






什么是聚类
聚类可以将相似的样本归到同一簇中,是无监督学习中最常见的问题。聚类的结果是,簇内的对象越相似,聚类的效果就越好。一个簇的意思就是一个类别。
以人学习习题为例,仔细观察习题,就会发现高频出现运算符号的题目是数学题,高频出现英文字母的题目是英语题。如下图,这种将相似样本归到同一簇中的过程,并不依赖标准答案,这就是聚类。

聚类算法中,最经典的就是Kmeans 聚类了,也叫作 K 均值聚类,是最常用的聚类算法。

Kmeans 算法中的 K 表示的是,将样本聚为 K 个簇;Means 代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心。Kmeans 聚类算法,可以将输入数据聚合成 K 个簇并输出。
Kmeans 聚类算法
Kmeans聚类算法输入的内容包括,聚类目标 K 值和样本的集合。
执行算法的第一步是初始化。通常采用的策略是,在特征空间中,随机选 K 个点作为初始的质心。
第二步是归类和更新。具体来说,归类是对数据集中每个点而言,计算其与每个质点之间的距离,并将数据点分配到距离最近的质点所在的簇。更新是对每一个簇而言,计算簇中所有点的均值,并将均值作为新的质心替换掉原来的质心。
之后呢,就需要重复执行归类和更新的操作,直到某些停止条件满足。
Kmeans 算法的停止条件通常有以下 4 个,一般任意满足一点即可停止算法的主流程:
1)预先设置好迭代的轮数,一旦超过了迭代的最大轮数则停止迭代;
2)在某次循环中,没有数据点被重新分配到其他的簇,也就是算法已经收敛,则算法结束迭代;
3)某次循环,质心的位置没有发生改变,也是算法发生了收敛,则算法结束迭代;
4)某次循环,均方误差 SSE 递减的增量,小于预先设置的某个阈值,也就是这一次的迭代对聚类结果影响非常小,算法已经趋近于收敛,则算法结束迭代。SSE 的计算公式如下:
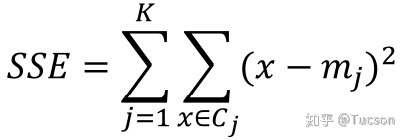
其中,K 表示 K 个簇,Cj 为簇 j 内数据样本的集合,mj 表示 Cj 簇的质心。这个公式的意思是,对每个簇计算每个数据点与其所归属的质心的距离平方和,再将所有簇的结果求和。随着 Km
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









