






<阿甘正传>里曾有这样一句话:"你以后想成为什么样的人?"
回答是:"什么意思?难道我以后不能成为我自己吗?"
XML 概念:
XML 指可扩展标记语言(EXtensible Markup Language)
XML 没有预定义标签,需要自行定义标签
XML作用: 数据存储和数据传输
XML的特点
XML 数据以纯文本格式存储
实现不同应用程序之间的数据通信
实现不同平台间的数据通信
实现不同平台间的数据共享
使用 XML 将不同的程序、不同的平台之间联系起来
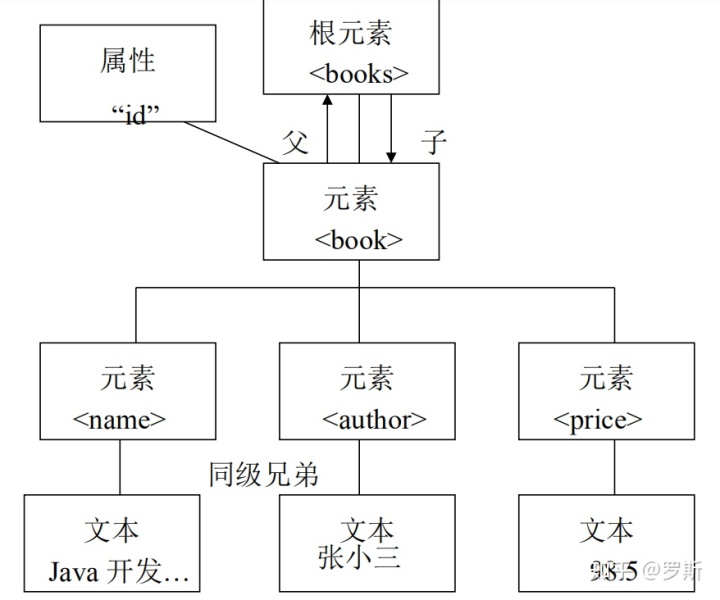
一个标准的XML文档组成由:
一个根元素(且只有一个)
一个或多个子元素
属性(id)
文本(只有字符型)
ML的命名规则:
1) 名称可以包含字母、数字及其他字符
2)名称不能以数字或者标点符号开始
3)名称不能以字母xml开始
4)名称不能包含空格
一个标准的 XML 文档
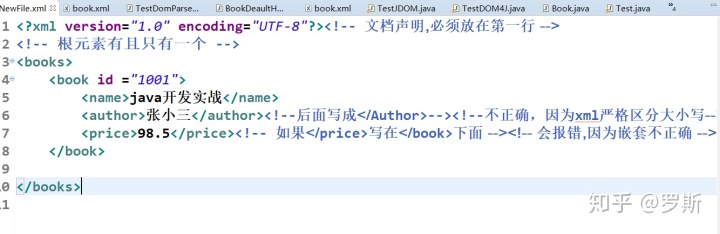
关系图
XML的基本语法
1)有且只有一个根元素
2) XML 文档声明必须放在文档的第一行
3) 所有标签必须成对出现
4) XML 的标签严格区分大小写
5) XML 必须正确嵌套
6) XML 中的属性值必须加引号
7) XML 中,一些特殊字符需要使用“实体”
8) XML 中可以应用适当的注释
XML 和 HTML 之间的差异
XML 主要作用是数据存储和传输(传输)
HTML 主要作用是用来显示数据(显示)
Schema 技术
用来验证XML技术是否有效有两种方式: 1.DTD 2.Schema技术
DTD
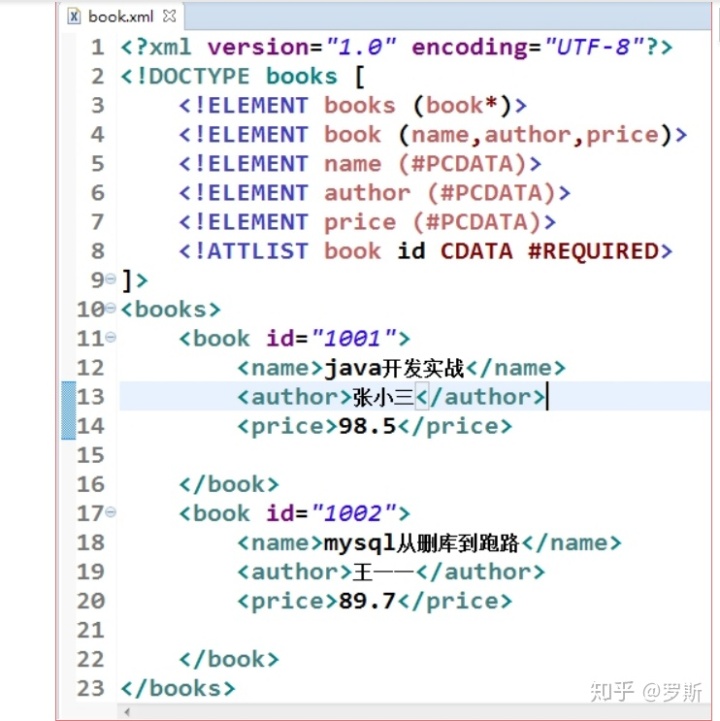
使用 DTD 的局限性
1) DTD 不遵守 XML 语法
2) DTD 数据类型有限
3) DTD 不可扩展
4) DTD 不支持命名空间
Schema技术
Schema 是 DTD 的代替者,名称为 XML Schema,用于描述XML 文档结构,比 DTD 更加强大,最主要的特征之一就是XML Schema 支持数据类型
Schema 的文档结构

