





点击上方“新机器视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
https://www.zhihu.com/question/35339639
本文仅作为学术分享,如果侵权,会删文处理
使用深度学习(CNN)算法进行图像识别工作时,有哪些data augmentation 的奇技淫巧?
作者:景略集智https://www.zhihu.com/question/35339639/answer/406894510
估计很多搞深度学习的都遇到过这个情况:有不错的想法,可以用深度学习模型实现。于是兴致勃勃的上网找相关数据集,结果却发现只有很少一部分图像。

你想起来,很多常见的数据集都有成千上万张井然有序的图像,你还想起来不少大拿说过足够的数据对于模型性能至关重要。望着眼前寒酸的数据,失望之余不禁长叹“只有这么点数据,我这么牛的模型能成吗?”
答案是,能成!但是在我们揭晓为何能成之前,需要简单回应一些基本的问题。
为什么老说需要大量的数据?

我们训练机器学习模型,其实就是我们调参的过程,这样模型能将具体的输入(比如说图像)映射为输出(标签)。我们的优化目标就是尽力让模型的损失调低,当然需要往正确的方向调整模型参数才行。
成功的神经网络拥有数以百万计的参数!
自然而然,如果你有很多参数,就需要为模型展示大量的样本,才能让模型获得良好的性能。同时,根据模型所执行任务的复杂程度,你也需要合适数量的模型参数。
如果数据不够,我该怎么获得更多数据?
其实你不用在四处寻找新图像添加到你的图像数据集里,为何?因为神经网络刚开始时没那么聪明。比如,对于一个训练不足的神经网络来说,它会觉得下面这 3 个网球是 3 张不同的唯一图像:

那么,要想获得更多数据,我们只需对现有数据集做些微小的调整。所谓微小的调整,包括翻转、旋转、平移等等。不管怎么说,神经网络会把这些略微调整后的图像当做不同的图像。

卷积神经网络能够鲁棒地将物体分类,即便物体放置在不同的方向上,这也就是所说的不变性属性。更具体的说,卷积神经网络能够稳定应对图像平移、图像视角、图像大小或光线条件的变化。
这实际上就是图像增强的逻辑前提。在现实工作中,我们可能得到一个数据集,其中的图像是在部分情况下所拍,但目标应用却是在多种情况下,比如不同的方向、位置、尺寸和亮度等等。我们会用额外修正过的数据训练神经网络,应对这些情况。我们对图像稍作调整,补充数据不足这个短处的方法,就是图像增强。
如果我手头数据很多,图像增强还有用吗?
那必须,有用。图像增强能增加你的数据集中的数据数量。这和神经网络的学习方式有关。我们举个例子:

假设数据集中的两个类。左边的代表 A 品牌(福特),右边的代表 B 品牌(雪佛兰)
想象你有个数据集,包含两个品牌的汽车图像,如上所示。我们假设所有 A 品牌的汽车都如上面左图所示摆放(也就是所有汽车朝向左侧),所有B品牌的汽车都如右图所示摆放(朝向右侧)。现在,我们把这个数据集输入到搭建的神经网络中,希望经过训练后,模型能有不错的性能。
假设完成了训练,我们输入上面一张图像,比如 A 品牌的汽车,但模型却认为是 B 品牌的汽车。这时我们估计就郁闷了,明明模型在数据集上达到了 95% 的准确度啊?这种情况不是夸张,经常出现。

