





现在需要在json文件里面读取图片的URL和label,这里面可能会出现某些URL地址无效的情况。
python读取json文件
此处只需要将json文件里面的内容读取出来就可以了
with open("json_path",'r') ad load_f:
load_dict= json.load(load_f)
json_path是json文件的地址,json文件里面的内容读取到load_dict变量中,变量类型为字典类型。
python通过URL打开图片
通过skimage获取URL图片是简单的方式。
from skimage importio
image= io.imread(img_src) #img_src是图片的URL
io.imshow(image)
io.show()
pytorch构建自己的数据集
pytorch中文网中有比较好的讲解: https://ptorch.com/news/215.html
加载图片预处理以及可视化见: https://oldpan.me/archives/pytorch-transforms-opencv-scikit-image
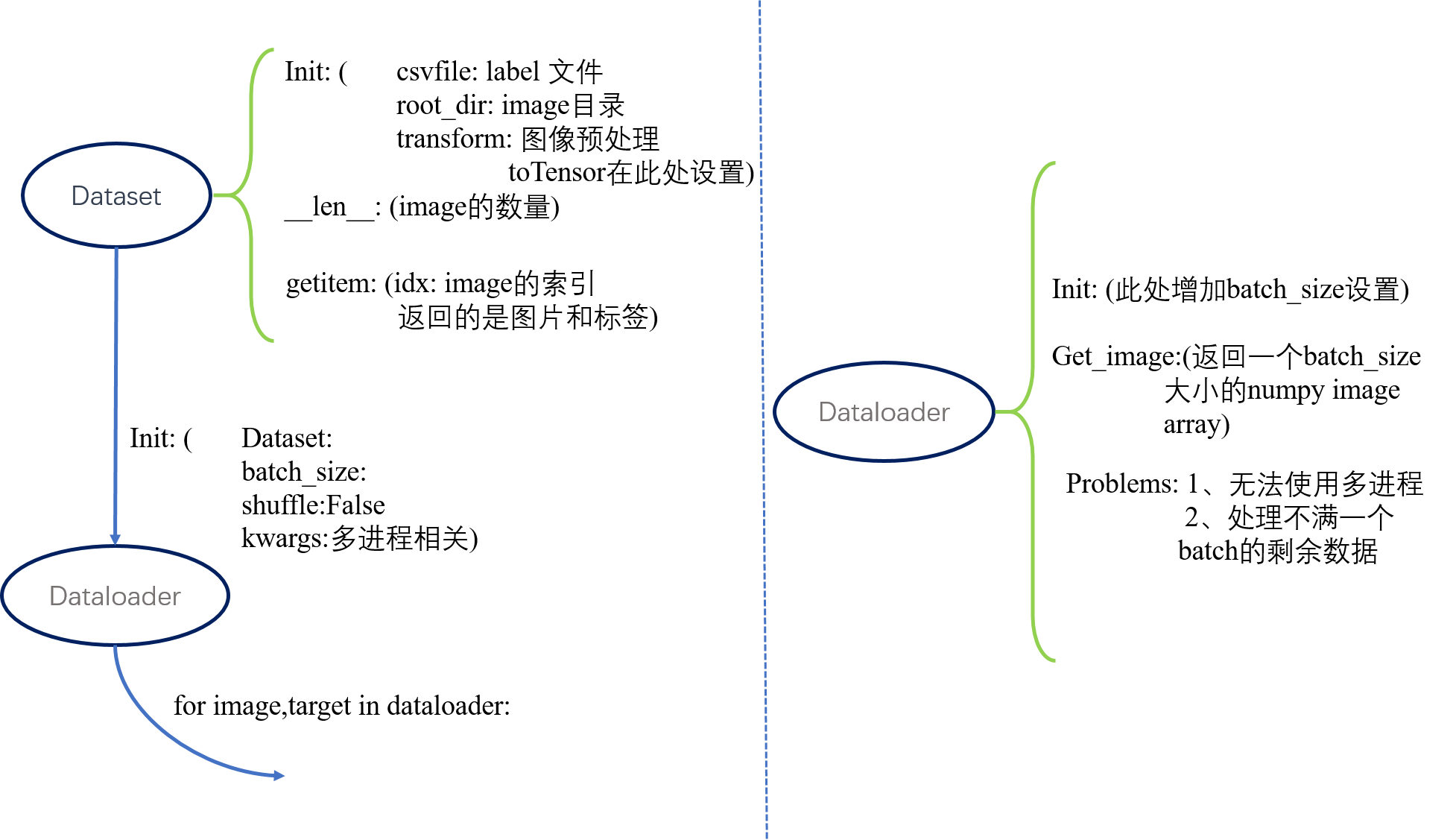
定义自己的数据集使用类 torch.utils.data.Dataset这个类,这个类中有三个关键的默认成员函数,__init__,__len__,__getitem__。
__init__类实例化应用,所以参数项里面最好有数据集的path,或者是数据以及标签保存的json、csv文件,在__init__函数里面对json、csv文件进行解析。
__len__需要返回images的数量。
__getitem__中要返回image和相对应的label,要注意的是此处参数有一个index,指的返回的是哪个image和label。
importtorchfrom torchvision importtransformsimportjsonimportosfrom PIL importImageclassProductDataset(torch.utils.data.Dataset):def __init__(self,json_path,data_path,transform = None,train =True):
with open(json_path,'r') as load_f:
self.json_dict=json.load(load_f)
self.json_dict= self.json_dict["images"]
self.train=train
self.data_path=data_path
self.transform=transformdef __len__(self):returnlen(self.json_dict)def __getitem__(self,index):
image_id= os.path.join(self.data_path + '/',str(self.json_dict[index]["id"]))
image=Image.open(image_id)
image= image.convert('RGB')
label= int(self.json_dict[index]["class"])ifself.transform:
image=self.transform(image)ifself.train:returnimage,labelelse:
image_id= self.json_dict[index]["id"]returnimage,label,image_idif __name__ == '__main__':
