



 本文档详细介绍了Hadoop的单机版安装配置过程,包括下载安装包、配置公钥和启动Hadoop。接着讲述了Hive的安装配置步骤,包括下载Hive、配置环境和初始化元数据。在实际操作中遇到了Guava版本冲突和hive-site.xml文件读取错误的问题,并给出了相应的解决方法。
本文档详细介绍了Hadoop的单机版安装配置过程,包括下载安装包、配置公钥和启动Hadoop。接着讲述了Hive的安装配置步骤,包括下载Hive、配置环境和初始化元数据。在实际操作中遇到了Guava版本冲突和hive-site.xml文件读取错误的问题,并给出了相应的解决方法。
Hadoop安装配置
下载Hadoop二进制安装包
- 进入hadoop官网 ,点击 download按钮,跳转到下载页面:

,选择一个版本,点击binary,我选择的是3.1.3版本:
- 进入到下载页面,选择清华大学的镜像地址进行下载,这个速度比较快
- 下载好后,将安装包上传到服务器:linux上可通过rz命令进行上传,或者通过sftp上传
- 上传后解压缩:
tar -zxvf hadoop-3.1.3.tar.gz - 进行伪分布式/单机版配置:
- 配置 $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<!--指定文件系统为HDFS及NameNode主节点运行的机器端口和ip地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--本地临时存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-3.1.3/data/tmpData</value>
</property>
</configuration>- 配置 $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<!-- hdfs副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-3.1.3/data/tmpData/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/home/hadoop/hadoop-3.1.3/data/tmpData/dfs/data</value>
</property>
<!-- 开启权限,远程客户端可以通过脚本给hdfs创建目录 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>- 配置 $HADOOP_HOME/etc/hadoop/hadoopenv.sh,
- 配置 $HADOOP_HOME/etc/hadoop/mapred-env.sh,
- 配置 $HADOOP_HOME/etc/hadoop/yarn-env.sh: 均设置JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_231配置公钥
ssh-keygen -t rsa
cat .ssh/id_rsa.pub >> .ssh/authorized_keys启动hadoop
cd $HADOOP_HOME
#格式化namenode
bin/hadoop namenode -format
#启动
sbin/start-all.sh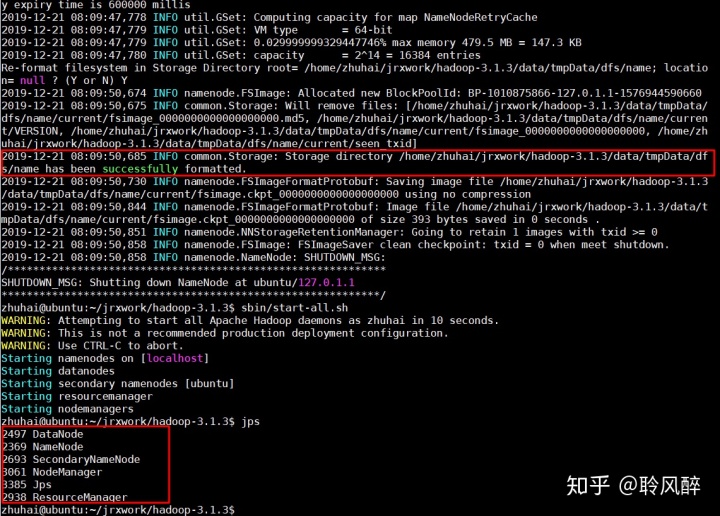
可以看到namenode和datanode进程都已启动.至此,单机版hadoop已经安装并成功启动!
hive安装配置
hive下载 & 配置
- 下载hive最新版:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz - 解压缩:
tar -zxvf apache-hive-3.1.2-bin.tar.gz - 配置hive:
$HIVE_HOME/bin/hive-config.sh
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hive/jrxwork/hadoop-3.1.3
export HIVE_HOME=/home/hive/jrxwork/apache-hive-3.1.2-bin$HIVE_HOME/hive-env.sh
HADOOP_HOME=/home/hive/jrxwork/hadoop-3.1.3$HIVE_HOME/hive-site.xml
<!--mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<!--指定资源目录和日志目录,下面需要依次创建这些目录 -->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/scratchdir</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/resourcesdir</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hive/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/home/hive/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>- 创建相关目录
sudo mkdir -p /home/hive/scratchdir
sudo mkdir -p /home/hive/resourcesdir
sudo mkdir -p /home/hive/querylog
sudo mkdir -p /home/hive/operation_logs- 配置环境变量
vim /etc/profile
--------------------------------内容---
#hive
export HIVE_HOME=/home/hadoop/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
--------------------------------内容---
#使配置生效
source /etc/profile- mysql创建hive数据库并赋权
mysql -u root -p
create database hive;
use hive;
create table user(Host char(20),User char(10),Password char(20));
insert into user(Host,User,Password) values("localhost","hive","hive");
FLUSH PRIVILEGES;
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost' IDENTIFIED BY 'hive';
FLUSH PRIVILEGES;- 将mysql驱动包拷贝到$HIVE/lib下
- 初始化mysql元数据: bin/schematool -dbType mysql -initSchema --verbose
- 启动
cd $HIVE_HOME/bin
./hive发现有异常:
1) Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(Z Ljava/lang/String;Ljava/lang/Object;)
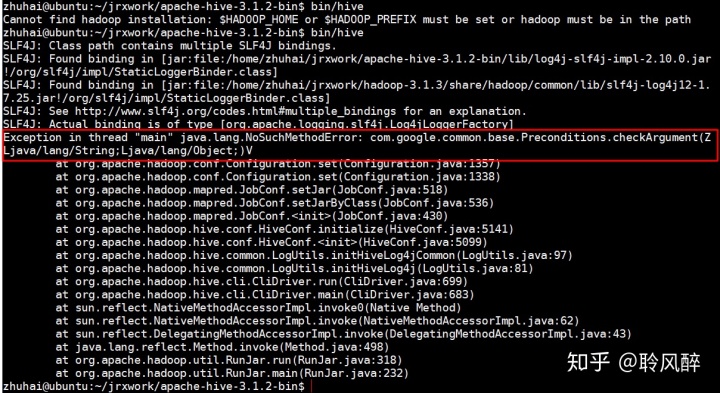
原因: 当前hive所依赖的guava包的版本和hadoop依赖的guava版本冲突了。
解决办法: 替换高版本的guava,更换成和hadoop一样的guava版本:
cp $HADOOPHOOP/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
cd $HIVE_HOME/lib
rm guava-19.0.jar2) hive-site.xml文件字符读取错误

原因: hive-site.xml存在特殊字符 for
解决办法:按照错误提示,将3215行的for 替换成 for

















 6205
6205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