为什么会出现这种情况?因为这就是机器学习算法的工作原理。算法会找到能将一个类和另一个类区分的最明显的特征。在这个例子中,特征就是所有 A 品牌汽车朝向左侧、所有 B 品牌汽车朝向右侧。
你的神经网络的质量和输入的数据质量一样。
我们该怎样防止这种情况?我们必须减少数据集中不相关的特征。对于我们上面的汽车分类模型来说,一个简单的解决方法就是增加两种品牌汽车的图像数量,且面朝其它方向。如果你能将数据集中的图像水平翻转,让它们朝向另一边,那就更好了。用这样处理后的新数据集训练神经网络,模型就会得到理想的性能了。
着手开始
在我们深入了解多种不同的图像增强方法前,我们必须考虑几个问题。
在我们的机器学习流水线的哪个部分增强数据?
答案似乎很明显:在将数据输入到模型之前增强数据啊。没错,但是这里有两个选择。一个就是事先进行所有必需的图像平移工作,基本上就是增加数据集大小;另一个选择是将图像输入机器学习模型之前,以小批量进行图像平移。
第一种选择就是常说的离线增强。当数据集相对较小时,优先选择这种方法,因为你最终会通过一个与执行的转换数量相等的因子来增加数据集的大小。比如这里的汽车图像数据集,将所有图像翻转后,就能将数据集大小增加一倍。
第二种选择就是常说的在线增强。这种方法比较适合数据集较大时的情况,因为我们很难应付数据集爆炸性变大。相反,我们可以小批量平移输入到模型中的图像。有些机器学习框架支持在线增强,使用GPU可以加快增强速度。
常见的图像增强方法
在这一部分,我们会展示一些基本却很强大的图像增强方法,也是目前普遍应用的方法。
在介绍这些方法前,为了简单起见,我们先做个假设。就是我们不需要考虑图像的边界之外的东西。对于超出图像边界之外的情况,我们需要插补一些信息。在介绍完图像增强类型后,会详细解释这种情况。
对于下面的每种方法,我们也都定义了一个增强因子(augmentation factor),用以增强数据集(即数据增强因子)。
翻转
你可以水平或垂直翻转图像。有些框架没有提供垂直翻转的函数,不过可以变通一下:将图像旋转180度,然后水平翻转。下面是一些翻转后的图像示例。

从左至右分别是:原始图像,水平翻转图像,垂直翻转图像
你可以使用下面的命令行翻转图像。数据增强因子=2到4X
# NumPy.'img' = A single image.flip_1 = np.fliplr(img)# TensorFlow. 'x' = A placeholder for an image.shape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
flip_2 = tf.image.flip_up_down(x)
flip_3 = tf.image.flip_left_right(x)
flip_4 = tf.image.random_flip_up_down(x)
flip_5 = tf.image.random_flip_left_right(x)旋转
关于旋转操作,需要注意的一点是在旋转后,可能无法保存图像的维度。如果你的图像是正方形,旋转 90 度后可以保存图像尺寸。如果图像为矩形,旋转 180 度后则可以保存图像尺寸。以更小的角度旋转图像将改变图像的最终尺寸。在下个部分,会讲解如何处理这种问题。下面是正方形图像旋转 90 度的示例:

当我们从左到右移动时,图像相对于前一个图像顺时针旋转 90 度
用如下任一命令可以将图像旋转。数据增强因子 =2 到 4X
# Placeholders: 'x' = A single image, 'y' = A batch of images# 'k' denotes the number of 90 degree anticlockwise rotationsshape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
rot_90 = tf.image.rot90(img, k=1)
rot_180 = tf.image.rot90(img, k=2)# To rotate in any angle. In the example below, 'angles' is in radiansshape = [batch, height, width, 3]
y = tf.placeholder(dtype = tf.float32, shape = shape)
rot_tf_180 = tf.contrib.image.rotate(y, angles=3.1415)# Scikit-Image. 'angle' = Degrees. 'img' = Input Image# For details about 'mode', checkout the interpolation section below.rot = skimage.transform.rotate(img, angle=45, mode='reflect')缩放
可以将图像放大或缩小。在放大时,放大后的图像尺寸要大于原始图像。大部分图像框架会根据原始图像的尺寸对新图像进行裁切。在下个部分我们会处理图像缩小的问题,因为图像缩小会缩小图像的尺寸,这就迫使我们处理图像边界之外的信息。下面是图像缩放的示例:

从左至右分别为:原始图像,图像向外缩放10%,图像向外缩放20%
通过下面的命令执行图像缩放。数据增强因子=任意。
# Scikit Image. 'img' = Input Image, 'scale' = Scale factor# For details about 'mode', checkout the interpolation section below.scale_out = skimage.transform.rescale(img, scale=2.0, mode='constant')
scale_in = skimage.transform.rescale(img, scale=0.5, mode='constant')# Don't forget to crop the images back to the original size (for# scale_out)裁剪
和缩放不同,裁切是从原始图像中随机采样一部分。然后我们将采样区域大小调整为原始图像大小。这种方法就是常说的随机裁剪。下面是随机裁剪的图像示例。如果你仔细看,就会注意到裁剪和缩放之间的区别。

从左至右:原始图像,从左上角裁剪出一个正方形部分,然后从右下角裁剪出一个正方形部分。剪裁的部分被调整为原始图像大小
在 TensorFlow 上,可以用以下任一命令行裁剪图像。数据增强因子=抽象。
# TensorFlow. 'x' = A placeholder for an image.original_size = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = original_size)# Use the following commands to perform random cropscrop_size = [new_height, new_width, channels]
seed = np.random.randint(1234)
x = tf.random_crop(x, size = crop_size, seed = seed)
output = tf.images.resize_images(x, size = original_size)平移
平移包括将图像沿着 X 或 Y 方向(或两个方向)移动图像。在下面的例子的,我们假定图像边界之外为黑色背景,并被恰当平移。这种增强方法非常有用,因为大部分对象几乎能位于图像中的任何位置。这能让卷积神经网络查看所有信息。
从左至右:原始图像,图像翻转到右侧,图像向上翻转
可以用如下命令平移图像。数据增强因子=任意。
# pad_left, pad_right, pad_top, pad_bottom denote the pixel# displacement. Set one of them to the desired value and rest to 0shape = [batch, height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)# We use two functions to get our desired augmentationx = tf.image.pad_to_bounding_box(x, pad_top, pad_left, height + pad_bottom + pad_top, width + pad_right + pad_left)
output = tf.image.crop_to_bounding_box(x, pad_bottom, pad_right, height, width)高斯噪声
当神经网络试图学习可能并无用处的高频特征时(即频繁发生的无意义模式),常常会发生过拟合。具有零均值特征的高斯噪声本质上就是在所有频率上都有数据点,能有效使得高频特征失真,减弱它对模型的影响。这也意味着低频成分(通常也是我们关心的数据)也会失真,但神经网络能够通过学习忽略这部分影响。添加正确数量的噪声就能增强神经网络的学习能力。
一个相对弱化的版本就是椒盐噪声,它是以随机的白色及黑色像素点铺满整个图像。给图像添加椒盐噪声的作用和添加高斯噪声是一样的,但产生的失真效果相对较弱。

从左至右:原始图像,增加了高斯噪声的图像,添加了椒盐噪声的图像
在 TensorFlow 上,可以用如下命令行为图像添加高斯噪声。数据增强因子 =2X
#TensorFlow. 'x' = A placeholder for an image.shape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)# Adding Gaussian noisenoise = tf.random_normal(shape=tf.shape(x), mean=0.0, stddev=1.0,dtype=tf.float32)
output = tf.add(x, noise)高级增强方法
在实际中,自然数据会存在于各种各样的情况中,只用上面的简单方法无法处理。例如,我们需要识别图像中的风景。那么风景包含很多情况:冰天雪地的荒原、绿油油的草原、茂密的森林等等。这听起来不就是分类任务吗?这么判断大体是对的,但有处例外。我们忽视了图像的一个关键特征——拍摄季节,而这将会影响模型的性能。
如果我们的神经网络没能理解某些风景可能存在于多种情况中(下雪、潮湿、明亮的环境等等),那么它很可能错误地将冰冻的湖泊当做冰天雪地的荒原,或者把沼泽标为湿地。
缓解这种问题的一个方法就是添加更多的图像,这样我们就能应对所有的季节变化情况,但这是一项非常艰巨的任务。想象一下,扩展我们的数据增强概念,人为地产生不同季节的效果,会是多么炫酷的事情!
条件式生成对抗网络
不用了解背后的繁杂细节,反正条件式生成对抗网络能够将一个域的图像转换为另一个域的图像。如果你觉得这听着太笼统,不是的;它是一种非常强大的神经网络!下面是条件式生成对抗网络的将夏季场景转换为冬季场景的示例。

