





上一文 讨论了FIR滤波器的结构以及使用Python从两个方面(循环运算和矩阵运算)实现FIR,而文中提到的单片机,只需要按照循环运算的方法就可以实现FIR滤波器。
所以,单片机实现FIR滤波器并不复杂;奈何我手痒了,想舍弃掉FIR IP核,用Verilog自己写一个FIR。不知道大家有没有这样手痒的感觉,如果有,跟随这篇文章一起来,看完记得点赞。
本文内容涉及Verilog的语法:function,generate for,generate if, readmemb,readmemh;部分Python语法以及学习Verilog)及计算机数值表示规则。
设计思想
首先需要把FIR最基本的结构实现,也就是每个FIR抽头的数据与其抽头系数相乘这个操作。由顶层文件对这个基本模块进行多次调用。
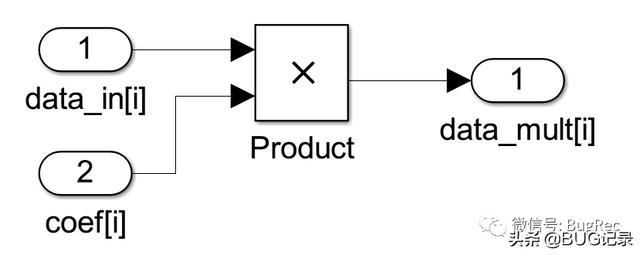
由于FIR抽头系数是中心对称的,为了减少乘法在FPGA内的出现,每个基本结构同时会输入两个信号,也是关于中心对称的。
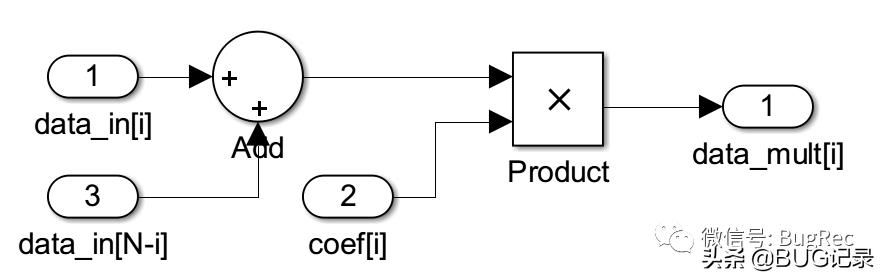
此外,为了防止后续相加的过程引起符号位溢出,FIR基本模块需要对乘法结果进行符号位扩展。
扩展完成后,如果同时对这些(71个)加权结果相加,肯定会使得系统运行速率上不去,而且设计的比较死板。这里需要引入流水线操作;何为流水线操作,简单地说,本来你一个人承担一桌菜,你需要洗菜,切菜,炒菜,装盘,上桌,不仅十分麻烦而且很耽误时间;这个时候有人过来帮你,一个人洗菜,一个人切菜,一个人炒菜,一个人装盘,你负责上桌,虽然费了些人,但是每个人的任务都比较轻松所以做事速度也很快,这就是流水线操作,把一件很复杂的事情划分成N个小事,虽然牺牲了面积但换取了系统运行时钟的提升。
前期准备
除了Verilog模块,我们还有几样东西需要准备。首先,需要将FIR抽头系数定点化,上一文使用的FIR抽头系数都是很小的浮点数,为此,我们直接对每个系数乘以2的15次幂,然后取整数,舍去小数位,设定FIR抽头系数位宽为16bit;因为系数本身比较小,不担心会溢出。注意,这里抽头系数的位宽尽量不超过信号位宽,否则可能会有问题。
为了方便多个模块同时调用FIR系数,这里使用Python直接将定点化的系数生成为function,输入为index,需要第N阶的FIR系数,就调用function,输入参数为N,输出为定点化的系数。
所谓定点化,这里使用的方法十分粗暴,直接对所有浮点数,乘以一个2的n次幂。然后对参数向下取整,舍弃小数位。
FIR浮点系数转化为定点数并生成function的代码如下:
def coef2function(filename, exp, gain): # :param filename: FIR抽头系数文件名 # :param exp: 浮点数转定点数的位宽 # :param gain: 浮点数整体的增益,增益为power(2, gain) # :return: coef = set_coef(filename) with open('fir_coef.v', 'w') as f:f.write('function [{}:0] get_coef;'.format(exp-1)) f.write('input [7:0] index;') f.write('case (index)') for i in range(len(coef)): f.write('{}: get_coef = {};'.format(i,int(np.floor(coef[i] * np.power(2,gain))))) f.write('default: get_coef = 0;') f.write('endcaseendfunction')转换生成的function示例如下:
function [15:0] get_coef;input [7:0] index;case (index)0: get_coef = 0;1: get_coef = 0;2: get_coef = 2;3: get_coef = 10;...69: get_coef = 10;70: get_coef = 2;71: get_coef = 0;72: get_coef = 0;default: get_coef = 0;endcaseendfunction这样,当多个基本模块并行运行时,每个模块的系数可以通过调用function获取对应的参数。
