





经过一段时间的学习,总结一下目前所学知识,在用python进行数据分析的过程中所用到的函数及分析过程。
第一步 导入包
常用的包有以下这些:
1.用于处理数据的包
import pandas as pd
import numpy as np
pandas 和numpy基本包含了对数据处理的所有操作
2.用于数据可视化的包
import matplotlib.pyplot as plt
import seabron as sns
matplotlib.pyplot包用于基本的数据可视化,画柱,线,点图的时候用
seabron中的headmap用来画热力图
3.连接数据库的包
import pymysql
第二步 导入数据
1.导入数据的话一般考虑csv类型
pd.read_csv(r'路径/data.csv',dtype='object',encoding='utf-8')#可以选择指定文本类型和编码语言
df.to_csv('C:/Users/10136/Desktop/comma_sep1.csv ')#保存数据2.从数据库导入数据
#导入包
import pymysql
连接数据库
conn=pymysql.connect(host='localhost',port=3306,
user='root',password='123456',db='brazilian',charset='utf8')#db为数据库名
query='select * from new_orders_merged'#编写SQL语句
sql_data=pd.read_sql(query,conn)#执行SQL语句,从数据库中导入名为new_orders_merged的表第三步 数据处理
1.查看数据基本结构
查看行和列时可以用data.shape
查看每列数据类型用data.dtypes
查看数据每列信息用http://data.info()
查看数据的前5行用data.head()
2.处理缺失值
查看数据是否有缺失值
可以用data.insnull(),会列出所有数据的bool类型,有缺失值为True
data.isnull().any()#显示有缺失值的列的bool类型,有缺失值为True
data[data.isnull().values==True]#显示所有带有缺失值的行列,适用于缺失值较少的数据
data.isnull().sum()#查看每列缺失值的个数,可以根据结果对怎样处理缺失值做出判断
删除缺失值
如果缺失值相对样本数据影响不大,对缺失值可以采用删除处理
data.dropna()#这是对样本中所有缺失值所在的行进行删除
data.dropna(subset=['列名'])#这是对指定列的缺失值删除所在行
data.dropna(how='any/all',axis=0)#删除缺失值所对应的行,any是指只要有缺失值则对整行删除,all是指当整行都是缺失值则对其删除。
填充缺失值
如果删除缺失值对样本影响较大,可以采用填充的方式补充缺失值
data.fillna('')#可以把所有缺失值补充为统一值*
data['列名']fillna()#针对某一列进行补充
data['列名']fillna(data['列名'].mean())#以这列的平均值作为补充
data['列名']fillna(data['列名'].interpolate())#以缺失值上下数的平均值进行补充
data.fillna(axis=1,method='ffill')#以缺失值同行前一列的值进行补充,axis=0是以缺失值同列上面一行的值进行补充。3.处理重复值
删除重复值
data.drop_duplicates(keep='first/last'/False)#first :保留第一行重复值,last:保留最后一行重复值,False:不保留重复值,删除所有重复的数据
4.处理异常值
如果数据中有某一列的数据有异常,可以选择性的筛选滤去这些异常值
#方法1
app=app.iloc[np.where(app["CNT_CHILDREN"]<5)]
#方法2
app=app[app["CNT_CHILDREN"]<5]
#方法3
d=pd.Series(app['CNT_CHILDREN']).unique()
list1 = [i for i in d if i <=5]
app=app[app.CNT_CHILDREN.isin(list1)]- 首先我们要对数据进行聚合操作
df.describe().applymap(lambda x:'%.2f'%x).T
data.describe().round(2).T #与上面相同
#查看数据的最小值,最大值,四分位数,标准差,平均数,数据数量等
#applymap()执行函数 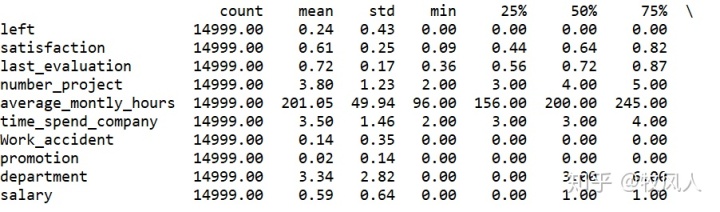
然后根据数据的业务情况,分析数据的异常值,比如最大值,最小值是否符合业务情况,然后再对异常值进行相应的处理
- data.replace(value,new_value,inplace=True)#对数据进行替换操作,inplace=True是对原数据进行更改
#对把数据数值化方便分析
##分别查看department列和salary列唯一值有多少个
df1=pd.Series(df['department']).unique()#Series创建一维数组
df2=pd.Series(df['salary']).unique()
##把两列的值转化为数值