val_dataset= ProductDataset('data/FullImageTrain.json','data/train',train=False,
transform=transforms.Compose([
transforms.Pad(4),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
]))
kwargs= {'num_workers': 4, 'pin_memory': True}
test_loader= torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=32,
shuffle=False,**kwargs)print(val_dataset.__len__())
count=0for image,label,image_id intest_loader:print(image.shape,count)
count+= 1
关于transform,图像预处理的各个函数功能介绍如下:
torch.transforms是常见的图像变换,可以用Compose连接起来。
下面是Transforms on PIL Image:
transforms.CenterCrop(size):
size可以是一个像(h,w)的sequence,这样输出的是一个中心裁剪的(h,w)图像。
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0):
随机更改图像的亮度,对比度和饱和度。
传递的参数是float型变量或者是tuple(元素是float型)型变量,如果是tuple型变量,第一个元素是min值,第二个元素是max值。
transforms.Grayscale(num_output_channels=1)
将Image转换为灰度值
transforms.Pad(padding, fill=0, padding_mode='constant')
padding这个参数,如果给定的是单个的值,那么会pad所有的边。
transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
随机裁剪图片到给定尺寸
size如果是(h,w)这样的sequence,那么将剪出一个(h,w)大小的图片
transforms.RandomHorizontalFlip(p=0.5):
以给定的概率随机水平翻转给定的PIL图像。
transforms.RandomResizedCrop(size,scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
将给定的图像随机裁剪为不同的大小和高宽比,然后缩放所裁剪的图像到指定大小。
该操作的含义:即使只是该物体的一部分,我们也认为这是该类物体。
scale为0.08到1的意思为裁剪的面积比例为0.08到1,注意是面积不是边,ratio是高宽比。
transforms.Resize(size, interpolation=2):
Resize给定的Image图像到指定大小。
size:给定图像大小
interpolation:差值方法,默认是PIL.Image.BILINEAR
下面是Transforms on torch.*Tensor:
transforms.Normalize(mean,var,inplace=False):
标准化图像,mean和var给定三个值的情况下,是分别对于RGB三个channel进行标准化。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