仿真需要有信号源供FIR滤波,所以直接将仿真用的信号源定点化;因为Testbench中使用readmemh或者readmemb读取txt文档数据,只能读取二进制或16进制数据,所以需要对数据进行二进制或16进制转换。
信号源选取上一文的信号源,由于该信号源最大值为3,设定信号源的位宽为16位,为防止数据溢出,信号源整体乘以2的12次幂,然后取整舍去小数位。为了方便后续转二进制,这里需要将数据由16bit有符号转为16bit无符号;转换的过程为,如果data[i]小于0,直接设定data[i] = 2^16 + data[i]。然后使用“{{:0>16b}}”.format(data[i])转换为16bit二进制,存入cos.txt。
浮点数转换定点数并转换二进制数据存入txt转换代码如下:
def float2fix_point(data, exp, gain, size): # ''' # :param data: 信号源数据 # :param exp: 浮点数转定点数的位宽 # :param gain: 浮点数整体乘以增益,增益为power(2,15) # :param size: 转换多少点数 # :return: # ''' if size > len(data): print("error, size > len(data)") return data = [int(np.floor(data[i] * np.power(2, gain) )) for i in range(size)] fmt = '{{:0>{}b}}'.format(exp) n = np.power(2, exp) for i in range(size): if data[i] > (n //2 - 1): print("error") if data[i] < 0: d = n + data[i] else: d = data[i] data[i] = fmt.format(d) np.savetxt('cos.txt', data, fmt='%s')实现方法
为了方便看示例代码,这里假定信号位宽DATA_BITS为16,系数位宽为COEF_BITS为16,扩展符号位宽EXTEND_BITS为5, 阶数FIR_ORDER为72。
设计思路还是从底层开始设计,首先需要实现FIR的基本模块。前面提到,为了节省乘法器,每个模块输入两个信号和一个FIR抽头系数,两个参数相加,相加结果直接乘以系数,最后做符号位扩展,防止后续操作导致符号位溢出。
fir_base.v 主要代码:
reg signed [DATA_BITS + COEF_BITS - 1:0] data_mult;// 因为FIR系数是中心对称的,所以直接把中心对称的数据相加乘以系数// 相加符号位扩展一位wire signed [DATA_BITS:0] data_in ;assign data_in = {data_in_A[DATA_BITS-1], data_in_A} + {data_in_B[DATA_BITS-1], data_in_B};// 为了防止后续操作导致符号位溢出,这里扩展符号位,设计位操作知识assign data_out = {{EXTEND_BITS{data_mult[DATA_BITS + COEF_BITS - 1]}},data_mult };always @(posedge clk or posedge rst) begin if (rst) begin // reset fir_busy <= 1'b0; data_mult <= 0 ; output_vld <= 1'b0; end else if (en) begin //如果coef为0,不需要计算直接得0 data_mult <= coef != 0 ? data_in * coef : 0; output_vld <= 1'b1; end else begin data_mult <= 'd0; output_vld <= 1'b0; endend完成了基本模块后,顶层模块就是调用基本模块,然后对运算结果进行相加操作。但这里需要注意,顶层首先需要73个16bit的寄存器,用来保存传入的信号并实现每时钟周期上升沿,73个数据整体前移;学过数据结构的同学可以把这个想象成队列结构,每次信号上升沿时,队首信号出队,队尾补进新的信号。
