





说到python与数据分析,那肯定少不了pandas的身影,本文希望通过分析经典的NBA数据集来系统的全方位讲解pandas包,建议搭配IDE一遍敲一边读哦。话不多说,开始吧!目录
- 安装与数据介绍
- 安装与配置
- 检查数据
- 探索性分析
- pandas数据结构
- series对象
- dataframe对象
- 访问series元素
- 使用索引
- 使用.loc与.iloc
- 访问dataframe元素
- 使用索引
- 使用.loc与.iloc
- 查询数据集
- 分类和汇总数据
- 对列进行操作
- 指定数据类型
- 数据清洗
- 数据可视化
一、安装与数据介绍
pandas的安装建议直接安装anaconda,会预置安装好所有数据分析相关的包,当然也可以使用pip安装。
$ pip install pandas既然是数据分析就肯定选择jupyter notebook
$ pip install jupyter接下来就可以进入python使用pandas对数据进行一些探索性的分析,将数据保存在工作目录,然后使用pd.read_csv()函数读取。
>>> import pandas as pd
>>> nba = pd.read_csv("nba_all_elo.csv")
>>> type(nba) #查看数据类型
<class 'pandas.core.frame.DataFrame'>再看看一共有多少数据
>>> len(nba)
126314
>>> nba.shape
(126314, 23)现在我们知道数据集中有126,314行和23列。但是,如何确定数据集包含NBA的哪些统计数据?可以使用以下内容查看前五行.head():
>>> nba.head()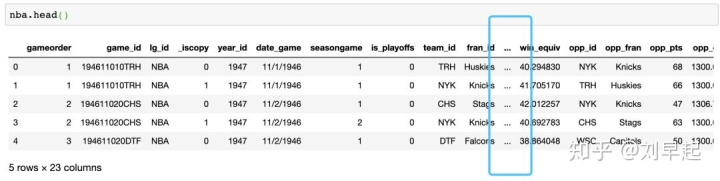
在jupyter notebook中可以看到,一共有23列变量,其中因为列数太多被隐藏了一部分,那么怎样可以看到这些变量呢
>>> pd.set_option("display.max.columns", None)可以看到部分数据小数点后面跟了6位,而对于分析来说并没有必要,所以我们调整为小数点后两位
>>> pd.set_option("display.precision", 2)*检查数据*
之前已经使用Pandas Python库导入了CSV文件,并首先查看了数据集的内容。到目前为止,我们仅看到了数据集的大小及前几行数据。接下来我们来系统地检查数据。
使用以下命令显示所有列及其数据类型.info():
>>> nba.info()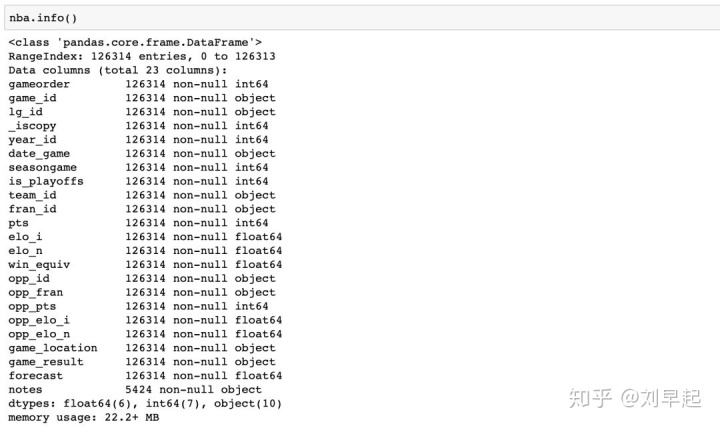
既然已经了解了数据集中的数据类型,现在该概述每个列包含的值了。可以使用.describe():
>>> nba.describe()
.describe()默认情况下仅分析数字列,但是如果使用include参数,则可以提供其他数据类型:
>>> import numpy as np
>>> nba.describe(include=np.object)*探索性分析*
接下来接着进行对数据集的探索性相关分析
>>> nba["team_id"].value_counts()
BOS 5997
NYK 5769
LAL 5078
...
SDS 11
>>> nba["fran_id"].value_counts()
Name: team_id, Length: 104, dtype: int64
Lakers 6024
Celtics 5997
Knicks 5769
...
