





一、数据集特点分析
数据集中的数据分为两部分,一部分是用来训练算法模型的数据,一部分是用来评估算法的新数据。网站上还提供了3个数据集,这里采用 20news-bydate 这个数据进行项目研究。这个数据集是按照日期进行排序的,并去掉了部分重复数据和header,共包含18846个文档。
二、导入数据
导入项目所需的类库,并使用scikit-learn的loadfiles导入文档数据,文档是按照不同的分类分目录来保存的,文件目录名称即所属类别,文件目录结构如下图所示。
2.1 导入类库
导入在项目中将要使用的类库和方法。代码如下:
#导入类库from sklearn.datasets import load_filesfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.svm import SVCfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import classification_reportfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import KFoldfrom sklearn.model_selection import GridSearchCVfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn.ensemble import RandomForestClassifierfrom matplotlib import pyplot as plt所有类库的导入确保无误方可进行下一步操作,若有错误提示,先纠错或检查编程环境配置以及类库安装是否有问题。
2.2 导入数据集
首先下载文本数据集,下载完成后,再保存在项目的统计目录中。数据集下载链接地址如下:http://www.qwone.com/~jason/20Newsgroups/

导入文档数据,代码如下:
#导入数据categories =['alt.atheism', 'rec.sport.hockey' 'comp.graphics', 'sci.crypt', 'comp.os.ms-windows.misc', 'sci.electronics', 'comp.sys.ibm.pc.hardware', 'sci.med', 'comp.sys.mac.hardware', 'sci.space', 'comp.windows.x', 'soc.religion.christian', 'misc.forsale', 'talk.politics.guns', 'rec.autos', 'talk.politics.mideast', 'rec.motorcycles', 'talk.politics.misc', 'rec.sport.baseball', 'talk.religion.misc']#导入训练数据train_path = '20news-bydate-train'dataset_train = load_files(container_path=train_path,categories=categories)#导入评估数据集test_path = '20news-bydate-test'dataset_test = load_files(container_path=test_path,categories=categories)利用机器学习对文本进行分类,与对数值特征进行分类最大的区别是,对文本进行分类时要先提取文本特征,相对于之前的项目来说,提取到的文本特征属性的个数是巨大的,会有超过万个的特征属性,甚至会超过10万个。
三、文本特征提取
文本数据属于非结构化的数据,一般要转换成结构化的数据才能够通过机器学习算法进行文本分类。常见的做法是将文本转换成“文档-词项矩阵”,矩阵中的元素可以使用词频或TF-IDF值等。
TF-IDF值是一种用于信息检索与数据挖掘的常用加权技术。TF的意思是词频(Term Frequency),IDF的意思是逆向文件频率(Inverse Document Frequency)。TF-IDF的主要思想是:如果一个词或者短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适用于分类。TF-IDF实际上是TF*IDF。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其他类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值小,这说明该词条能够很好地代表这个类的文本特征,这样的词条应该被赋予较高的权重,并将其作为该类文本的特征词,以区别于其他类文档。这就是IDF的不足之处,在一份给定的文件里,TF指的是某一个给定的词语在该文件中出现的频率,这是对词数(Term Count)的归一化,以防止它偏向长的文件。IDF是一个词语普遍重要性的度量,某一个特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
在scikit-learn中提供了词频和TF-IDF来进行文本特征提取的实现,分别是CountVectorizer和TfidTransformer。下面对训练数据集分别进行词频和TF-IDF的计算。代码如下:
#数据准备与理解#计算词频count_vect = CountVectorizer(stop_words='english',decode_error='ignore')X_train_counts=count_vect.fit_transform(dataset_train.data)#查看数据维度print(X_train_counts.shape)answer:

词频计算结果如上。
接下来计算一下TF-IDF,代码如下:
#计算TF-IDFtf_transformer = TfidfVectorizer(stop_words='english',decode_error='ignore')X_train_counts_tf = tf_transformer.fit_transform(dataset_train.data)#查看数据维度print(X_train_counts_tf.shape)TF-IDF的计算结果如下:

这里通过两种方法进行了文本特征的提取,并且查看了数据维度,得到的数据维度还是非常巨大的。在后续的项目中,将使用TF-IDF进行分类模型的训练。因为,TF-IDF的数据维度巨大,并且自用提取的特征数据,进一步对数据进行分析的意义不大,因此只简单地查看数据维度的信息。接下来将进行算法评估。
四、评估算法
在这里将采用10折交叉验证来评估算法模型的准确度。10折交叉验证是随机地将数据分成10份:9份用来训练模型,1份用来评估算法。代码如下:
#设置评估算法的基准num_folds=10seed=7scoring='accuracy'接下来将会利用提取到的文本特征TF-IDF来对算法进行审查,审查的算法如下。
·逻辑回归(LR)。
·分类与回归树(CART)。
·支持向量机(SVM)。
·朴素贝叶斯分类器(MNB)。
·K近邻算法(KNN)。
这个算法列表中包含了线性算法(LR)和非线性算法(CART、SVM、MNB和KNN)。代码如下:
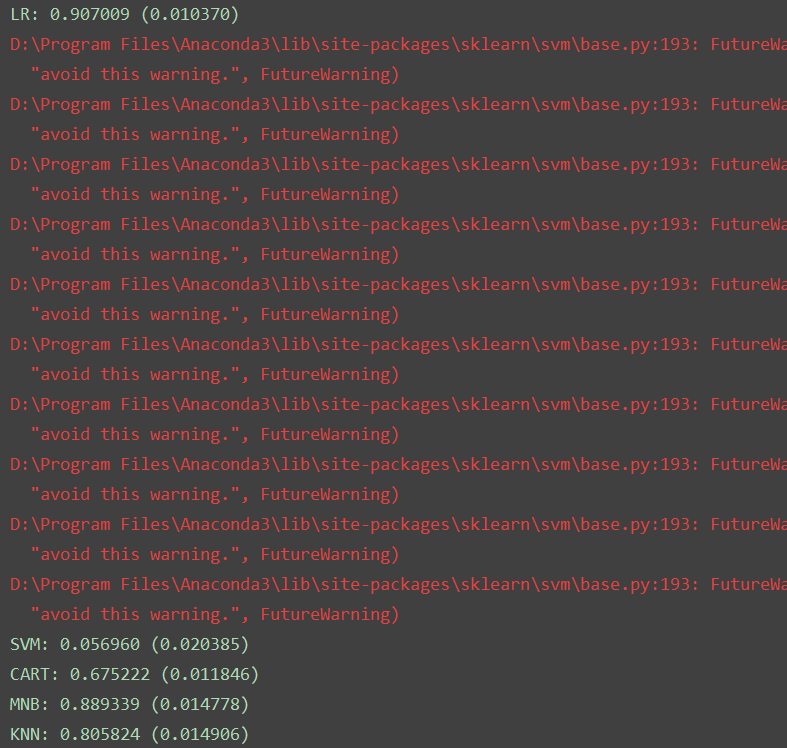
# 评估算法# 生成算法模型models ={}models['LR'] = LogisticRegression()models['SVM'] = SVC()models['CART'] = DecisionTreeClassifier()models['MNB'] =MultinomialNB()models['KNN'] = KNeighborsClassifier()#比较算法results = []for key in models: kfold = KFold(n_splits=num_folds, random_state=seed) cv_results = cross_val_score(models[key], X_train_counts_tf, dataset_train.target, cv=kfold, scoring=scoring) results.append(cv_results) print('%s: %f (%f)' % (key, cv_results.mean(), cv_results.std()))执行结果显示,逻辑回归(LR)具有最好的准确度,朴素贝叶斯分类器(MNB)和K近邻(KNN)也值得进一步的研究。执行结果如下:
这只是K折交叉验证给出的平均统计结果,通常还要看算法每次得出的结果的分布状况。在这里使用箱线图来显示数据的分布状况。代码如下:
#评估算法--箱线图fig=pyplot.figure()fig.suptitle('Algorithm Comparison')ax=fig.add_subplot(111)pyplot.boxplot(results)ax.set_xticklabels(models.keys())pyplot.show()answer:
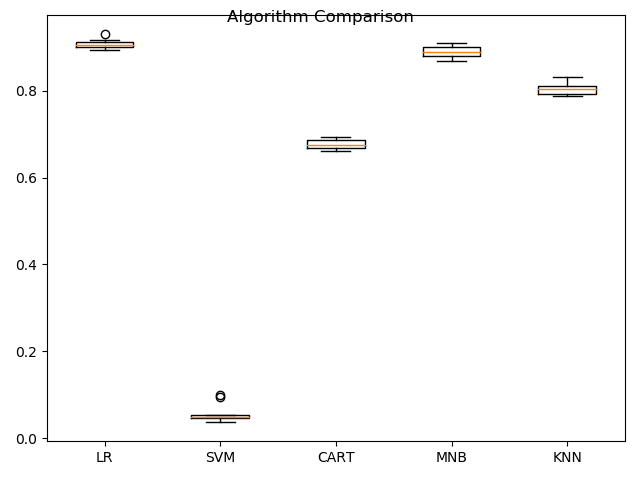
执行结果显示,朴素贝叶斯分类器的数据离散程度比较好,逻辑回归的偏度较大。算法结果的离散程度能够反应算法对数据的适用情况,所以对逻辑回归和朴素贝叶斯分类器进行进一步研究,实行算法调参。
五、算法调参
通过上面的分析发现,逻辑回归(LR)和朴素贝叶斯分类器(MNB)算法值得进一步进行优化。下面对这两个算法的参数进行调参,进一步提高算法的准确度。
5.1 逻辑回归调参
在逻辑回归中的超参数是C。C是目标的约束函数,C值越小则正则化强度越大。对C进行调参,每次给C设定一定数量的值,如果临界值是最优参数,重复这个步骤,直到找到最优值。代码如下:
#算法调参#调参LRparam_grid ={}param_grid['C']=[0.1,5,13,15]model=LogisticRegression()kfold=KFold(n_splits=num_folds,random_state=seed)grid=GridSearchCV(estimator=model,param_grid=param_grid,scoring=scoring,cv=kfold)grid_result=grid.fit(X_train_counts_tf,y=dataset_train.target)print('最优:%s使用%s' %(grid_result.best_score_,grid_result.best_params_))answer:
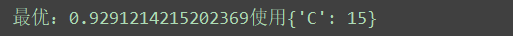
可以看到C的最优参数是15(15是通过多次调整param_grid参数得到的)。