所有的 Schema 文档使用 schema 作为其根元素
http://www.w3.org/2001/XMLSchema:用于验证当前 Schema文档的命名空间(用于验证Schema本身)
元素和数据类型应该使用前缀 xs:xmlns 相当于 java 中的 import, :xs“小名”,在使用时要写加"小名"做前缀
注意:(XML 使用 Schema 验证,那 Schema 也是一个 XML,那么谁来验证它?是DTD)
验证步骤
1) 创建 SchemaFactory 工厂
2) 建立验证文件对象
3) 利用 SchemaFactory 工厂对象,接收验证的文件对象,生成 Schema 对象
4) 产生对此 schema 的验证器
5) 要验证的数据(准备数据源)
6) 开始验证
解析 XML 文件
在 Java 程序中读取 XML 文件的过程称为解析 XML
解析 XML 文件的方式
1) DOM 解析 (java 官方提供)
2) SAX 解析(java 官方提供)
3) JDOM 解析(第三方提供)
4) DOM4J 解析(第三方提供)
DOM解析XML的步骤:
1) 创建一个 DocumentBuilderFactory 的对象
2) 创建一个 DocumentBuilder 对象
3) 通过DocumentBuilder的parse(...)方法得到Document对象
4) 通过 getElementsByTagName(...)方法获取到节点的列表
5) 通过 for 循环遍历每一个节点
6) 得到每个节点的属性和属性值
7) 得到每个节点的节点名和节点值
创建一个XML文件,后面的SAX,JDOM,DOM4J,XPATH用的都是这个文件
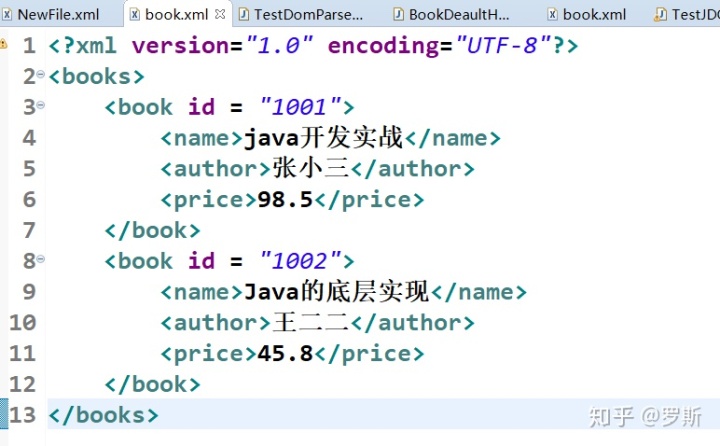
程序图:

运行结果:

SAX解析:
SAX,全称 Simple API for XML,是一种以事件驱动的XMl API,SAX 与 DOM 不同的是它边扫描边解析,自顶向下依次解析,由于边扫描边解析,所以它解析 XML 具有速度快,占用内存少的优点
SAX解析XML的步骤:
1) 创建 SAXParserFactory 的对象
2) 创建 SAXParser 对象 (解析器)
3) 创建一个 DefaultHandler 的子类
4) 调用 parse 方法
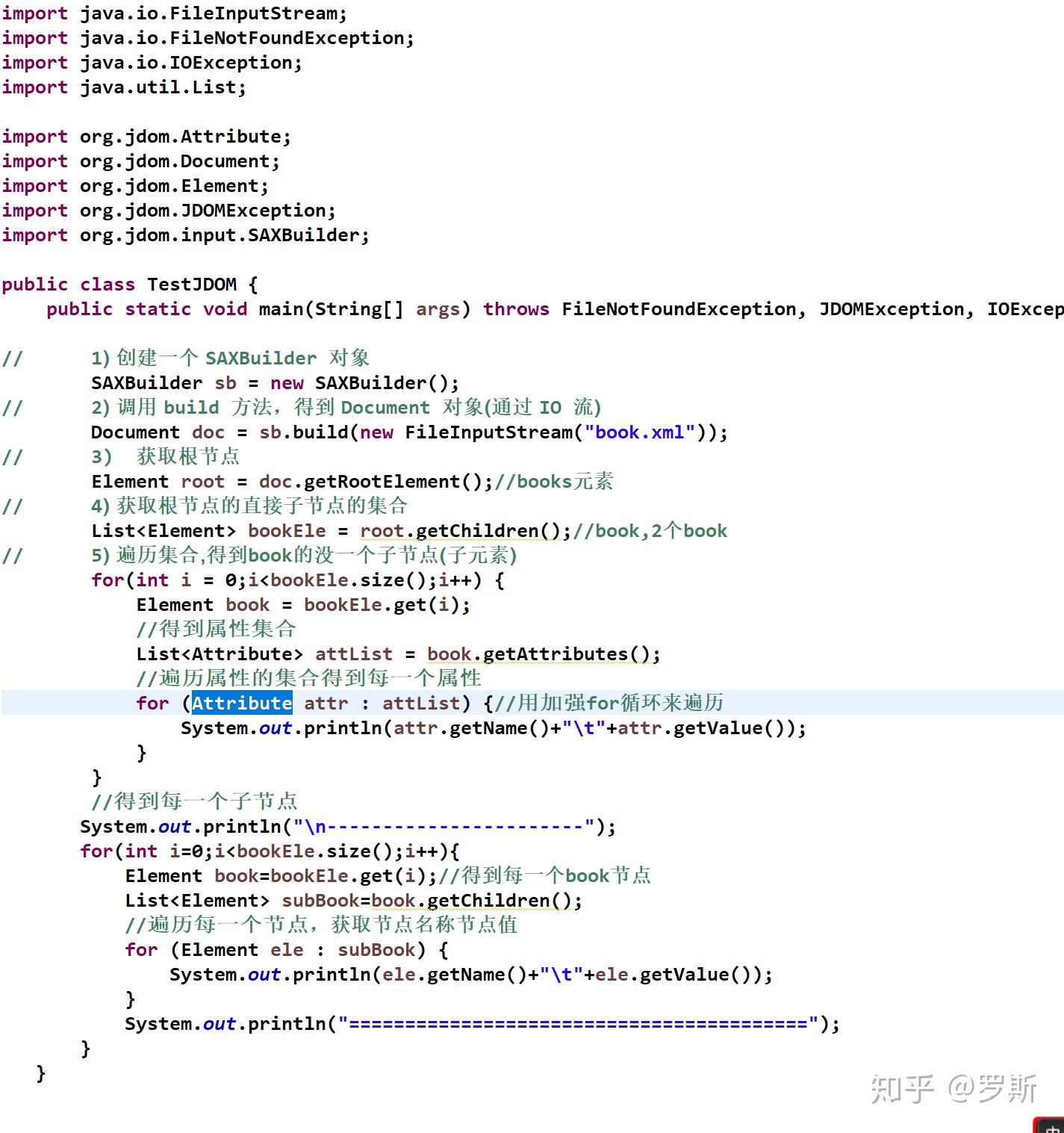
JDOM解析:
JDOM 是一种解析 XML 的 Java 工具包,它基于树型结构,利用纯Java的技术对XML文档实现解析。所以中适合于Java语言
DOM解析XML的步骤:
1) 创建一个 SAXBuilder 对象
2) 调用 build 方法,得到 Document 对象(通过 IO 流)
3) 获取根节点
4) 获取根节点的直接子节点的集合
5) 遍历集合
程序图:

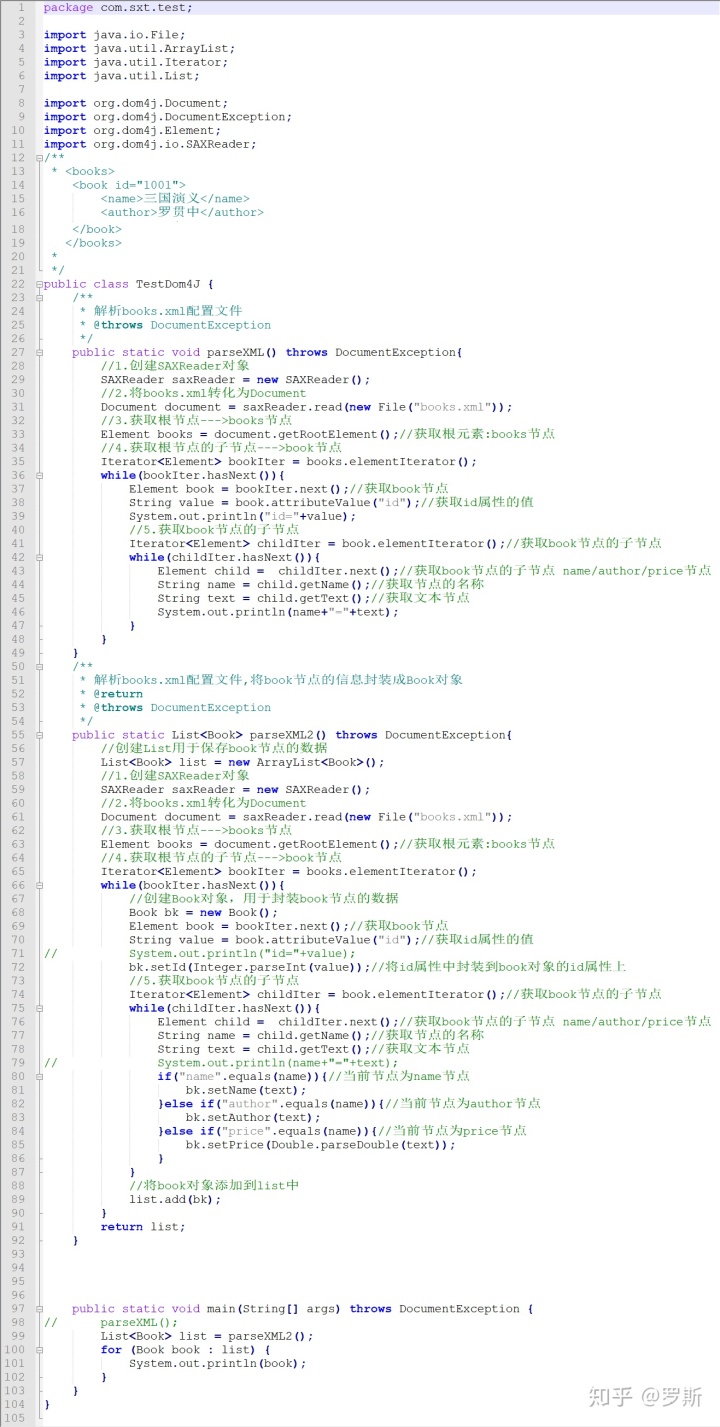
*** DOM4J解析XML:
DOM4J 是一个 Java 的 XML API,是 JDOM 的升级品,用来读写 XML 文件的
解析XML的步骤
1) 创建 SAXReader 对象
2) 调用 read 方法
3) 获取根元素
4) 通过迭代器遍历直接节点
运行图:

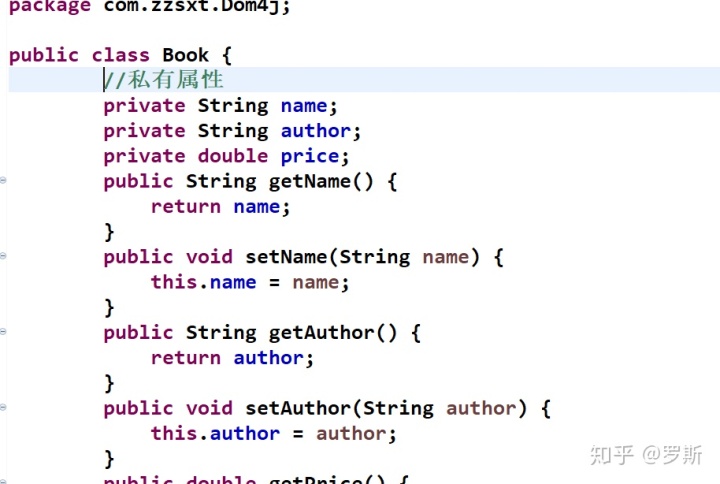
Book对象
运行结果:

四种解析XML技术的特点:
1)DOM 解析:
形成了树结构,有助于更好的理解、掌握,且代码容易编写。
解析过程中,树结构保存在内存中,方便修改。
2)SAX 解析: 逐行顺序解析
采用事件驱动模式,对内存耗费比较小。
适用于只处理 XML 文件中的数据时
3)JDOM 解析:
仅使用具体类,而不使用接口。
API 大量使用了 Collections 类。
4)DOM4J 解析:
JDOM 的一种智能分支,它合并了许多超出基本 XML 文档
表示的功能。
它使用接口和抽象基本类方法。
具有性能优异、灵活性好、功能强大和极端易用的特点。
是一个开放源码的文件
XPATH技术----快速的获取节点
需要准备资源:
1) DOM4J 的 jar 包
2) Jaxen 的 jar 包
3) Xpath 中文文档
程序图:

运行结果:

课堂代码:
XML文档内容

程序图:
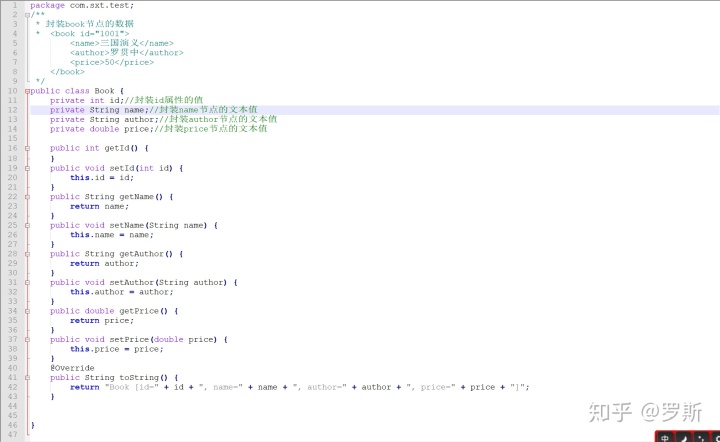
封装Book对象图














 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