Huskies 60
Name: fran_id, dtype: int64可以看到含有队名"Lakers"的队伍打了6024场比赛,但其中只有5078场是洛杉矶湖人队的比赛。找出另一个"Lakers"团队是哪个
>>> nba.loc[nba["fran_id"] == "Lakers", "team_id"].value_counts()
LAL 5078
MNL 946
Name: team_id, dtype: int64可以看到另一支湖人队是明尼阿波利斯湖人("MNL")踢了946场比赛。我们甚至可以找出他们打比赛的时间:
>>> nba.loc[nba["team_id"] == "MNL", "date_game"].min()
'1/1/1949'
>>> nba.loc[nba["team_id"] == "MNL", "date_game"].max()
'4/9/1959'
>>> nba.loc[nba["team_id"] == "MNL", "date_game"].agg(("min", "max"))
min 1/1/1949
max 4/9/1959
Name: date_game, dtype: object二、pandas的数据结构
尽管DataFrame提供的功能看起来非常直观,但是基本概念却很难理解。因此,我们将暂不使用庞大的NBA数据,从头开始构建一些较小的Pandas对象分析。
*Series对象 *
Python最基本的数据结构是list,这也是了解**pandas.Series**对象的一个很好的起点。Series是根据列表创建一个新对象,一个Series对象包含两个组件:值和索引
>>> revenues = pd.Series([5555, 7000, 1980])
>>> revenues
0 5555
1 7000
2 1980
dtype: int64可以分别使用.values和来访问这些组件.index。``revenues.values返回中的值Series,而revenues.index返回位置索引。
``
>>> revenues.values
array([5555, 7000, 1980])
>>> revenues.index
RangeIndex(start=0, stop=3, step=1)一个``Series也可以具有任意类型的索引。我们可以将此显式索引视为特定行的标签:
>>> city_revenues = pd.Series(
... [4200, 8000, 6500],
... index=["Amsterdam", "Toronto", "Tokyo"]
... )
>>> city_revenues
Amsterdam 4200
Toronto 8000
Tokyo 6500
dtype: int64以下是Series从Python字典构造带有标签索引的的方法:
>>> city_employee_count = pd.Series({"Amsterdam": 5, "Tokyo": 8})
>>> city_employee_count
Amsterdam 5
Tokyo 8
dtype: int64字典键成为索引,而字典值即为Series值。就像字典一样,Series也支持.keys()和in索引:
>>> city_employee_count.keys()
Index(['Amsterdam', 'Tokyo'], dtype='object')
>>> "Tokyo" in city_employee_count
True
>>> "New York" in city_employee_count
False*Dataframe对象 *
按照之前的Series示例,现在已经有两个Series以城市为键的对象:city_revenues和city_employee_count。我们可以DataFrame通过在构造函数中提供字典将这些对象组合为一个。字典键将成为列名,并且值应包含Series对象:
>>> city_data = pd.DataFrame({
... "revenue": city_revenues,
... "employee_count": city_employee_count
... })
>>> city_data
revenue employee_count
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN注意到Pandas用NAN替换了employee_count的缺失值。新DataFrame索引是两个Series索引的并集:
>>> city_data.index
Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object')就像Series一样,DataFrame还将其值存储在NumPy数组中:
>>> city_data.values
array([[4.2e+03, 5.0e+00],
[6.5e+03, 8.0e+00],
[8.0e+03, nan]])三、访问Series元素
在上面的部分中,我们已经介绍了pandas的数据结构。我们知道Series对象在几种方面与列表和字典的相似之处。也就意味着我们可以使用索引运算符。现在我们来说明如何使用两种特定于pandas的访问方法:.loc和.iloc。
使用.loc和.iloc会发现这些数据访问方法比索引运算符更具可读性。因为在之前的文章中已经详细的介绍了这两种方法,因此我们将简单介绍。更详细的可以查看之前的文章。
*使用索引运算符*
我们先来访问重新city_revenues对象:
>>> city_revenues
Amsterdam 4200
Toronto 8000
Tokyo 6500
dtype: int64我们还可以Series通过标签和位置索引方便地访问中的值:
>>> city_revenues["Toronto"]
8000
>>> city_revenues[1]
8000我们也可以使用负索引和切片,就像使用列表一样:
>>> city_revenues[-1]
6500
>>> city_revenues[1:]
Toronto 8000
Tokyo 6500
dtype: int64
>>> city_revenues["Toronto":]
Toronto 8000
Tokyo 6500
dtype: int64*使用.loc和.iloc*
索引运算符([])很方便,但有一个警告。如果标签也是数字怎么办?假设我们必须使用如下Series对象则可以按照以下方法:
>>> colors = pd.Series(
... ["red", "purple", "blue", "green", "yellow"],
... index=[1, 2, 3, 5, 8]
... )
>>> colors
1 red
2 purple
3 blue
5 green
8 yellow
dtype: object为了避免混淆,Pandas Python库提供了两种数据访问方法:.loc指标签索引。.iloc指位置索引。这将会数据访问方法更具可读性:
>>> colors.loc[1]
'red'
>>> colors.iloc[1]
'purple'colors.loc[1]返回"red"带有标签的元素1。colors.iloc[1]返回"purple"带有索引的元素1。下图就显示.loc``与``.iloc引用了哪些元素:
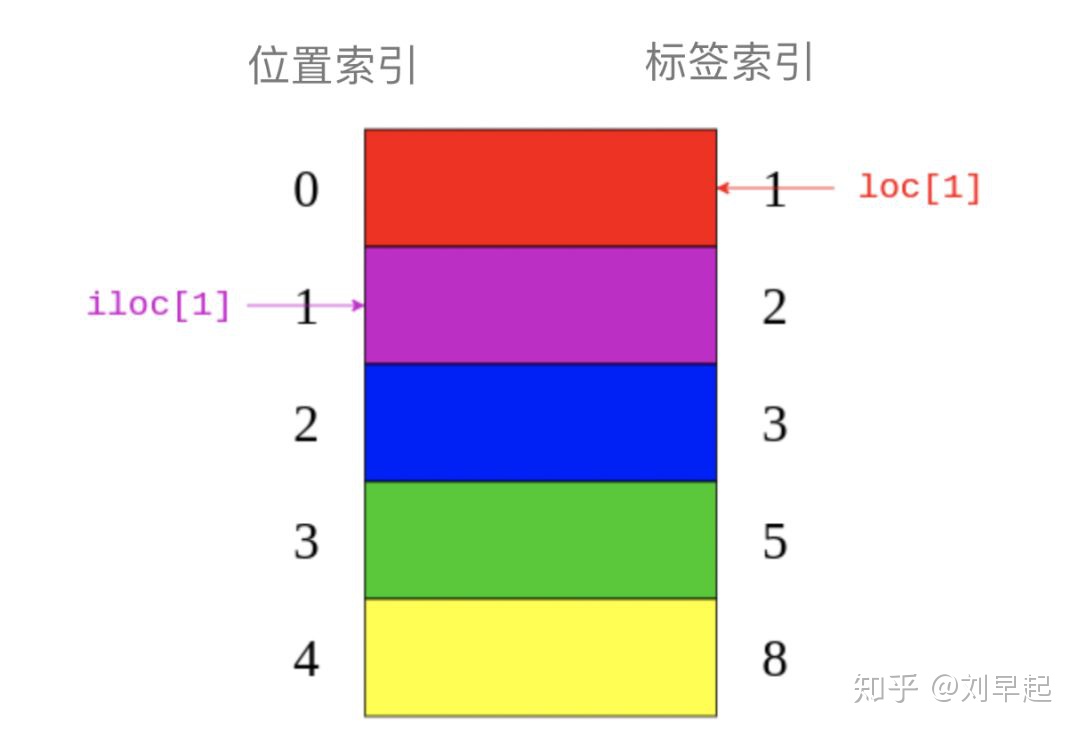
可以看出.loc指向图像右侧的标签索引。而iloc指向图片左侧的位置索引。
四、访问DataFrame元素
由于DataFrame由一系列对象组成,所以可以使用相同的上面的方法来访问它的元素。关键的区别是DataFrame还有一些附加维度。所以我们再对列使用索引操作符,对行使用访问方法.loc和.iloc。
*使用索引运算符*
如果我们将 DataFrame的值看成Series字典形式,则可以使用index运算符访问它的列
>>> city_data["revenue"]
Amsterdam 4200
Tokyo 6500
Toronto 8000
Name: revenue, dtype: int64
>>> type(city_data["revenue"])
pandas.core.series.Series在这里,我们使用索引运算符选择标记为的列"revenue",但如果列名是字符串,那么也可以使用带点符号的属性样式访问:
>>> city_data.revenue
Amsterdam 4200
Tokyo 6500
Toronto 8000
Name: revenue, dtype: int64在一些况下,使用DataFrame点符号访问元素可能无法正常工作或导致意外。这是当列名与DataFrame属性或方法名重合时:
>>> toys = pd.DataFrame([
... {"name": "ball", "shape": "sphere"},
... {"name": "Rubik's cube", "shape": "cube"}
... ])
>>> toys["shape"]
0 sphere
1 cube
Name: shape, dtype: object
>>> toys.shape
(2, 2)*使用.loc和.iloc*
类似于Series,DataFrame还提供了.loc和.iloc 数据访问方法。请记住,.loc使用标签和.iloc位置索引
>>> city_data.loc["Amsterdam"]
revenue 4200.0
employee_count 5.0
Name: Amsterdam, dtype: float64