5.2 朴素贝叶斯分类器调参
通过对逻辑回归调参,准确度提升到大概0.92,提升还是比较大的。朴素贝叶斯分类器有一个alpha参数,该参数是一个平滑参数,默认值为1.0。我们也可以对这个参数进行调参,以提高算法的准确度。代码如下:
#调参MNBparam_grid={}param_grid['alpha']=[0.001,0.01,0.1,1.5]model=MultinomialNB()kfold=KFold(n_splits=num_folds,random_state=seed)grid=GridSearchCV(estimator=model,param_grid=param_grid,scoring=scoring,cv=kfold)grid_result=grid.fit(X_train_counts_tf,y=dataset_train.target)print('最优:%s使用%s' %(grid_result.best_score_,grid_result.best_params_))answer:
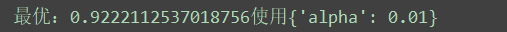
同样,通过多次调整param_grid,得到朴素贝叶斯分类器的alpha参数的最优值是0.01。
通过调参发现,逻辑回归在C=15时具有最好的准确度。接下来审查集成算法。
六、集成算法
除调参之外,提高模型准确度的方法是使用集成算法。下面对以下两种集成算法进行比较,来看看能否进一步提高模型的准确度。
·随机森林(RF)。
·AdaBoost(AB)。
集成算法的评估代码如下:
#集成算法ensembles={}ensembles['RF']=RandomForestClassifier()ensembles['AB']=AdaBoostClassifier()#比较集成算法results=[]for key in ensembles: kfold = KFold(n_splits=num_folds, random_state=seed) cv_results = cross_val_score(ensembles[key],X_train_counts_tf,dataset_train.target,cv=kfold,scoring=scoring) results.append(cv_results) print('%s :%f (%f)' % (key,cv_results.mean(),cv_results.std()))answer:
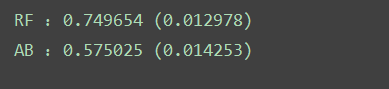
接下来通过箱线图看一下算法结果的离散情况。代码如下:
#集成算法--箱线图fig=pyplot.figure()fig.suptitle('Algorithm Comparison')ax=fig.add_subplot(111)pyplot.boxplot(results)ax.set_xticklabels(ensembles.keys())pyplot.show()answer:
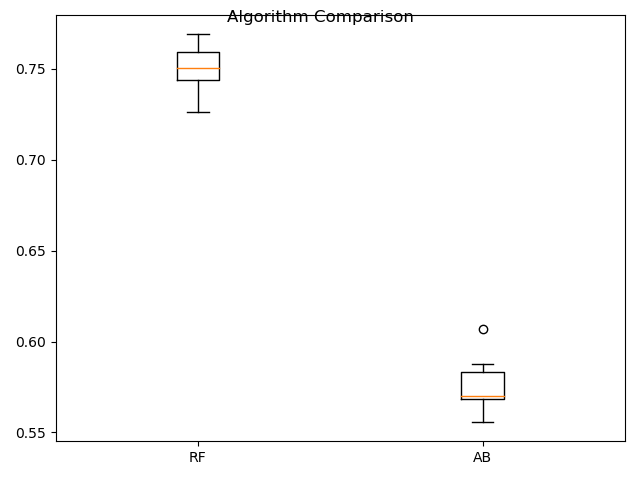
从箱线图可以看到随机森林(RF)的分布比较均匀,对数据的适用性比较高,更值得进一步优化研究。
七、集成算法调参
通过对集成算法的分析,发现随机森林算法具有较高的准确度和非常稳定的数据分布,非常值得进一步的研究。下面通过调参对随机森林算法进行优化。
随机森林有一个很重要的参数n_estimators,这是一个很好的可以用来调整的参数。对于集成参数来说,n_estimators会带来更准确的结果,当然这也有一定的限度。下面对n_estimators 进行调参优化,争取找到最优解。代码如下:
#调参RFparam_grid={}param_grid['n_estimators']=[10,100,150,200]model=RandomForestClassifier()kfold=KFold(n_splits=num_folds,random_state=seed)grid=GridSearchCV(estimator=model,param_grid=param_grid,scoring=scoring,cv=kfold)grid_result=grid.fit(X_train_counts_tf,y=dataset_train.target)print('最优:%s使用%s' %(grid_result.best_score_,grid_result.best_params_))answer:

八、确定最终模型
由前面对算法的评估发现,逻辑回归(LR)算法具有最佳的准确度。所以将会采用逻辑回归(LR)算法,通过训练数据生成算法模型。接下来会利用评估数据集对生成的模型进行验证,以确认模型的准确度。需要注意的是,为了保持数据特征的一致性,对新数据进行文本特征提取时应进行特征扩充,下面使用之前生成的tf_transformer的transform方法来处理评估数据集。代码如下:
#生成模型model=LogisticRegression(C=15)model.fit(X_train_counts_tf,dataset_train.target)X_test_counts=tf_transformer.transform(dataset_test.data)predictions=model.predict(X_test_counts)print(accuracy_score(dataset_test.target,predictions))print(classification_report(dataset_test.target,predictions))answer:
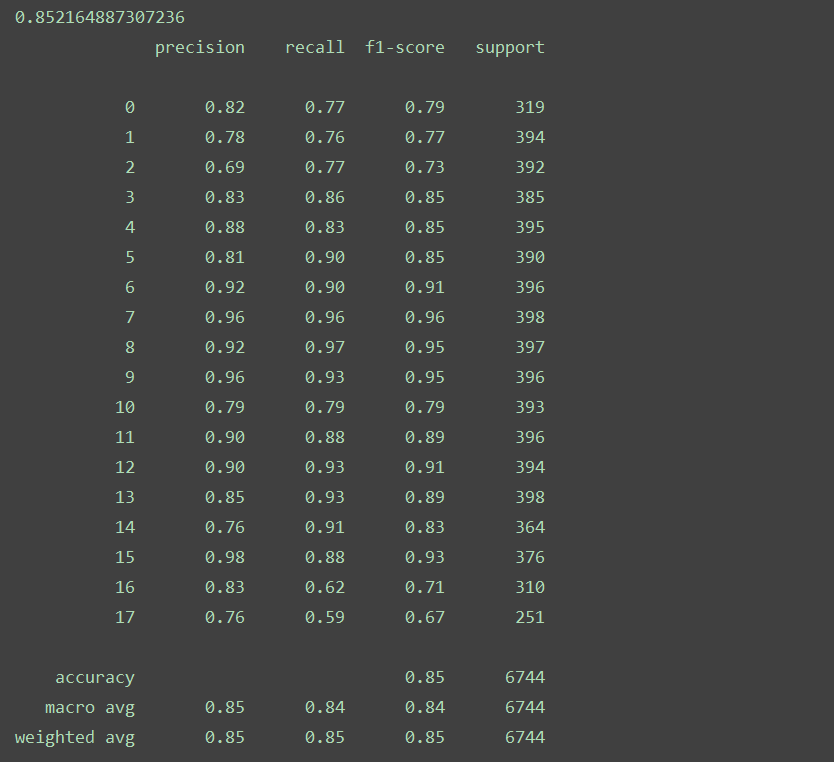
从执行结果可以看到,准确度大概达到了85.22%,差不多符合预期。
九、总结
本项目实例从问题定义开始,直到最后的模型生成为止,完成了一个文本分类项目,这类问题可以应用在垃圾邮件自动分类、新闻分类等方面。
在文本分类中很重要的一点是文本特征提取,在进行文本特征提取时可以进一步优化,以提高模型的准确度。
另外,对中文的文本分类,需要先进行分词,然后利用 sklearn.datasets.base.Bunch 将分词之后的文件加载到scikit-learn中,在运用机器学习处理问题时,需要灵活处理已经掌握的知识,寻找问题的解决方案。

想法丨发现丨科技丨人文
让阅读成为习惯,让灵魂拥有温度















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