上面的方法虽然鲁棒,但属于计算密集型,需要大量的计算力。一种更为廉价的方法是神经风格迁移。它能抓住一张图像的纹理、气氛和外观(即“风格”),然后将它们和另一张图像的内容相融合。使用这种强大的方法,我们可以制作出和条件式生成对抗网络相同的效果(实际上这种方法在条件式生成对抗网络出现之前就提出来了!)。
这种方法的唯一缺点就是生成的图像看起来太过艺术范儿,没有真实感。不过,风格迁移仍然有不少优点,比如“深度图像风格迁移”技术,能够产生引人瞩目的效果,如下所示:

我们这里不再深入探讨这两种方法,因为它们的内部原理在这里并不是重点。我们可以使用这两种现有模型来增强图像。
插值简介
如果你想平移一张没有黑色背景的图像呢?如果想缩小图像或以很小的角度旋转图像呢?
在我们进行这类变换操作之后,还需要保存原始图像的尺寸。由于我们的图像并不包含图像边界之外的信息,因此我们需要做些假设。通常,我们会假设图像边界之外的空白区域上每个像素点的值为常数 0。所以当你进行这些变换操作时,你会得到一片图像没有覆盖的黑色区域。

从左至右:逆时针旋转 45 度的图像,右侧翻转的图像和向内缩放的图像
但是这种假设是正确的吗?很遗憾,在实际工作中,大部分情况下不是。不过图像预处理和机器学习框架有很多标准方法,借助它们你可以决定如何填充未知区域。它们定义如下。
常数
最简单的插值方法就是用一些常数值取填充未知区域。对于自然状态下的图像,这种方法可能不凑效,但是可以用于在单色背景下拍摄的图像。
边缘
可以将图像的边缘值扩展到图像边界以外。这种方法也适用于轻微的图像平移。
反射
可以沿着图像边界反射图像的像素值。这种方法对于包含树林、山脉等连续或自然背景的图像,非常有用。
对称
这种方法和反射类似,除了一点:在反射边界上拷贝边缘像素。正常情况下,反射和对称可以交替使用,但处理非常小的图像或模式时,差异会非常明显。
包裹
这种方法是在超出图像边界之外的地方重复填充图像,仿佛在平铺图像。由于对很多场景并无意义,不如其它方法那么常用。
除了这些方法以外,你也可以设计自己的方法处理未知区域,但通常这些方法对于大多数分类问题效果良好。

从左至右:常数,边缘,反射,对称和包裹模式
如果我使用以上全部方法,我的机器学习算法会有很好的鲁棒性吗?
如果以正确的方式用它们,那么答案是 Yes。何为正确方式?有时并非所有的增强技术都适用于数据集。以我们开头的汽车图像为例,下面是可以修改图像的一些方法。

