree
复制的8种方法:
- (1)FileInputStream+FileOutputStream - (2)BufferedInputStream+BufferedOutputStream
- (3)FileReader+FileWriter
- (4)BufferedReader+BufferedWriter
- (5)FileChannel
- (6)FileChannel+buffer
- (7)org.apache.commons.io.FileUtils.copyFile()
- (8)java.nio.file.Files.copy()
另外作者不太想看控制台.....所以配合了一点swing使用.
3.jar包
1.org.apache.commons
2.org.codehaus.plexus
4.遍历
(1)listFiles()
private 通过srcFile的listFiles()获取所有的子文件与子文件夹,然后判断是否是目录 如果是目录,首先判断有没有这个文件(有时候本来是文件夹但是却存在同名的文件,就先删除),再创建文件夹,然后递归执行函数. 如果不是目录,直接把两个File作为参数进行文件复制,里面用什么方法后面会设置.
(2)list()
private list与第一种listFiles()类似,不过是String[],也是先判断目录,创建目录,不是目录直接复制
(3)org.codehaus.plexus.util.FileUtils.getFiles
private 这是用了别人的工具类进行遍历.
org返回的结果的java.util.List
(4)http://Commons.io工具包
private 使用org.apache.commons.io.FileUtils的listFiles方法,参数为要遍历的目录,一个null和一个false,第二个参数表示过滤器,表示过滤出特定后缀名的文件,类型为String [],第三个布尔参数表示是否递归访问子目录.
(5)NIO--walkFileTree
利用FileVisitor这个接口.实际中常用SimpleFileVisitor.
private FileVisitor接口定义了四个方法,分别为:
public 在上面的例子中只是实现了visitFile,因为只是复制操作,首先判断是否是源目录的路径,不是的话创建文件夹再复制文件. 这里说一下返回值FileVisitResult.FileVisitResult是一个枚举类型,根据返回值判断是否继续遍历. FileVisitResult可取值: - CONTINUE:继续 - TERMINNATE:结束 - SKIP_SIBLINGS:继续,跳过同一目录的节点 - SKIP_SUBTREE:继续,跳过子目录,但会访问子文件
5.复制
(1)FileInputStream+FileOutputStream
首先是经典的字节流FileInputStream+FileOutputStream,这个比较简单,使用FileInputStream读取后使用FileOutputStream写入,不过效率嘛.....一般般.
private 这里说一下三个read方法的区别,FileInputStream有三个read方法:
inputA.read()
逐个字节进行读取,返回int,写入时直接使用write(n);
int 这个可以说是三个read中最慢的....作者试了一个2G左右的文件,用了大概10分钟才复制160M......
B.read(b)
参数是一个byte [],将字节缓冲到其中,返回数组的字节个数,这个比read()快很多.
byte C.read(b,off,len)
这个方法其实和read(b)差不多,read(b)相当于省略了参数的read(b,off,len).
byte 这两个都是调用一样的readBytes():
private 至于效率...可以看看结果(作者用的是10G内的小文件):




可以看到,没有哪个一定比另外一个更快(不过最后一个误差有点太大了?7G不够的文件.). 采用哪一个建议自己去测试,毕竟这存在很多误差,比如文件,java版本,机器本身等等,仅供参考.
(2)BufferedInputStream+BufferedOutputStream
缓冲字节流BufferedInputStream+BufferedOutputStream,相比起FileInputStream,BufferedInputStream读取时会先从缓冲区读取数据,缓冲区无可读数据再从文件读取,所以会比FileInputStream快.
private 这里也说一下BufferedInputStream的三个read(实际上还有,还有readN,与read(),read()肯定最慢,readN作者很少用,所以就没列出来了)
readA.read(b)
这个其实和FileInputStream的那个没啥区别,把一个字节数组仍进去就好了.
B.read(b,off,len)
这个....也和FileInputStream那个没啥区别,不说了
C.readAllBytes()
这个一次可以读取所有的字节.不过用这个虽然省事,可以直接
output但是呢,有代价的:

会出现OutOfMemory错误,就是对于大文件还是老老实实分开吧,不要"一口搞定","多吃几口".
看看效率:
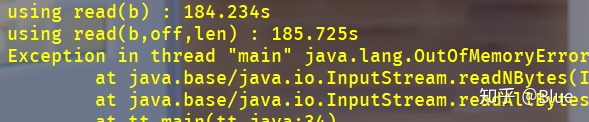
readAllBytes对于大文件(作者这个是5G内的文件)直接爆内存....
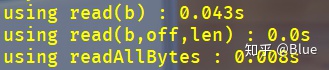

readAllBytes()又爆了.....这个才2G不到的文件...readAllBytes()看来不是很给力啊....不过对于小文件效率还可以接受.
(3)FileReader+FileWriter
字符流读写FileReader+FileWriter,相比起字节流的read,基本上把byte[]换成char[]即可,因为是逐个字符读取,而字节流是逐个字节读取因此采用byte[]. 注意这个不能用来读取图片,音乐等文件,不然复制出来的文件打不开.
private (4)BufferedReader+BufferedWriter
缓冲字符流读写BufferedReader+BufferedWriter,BufferedReader相比起FileReader有一个readLine()方法,可以每行读入,会比FileReader快.对应的BufferedWriter提供了write(String)方法,当然也有write(String s,int off,int len).同样这个不能用来读取图片等.
private (5)NIO--FileChannel
通过FileChannel复制,首先通过FileInputStream与FileOutputStream打开流,再用getChannel()方法.最后使用transferTo()或transferFrom()进行复制,一条语句即可,十分方便,而且效率很高.
private 另外感谢评论(感谢cls)指出,FileChannel只能复制2G以内的文件,因为源码有如下判断:
int var8 = (int)Math.min(var3, 2147483647L);(6)NIO--FileChannel+ByteBuffer
在利用了FileInputStream与FileOutputStream打开了FileChannel的基础上,配合ByteBuffer使用.
private flip的意思是"翻转",
buffer把Buffer从写模式变为读模式,接着write(buffer),再把buffer清空. 看看这两种方法效率:



另外作者发现transferTo的"上限"为2G,就是对于大于2G的单个文件最多最能复制2个G. 所以...对于大文件没有可比性了.
(7)FileUtils.copyFile()
这是工具类,没啥好说的,参数是两个File,分别表示源与目标.
private (8)Files.copy()
这是官方提供的Files工具类,前两个参数为Path,分别表示源与目标,可以设置第三个参数(或者省略),表示选项.例如可以设置
StandardCopyOption注意Files.copy会保持文件的隐藏属性,原来是隐藏的文件复制后也是隐藏的.以上7种则不会.
6.其他
(1)swing布局
A.网格布局
主JFrame采用了网格布局
setLayout三行一列,因为只要三个按钮,选择源文件(夹),选择目标文件夹,选择遍历方式. 选择遍历方式/复制方式的JFrame同样适用了网格布局:
showTraverseMethodB.居中
setBounds高400,宽400,利用ToolKit.getDefaultToolKit().getScreenSize()获取屏幕的高度和宽度实现居中.
C.组件的添加与删除
由于在主JFrame中只有三个按钮,选择完遍历方式后需要更新这个组件,作者的做法是先删除这个组件在添加组件:
traverseMethodButton设置它不可见再删除,再添加另一组件,再设置可见.
(2)进度条
进度条这个东西把作者搞得很惨啊......其实就是新建一个线程就可以了. 核心代码为:
new 作者的JProgressBar是直接添加在一个JFrame中的,不用什么太复杂的布局. 获取百分比后调用setValue(),一定要新建一个线程操作,不然不能正常显示进度条. 另外复制的操作建议使用SwingWorker.
SwingWorker7.测试
说了那么多来点实际的. (以下所有的测试都是删除复制的文件后再进行新一次的复制.)
(1)1G文件