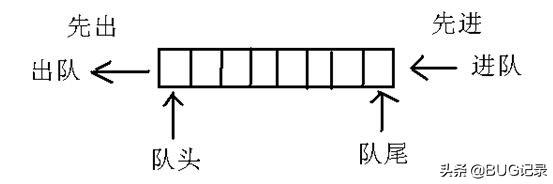
实现方法如下:
// FIR输入数据暂存寄存器组reg signed [DATA_BITS-1:0]data_tmp [FIR_ORDER:0] ;always @(posedge clk or posedge rst) beginif (rst) begin// resetdata_tmp[0] <=0;endelse if (data_in_vld) begindata_tmp[0] <=data_in;endendgenerategenvar j; for (j = 1; j <= FIR_ORDER; j = j + 1)begin: fir_base//这里无法兼顾0,FIR_HALF_ORDER always @(posedge clk or posedge rst) begin if (rst) begin // reset data_tmp[j] <=0; end else if (data_in_vld) begin data_tmp[j] <=data_tmp[j-1]; endendendgenerate这里实现了从0-72共73个寄存器,使用了Verilog的类似二维数组的寄存器定义用法。可以从代码看到,0号data_tmp过于特殊,需要保存输入的信号,而其他data_tmp直接使用generate for语法实现前面提到的“队列”功能。generate for语法是可以综合的,其中for循环的参数必须是常数,其作用就是直接在电路上复制循环体的内容。对于像这样需要规律性地赋值操作很方便,下面还会出现generate for语法。
寄存器组的问题解决后,需要与FIR参数进行乘加,这里同样适用generate for语句简化设计:
localparam FIR_HALF_ORDER = FIR_ORDER / 2; //36wire signed [OUT_BITS-1:0]data_out_tmp [FIR_HALF_ORDER:0] ;// FIR输出数据后流水线相加的中间变量,多出部分变量,防止下一级相加过程中index越界reg signed [OUT_BITS-1:0]dat_out_reg [FIR_HALF_ORDER+4:0] ; //40-0always @(posedge clk or posedge rst) beginif (rst) begin// resetdat_out_reg[FIR_HALF_ORDER] <= 0;endelse if (output_vld_tmp[FIR_HALF_ORDER]) begindat_out_reg[FIR_HALF_ORDER] <= data_out_tmp[FIR_HALF_ORDER];endendfir_base #(.DATA_BITS(DATA_BITS),.COEF_BITS(COEF_BITS),.EXTEND_BITS(EXTEND_BITS))fir_inst_FIR_HALF_ORDER(.clk(clk),.rst(rst), .en(data_in_vld), .data_in_A(data_tmp[FIR_HALF_ORDER]), .data_in_B(12'd0), .coef(get_coef(FIR_HALF_ORDER)), .fir_busy(), .data_out(data_out_tmp[FIR_HALF_ORDER]), .output_vld(output_vld_tmp[FIR_HALF_ORDER]) ); generategenvar j;for (j = 1; j < FIR_HALF_ORDER; j = j + 1)begin: fir_basefir_base#(.DATA_BITS(DATA_BITS),.COEF_BITS(COEF_BITS),.EXTEND_BITS(EXTEND_BITS))fir_inst_NORMAL(.clk(clk),.rst(rst),.en(data_in_vld),.data_in_A(data_tmp[j]),.data_in_B(data_tmp[FIR_ORDER-j]),.coef(get_coef(j)),.fir_busy(),.data_out(data_out_tmp[j]),.output_vld(output_vld_tmp[j]));always @(posedge clk or posedge rst) beginif (rst) begin// resetdat_out_reg[j] <= 0;endelse if (output_vld_tmp[j]) begindat_out_reg[j] <= data_out_tmp[j];endendendgenerate首先由于中心点(第36阶)的系数是只乘中心点,并不像其他系数可以传入关于中心对称的两个信号。所以FIR_HALF_ORDER需要单独例化。同样,dat_out_reg也需要单独复制;其他的信号在generate for循环体完成操作,由于0号系数在阶数为偶数的情况下为0,这里跳过0号系数直接从1号系数开始,所以for循环是从1 - FIR_HALF_ORDER。
加权结果出来后,需要对结果相加,为了提升系统运行速率,这里采用三级流水线操作。每次进行4位数据相加传递给下一级流水线,所以示例代码里FIR最高阶数为4 * 4 * 4 * 2 = 128。
流水线操作过程如下:
// 流水线第一级相加,计算公式ceil(N/4)localparam FIR_ADD_ORDER_ONE = (FIR_HALF_ORDER + 3) / 4; 流水线第二级相加,计算公式ceil(N/4)localparam FIR_ADD_ORDER_TWO = (FIR_ADD_ORDER_ONE + 3) / 4; //3reg signed [OUT_BITS-1:0]dat_out_A [FIR_ADD_ORDER_ONE+3:0] ;//12-0reg signed [OUT_BITS-1:0]dat_out_B [FIR_ADD_ORDER_TWO+3:0] ;//6-0// 这些多余的reg直接设为0就可以了always @ (posedge clk) begindat_out_reg[FIR_HALF_ORDER+1] = 0;dat_out_reg[FIR_HALF_ORDER+2] = 0;dat_out_reg[FIR_HALF_ORDER+3] = 0;dat_out_reg[FIR_HALF_ORDER+4] = 0;dat_out_A[FIR_ADD_ORDER_ONE] = 0;dat_out_A[FIR_ADD_ORDER_ONE+1] = 0;dat_out_A[FIR_ADD_ORDER_ONE+2] = 0;dat_out_A[FIR_ADD_ORDER_ONE+3] = 0;dat_out_B[FIR_ADD_ORDER_TWO] = 0;dat_out_B[FIR_ADD_ORDER_TWO + 1] = 0;dat_out_B[FIR_ADD_ORDER_TWO + 2] = 0;dat_out_B[FIR_ADD_ORDER_TWO + 3] = 0;end// 判定所有FIR_BASE模块完成转换assign data_out_vld = (&output_vld_tmp[FIR_HALF_ORDER:1] == 1'b1) ? 