从左至右:原始图像,水平翻转,旋转180度,旋转90度(顺时针)
当然它们还是同一辆车的图像,但是你的目标应用可能永远不会看到在这些方向的汽车。
例如,你只是想随机分类路上的汽车,那么只有第二张图像对数据集有意义。但是如果你有一家处理交通事故的保险公司,你也想识别车祸中被撞翻、撞坏的车,那么第三张图像对于数据集最有意义。而对于上面这两种情况,第四张图像都没有意义。
重点是,在使用图像增强方法的时候,我们必须保证不能增加无关的数据。
这一切值得吗?
你可能期待看到些结果,好给你点动力做图像增强。我们就举个例子,证明图像增强确实有用,你自己也可以去验证一下。
我们首先创建两个神经网络,将数据分类到四个类别中的一个:猫,狮子,老虎和豹子。这两个神经网络一个使用图像增强,一个不使用。从这里(https://drive.google.com/drive/folders/1GpIpbqBQ_ak1Z_4yAj7t6YRqDDyyBbAq?usp=sharing)下载数据集。
如果你查看了数据集,会注意到每个类别只有50张图像用于训练和测试模型。前面说过,其中一个分类模型不能使用图像增强技术,为了公平起见,我们使用迁移学习方法让模型应对数据稀缺的问题。

对于没有使用图像增强的模型,我们使用 VGG19 网络。该模型的 TensorFlow 实现地址:https://github.com/thatbrguy/VGG19-Transfer-Learn 。如果你将代码库克隆到本地,就能从这里(https://drive.google.com/drive/folders/1GpIpbqBQ_ak1Z_4yAj7t6YRqDDyyBbAq?usp=sharing)得到数据集,从这里(https://mega.nz/#!xZ8glS6J!MAnE91ND_WyfZ_8mvkuSa2YcA7q-1ehfSm-Q1fxOvvs)得到vgg19.py文件。现在你就可以运行模型验证性能。
不过,为数据增强再另外编写代码确实有些麻烦。所以可以借助一些平台,比如 Nanonets,其内置了风格迁移个图像增强技术。只需将数据上传至平台,等待他们的服务器训练即可(通常是30分钟)。
完成训练后,你可以对其 API 请求调用来计算测试的准确性。你可以在 GitHub repo 中找到对应的示例代码片段 (不要忘记在代码段中插入模型的 ID)。
结果如下:
VGG19(没有使用图像增强):最高测试准确率为76%
Nanonets(使用了图像增强):最高测试准确率为94%
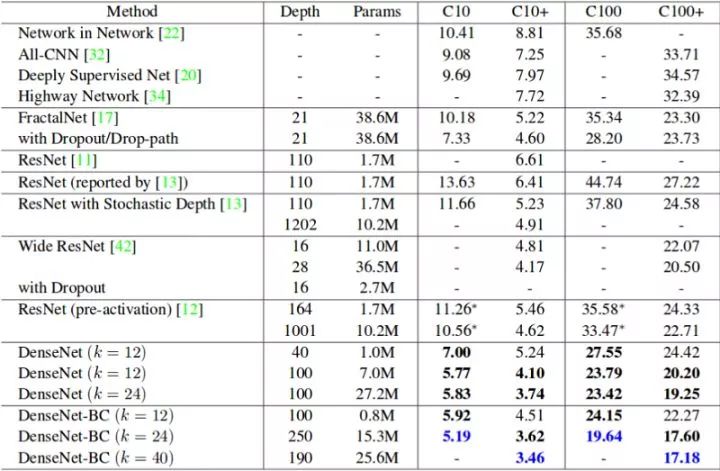
结果差距还是很明显的,对吧?事实上,大多数模型如果数据更多,性能会更好。为了具体的证明,可仔细看看下面这张表。它显示了 Cifar 10 (C10) 和 Cifar 100 (C100) 数据集上常用的神经网络的错误率。C10+ 和 C100+ 列是进行数据增强后的错误率。
结语
本文我们分享了几种图像增强的方法,以及为何需要图像增强。普通的图像增强方法包括:翻转、旋转、平移、裁剪、缩放和高斯噪声;高级版图像增强方法还有常数填充、反射、边缘延伸、对称和包裹模式等。希望这些图像增强方法对你在应用深度学习中缓解图像不足的问题时有所帮助。
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