>>> city_data.loc["Tokyo": "Toronto"]
revenue employee_count
Tokyo 6500 8.0
Toronto 8000 NaN
>>> city_data.iloc[1]
revenue 6500.0
employee_count 8.0
Name: Tokyo, dtype: float64那么更多的iloc和loc方法可以查看之前的文章。
五、查询数据集
现在我们已经了解了如何根据索引访问大型数据集的子集。现在,我们继续基于数据集列中的值选择行以查询数据。例如,我们可以创建一个DataFrame仅包含2010年之后打过的比赛。
>>> current_decade = nba[nba["year_id"] > 2010]
>>> current_decade.shape
(12658, 23)仍然拥有全部23列,但新列DataFrame仅包含其中列中的值"year_id"大于的行2010。我们还可以选择特定字段不为空的行:
>>> games_with_notes = nba[nba["notes"].notnull()]
>>> games_with_notes.shape
(5424, 23)我们接着搜索一下Baltimore两队得分都超过100分的比赛。为了每个比赛只看一次,我们需要排除重复:
>>> nba[
... (nba["_iscopy"] == 0) &
... (nba["pts"] > 100) &
... (nba["opp_pts"] > 100) &
... (nba["team_id"] == "BLB")
... ]六、分类和汇总数据
我们接着学习pandas处理数据集的其他功能,例如一组元素的总和,均值或平均值。幸运的是,Pandas 库提供了分组和聚合功能来帮助我们完成此任务。 Series有二十多种不同的方法来计算描述性统计数据。这里有些例子:
>>> city_revenues.sum()
18700
>>> city_revenues.max()
8000第一种方法返回的总和city_revenues,第二种方法返回的最大值。我们还可以使用其他方法,例如.min()和.mean()。但是需要记住,DataFrame的列实际上是一个Series对象。因此,我们可以在以下各列上使用这些相同的功能:
>>> points = nba["pts"]
>>> type(points)
<class 'pandas.core.series.Series'>
>>> points.sum()
12976235一个DataFrame可以有多个列,其中介绍了聚合的新的可能性,比如分组:
>>> nba.groupby("fran_id", sort=False)["pts"].sum()
fran_id
Huskies 3995
Knicks 582497
Stags 20398
Falcons 3797
Capitols 22387
...还可以按多列分组:
>>> nba[
... (nba["fran_id"] == "Spurs") &
... (nba["year_id"] > 2010)
... ].groupby(["year_id", "game_result"])["game_id"].count()
year_id game_result
2011 L 25
W 63
2012 L 20
W 60
2013 L 30
W 73
2014 L 27
W 78
2015 L 31
W 58
Name: game_id, dtype: int64七、对列进行操作
接下来要说的是如何在数据分析过程的不同阶段中操作数据集的列。我们可以在初始数据清理阶段添加列或删除列,也可以稍后基于分析的见解来添加和删除列。首先创建原始副本DataFrame以使用:
>>> df = nba.copy()
>>> df.shape
(126314, 23)然后基于现有列定义新列:
>>> df["difference"] = df.pts - df.opp_pts
>>> df.shape
(126314, 24)我们还可以重命名数据集的列。似乎"game_result"且"game_location"太冗长,因此将其重命名:
>>> renamed_df = df.rename(
... columns={"game_result": "result", "game_location": "location"}
... )
>>> renamed_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 126314 entries, 0 to 126313
Data columns (total 24 columns):
gameorder 126314 non-null int64
...