1'b1 : 1'b0;//最后一级流水线always @(posedge clk or posedge rst) beginif (rst) begin// resetdata_out <=0;endelse if (data_out_vld) begindata_out <= dat_out_B[0] + dat_out_B[1] + dat_out_B[2] + dat_out_B[3];endendgenerategenvar j;for (j = 1; j < FIR_HALF_ORDER; j = j + 1) if (j <= FIR_ADD_ORDER_ONE)begin//流水线相加 第一级//注意j 的范围是[1,FIR_HALF_ORDER]//所以dat_out_A[j-1]always @(posedge clk or posedge rst) beginif (rst) begin// resetdat_out_A[j-1] <= 0;endelse begindat_out_A[j-1] <= dat_out_reg[4*j-3] + dat_out_reg[4*j-2] + dat_out_reg[4*j-1] + dat_out_reg[4*j];endendend if (j <= FIR_ADD_ORDER_TWO)begin// 流水线相加 第二级always @(posedge clk or posedge rst) beginif (rst) begin// resetdat_out_B[j-1] <= 0;endelse begindat_out_B[j-1] <= dat_out_A[4*j - 4] + dat_out_A[4*j- 3] + dat_out_A[4*j - 2] + dat_out_A[4*j - 1];endendendendendgenerate这里第一级,第二级流水线的循环次数采用ceil(N/4)的计算方式,也就是取比N/4大的最小整数。比如5/4 = 1.25,则ceil(1.25) = 2, 而ceil(1) = 1;
定义每级寄存器组时,会多定义4个寄存器组。并且这些寄存器永远为0,这样做的原因以第一级流水线相加举例:
看第一级流水线,假定FIR_ORDER为70,FIR_HALF_ORDER为35,FIR_ADD_ORDER_ONE为9,当j为9时,dat_out_A[8] <= dat_out_reg[33] + dat_out_reg[34] + dat_out_reg[35] + dat_out_reg[36];
而我们在前面设计中正好定义了dat_out_reg[36],并且它永远为0,不影响最终结果。
可以看到,第一级,第二级流水线使用generate for, if语句。如果if条件成立,if内部的电路会被描述。最后71个数据经过三级流水线相加,结果输出。
如果想要提升FIR的最高运行频率,可以把流水线级数增加,每级流水线相加改为2个或者3个。
这个结构只适合FIR阶数为偶数的情况,由于最近比较忙,没有做更大的兼容性。
仿真结果与资源占用对比
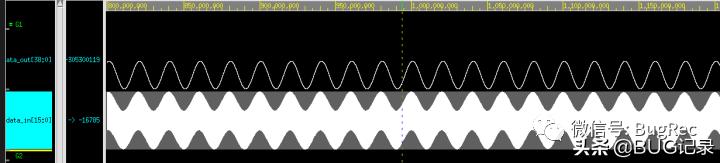
VCS仿真结果
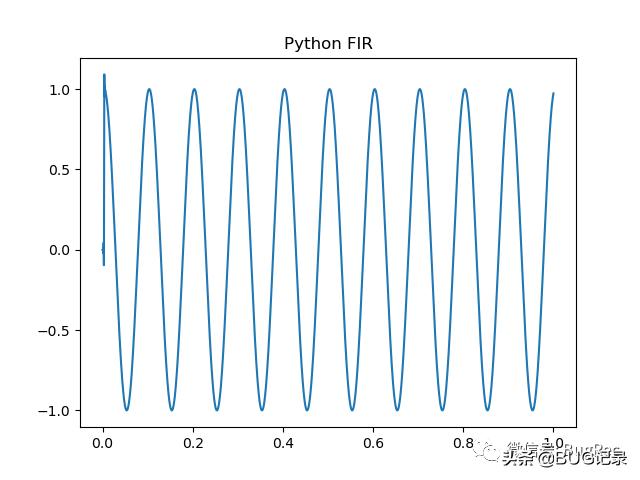
FIR滤波效果,Python
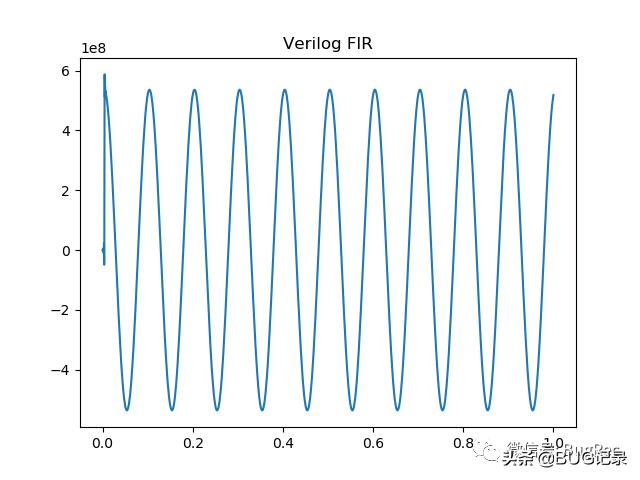
FIR滤波效果,Verilog
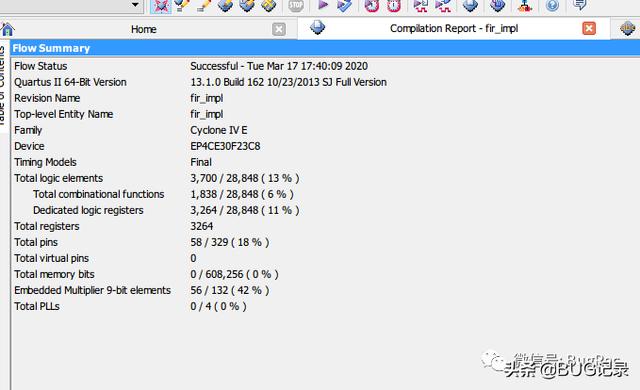
FIR_IMPLE的资源占用 Quartus II 13.1
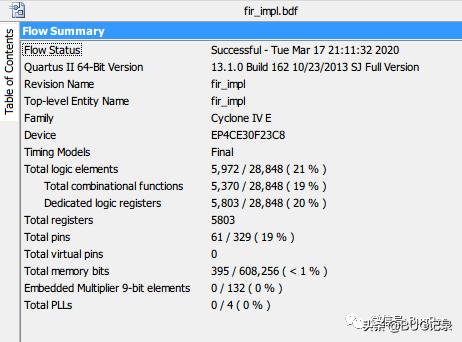
FIR IP核资源占用,参数相同情况下,Quartus II 13.1
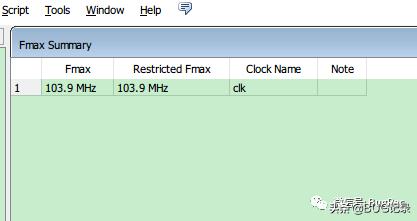
FIR_IMPLE的Fmax Quartus II 13.1
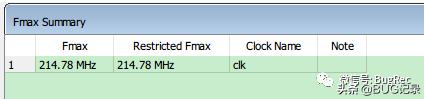
FIR IP核,Fmax, Quartus II 13.1
提升建议:
1. 提升最高运行速率,可以增多流水线操作
2. 可以修改部分代码适配阶数为奇数的情况
欢迎关注留言点赞收藏我,一同探讨FPGA/电子/硬件/软件。关于本文所用的资源会在评论区给出














 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