文件的话其实纵向比较即可,因为基本不用怎么遍历,横向比较可以勉强看作求平均值. 对于非文本文件,FileReader/Writer和BufferedReader/Writer没有太大的参考意义,比如复制视频文件是打不开的,而且复制出来的文件会变大.对于单文件Files.copy的性能非常好,java的nio果然厉害.
(2)10G文件

这个10G的文件是文本文件. 现在可以看看FileChannel的这一行,明显所花的时间要比其他要少,为什么呢? 因为文件大于2G.FileChannel的trasferTo方法只能写入最多2G的文件,所以对于大于2G的文件复制出来只有2G,因此FileChannel的这一行没有太大可比性.对于文本文件,BufferedReader/Writer的复制速度是最快的了,其次是FileInput/OutputStream.对于单个大文件,apache的FileUtils与NIO的Files.copy的速度比FileInputStream慢啊...
(3)1G目录

对于目录的话可以考虑放弃BufferedReader与FileReader了,除非全部是文本文件,否则推荐使用BufferedInput/OutputStream与Files.copy()进行复制,工具类FileUtils的复制方法表现还是不错的,但相比起java标准的Files.copy效率都差了. 对于FileChannel与配合缓冲使用的FileChannel,1G的话好像不相上下. 遍历方式的话...可以看到plexus的遍历方法表现差距很大,而apache的listFiles或者java nio的walkFileTree比较稳定且速度还可以,推荐使用这两种方式遍历目录.
(4)10G目录
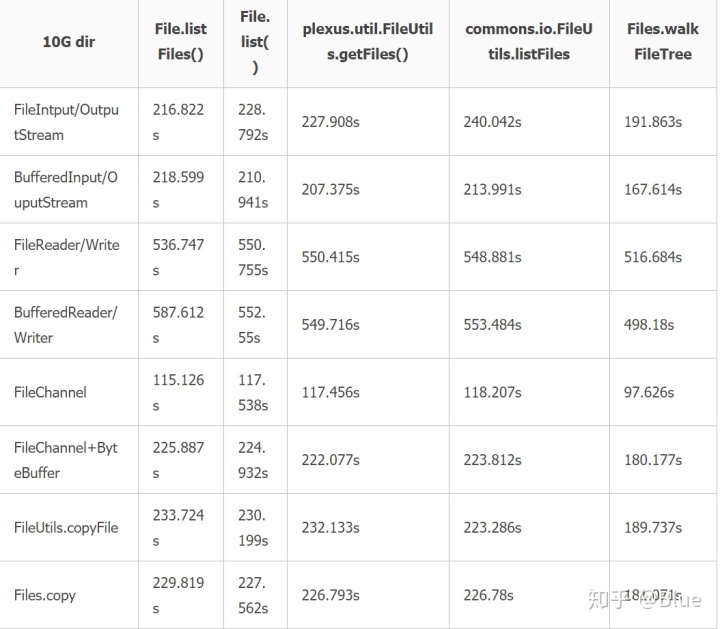
FileReader与BufferedReader这两行可以忽略了.对于小文件用FileChannel的话还是不错的,对于大文件一定要用FileChannel的话可以配合ByteBuffer使用,不过从数据上看效果比BufferedInput/OutputStream要低. 再看看org.apache.commons.io.FileUtils与java.nio.file.Files的copy,差别不太,效果接近,但在1G的时候差距有点大. 遍历方式的话,java nio的walkFileTrees最快.
当然这些测试仅供参考,具体使用哪一个要看看具体环境,另外这种方式把遍历与复制分开,apache的FileUtils有方法可以直接复制目录的,因此,使用哪个更合适还需要个人具体测试.
8.源码
作者比较偷懒全部仍在一个文件了.七百行.
import 














 2116
2116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