location 126314 non-null object
result 126314 non-null object
forecast 126314 non-null float64
notes 5424 non-null object
difference 126314 non-null int64
dtypes: float64(6), int64(8), object(10)
memory usage: 23.1+ MB我们的数据集可能包含不需要的列。例如,对于某些人来说,Elo评分可能是一个有趣的概念,但是本文不对其进行分析。所以可以删除与Elo相关的四列:
>>> df.shape
(126314, 24)
>>> elo_columns = ["elo_i", "elo_n", "opp_elo_i", "opp_elo_n"]
>>> df.drop(elo_columns, inplace=True, axis=1)
>>> df.shape
(126314, 20)八、指定数据类型
当DataFrame通过调用构造函数或读取CSV文件来创建new时,Pandas会根据其值将数据类型分配给每一列。尽管它做得很好,但并不完美。如果我们为列选择正确的数据类型,则可以显着提高代码的性能。我们再看一下nba数据集的列:
>>> df.info()
有十列具有数据类型object。这些object列中的大多数包含任意文本,但是也有一些数据类型转换的候选对象。例如,查看以下列date_game:
>>> df["date_game"] = pd.to_datetime(df["date_game"])在这里,我们就用.to_datetime()可以将所有游戏日期指定datetime对象。
九、数据清洗
数据清洗主要是对空值与无效值或者异常值等数据进行处理。我们以缺失值为例。
处理包含缺失值的记录的最简单方法是忽略它们。我们可以使用删除所有缺少值的行.dropna():
>>> rows_without_missing_data = nba.dropna()
>>> rows_without_missing_data.shape
(5424, 23)如果我们的数据集包含一百万条有效记录,而一百条缺少相关数据,那么删除不完整的记录可能是一个合理的解决方案。如果与是与的分析无关的列,也可以删除它们。为此,依旧是.dropna()再次使用并提供axis=1参数:
>>> data_without_missing_columns = nba.dropna(axis=1)
>>> data_without_missing_columns.shape
(126314, 22)如果我们的数据有一个有意义的默认值,那么也可以用这个值替换缺少的值:
>>> data_with_default_notes["notes"].fillna(
... value="no notes at all",
... inplace=True
... )
>>> data_with_default_notes["notes"].describe()
count 126314
unique 232
top no notes at all
freq 120890
Name: notes, dtype: object十、数据可视化
数据的可视化我们需要借助matplotlib,我也会再后续写一个详细的matplotlib教程
>>> %matplotlib inlineSeries和DataFrame对象都有一个.plot()方法,默认情况下它会创建一个折线图。如可视化尼克斯整个赛季得分了多少分:
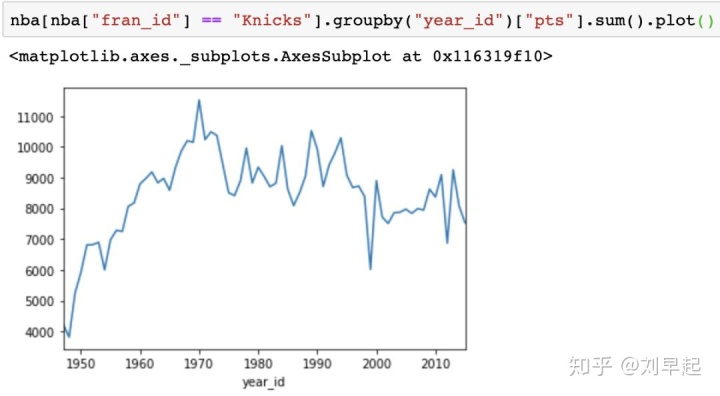
还可以创建其他类型的图,如条形图:
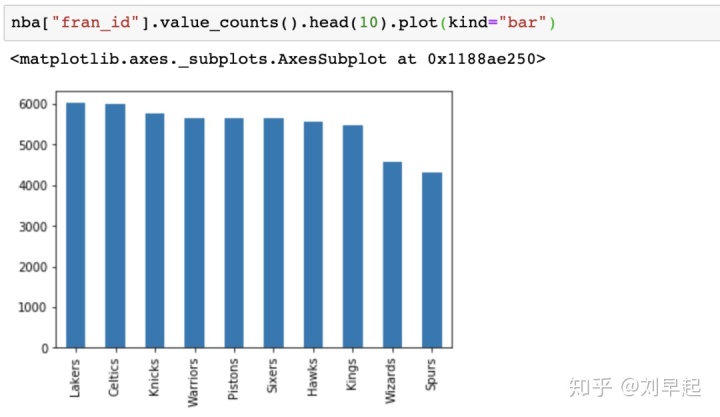
而关于使用matplotlib进行数据可视化的相关操作中,还有许多细节性的配置项,比如颜色、线条、图例等。这些就都留到以后再说。
结束语
走到这里,有关pandas的最常用的知识点就已经全部介绍完毕,当然其中有很多部分都值得我们再进一步细讲,比如iloc与loc的使用、matplotlib的各种操作,或者在数据清洗中的各种问题。就留在以后一点一点去讲解。
====================================================================
更多python干货可以关注我的专栏。
我的公/众/号:早起python














 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