df['department'].replace(list(df1),np.arange(10),inplace=True)
df['salary'].replace(list(df2),[0,1,2],inplace=True)连接数据表
app_cre=pd.merge(app,cre,on='客户号',how='inner')第四步 数据分析
1.对列重命名
data.rename(columns={'原列名':'新列名'})#可以更改列名,方便后面分析
2.查看一列数据的唯一值
pd.Series(data['列名']).unique()#用来查看一列数据有多少不同值,适合查询类别较少的数据
3.对列进行移动
有时候为了分析方便,可以适当对某些列进行前移或删除
front=data['列名']#先把这一列赋予一个值
data.drop(labels='列名',axis=1,inplace=True)#删除原列的数据
data.insert(0,'列名',front)#把这一列插入到列序为0的位置4.常用的一些数据操作
- 排序
data.sort_values(by='列名',ascending=True, inplace=False)#注意指定列,升序降序问题
- 分组
data.groupby(by='列名').agg({'列名':'median','列名':'mean'})#通常groupby后面要跟聚合函数
data.groupby('列名')['列名'].transform('mean')#在原数据的基础上对分组后的列进行求同组的均值,结果是在原数据的后面再加一列
把数据离散化
pd.cut(data['列名'],[1,30,60,100],labels=['小','中','大'])
loc()结合cut可以添加新列
给数据添加列
data.assign(新列名=np.log(data['列名']))
- 求某一列中各种值的占比
df['left'].value_counts()/df['left'].count()
#value_counts是分类求出这一列数据不同值的计数量4.连接数据库进行数据分析
从数据库引入数据的常规操做
import pymysql
#使用cursor()方法获取数据库的操作游标
cursor= conn.cursor()
sql='''SELECT product_category_name AS "SPU",COUNT(DISTINCT(product_id)) AS "SKU数"
FROM new_orders_merged
GROUP BY product_category_name
ORDER BY SKU数 DESC;
'''
#读取查询结果并转成列表
cursor.execute(sql)#执行查询语句
ret=cursor.fetchall()#读取查询结果
ret_list=[i for i in ret]
#将列表转为datafarm形式
ret_data=pd.DataFrame(ret_list,index=None,columns=['SPU','SKU数'])
ret_data=ret_data.set_index('SPU')5.设置显示问题
设置显示结果的最大行列
pd.set_option('display.max_columns',10)#最大显示多少列
pd.set_option('display.max_rows',100)#最大显示多少行设置现在图表中的中文字体
#方法1
from matplotlib import font_manager
#设置中文字体
my_font=font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc',size=18)
#方法2
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']第五步 数据可视化
1.热力图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
#导入数据并分组
df=pd.read_csv('week.csv')
#df.columns=['week','hours','counts']
#做成数据透视表
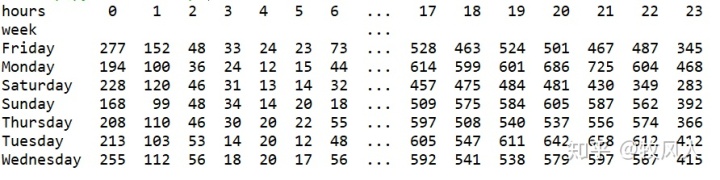
df=pd.pivot_table(df,index='week',columns='hours',values='counts')
print(df)
#画热力图
plt.figure(figsize=(16,8))#画布
ax=sns.heatmap(df,annot=True,fmt='d',cmap='Blues')#annot是显示每个数据,fmt是显示方式
ax.set_xlabel('小时',size=14)#X轴标签
ax.set_ylabel('星期',size=14)#Y轴标签
ax.set_title('客户购买频数图',size=18)#标题
plt.savefig('customers_.png',dpi=1000,bbox_inches='tight')#保存图片首先导入的数据形式如下:
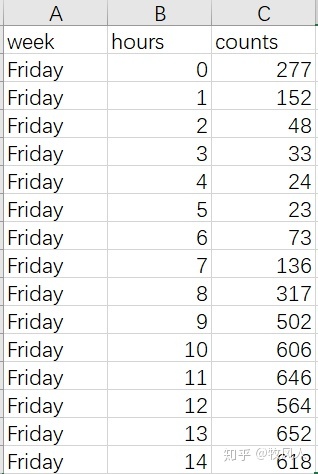
在进行画图之前要对数据进行处理,利用pivot_table()函数把原数据的行列转换成画图时数据的行、列和数据值,这时的数据形式就是画图时的数据形式,呈现如下:
然后就是画热力图,结果呈现如下:
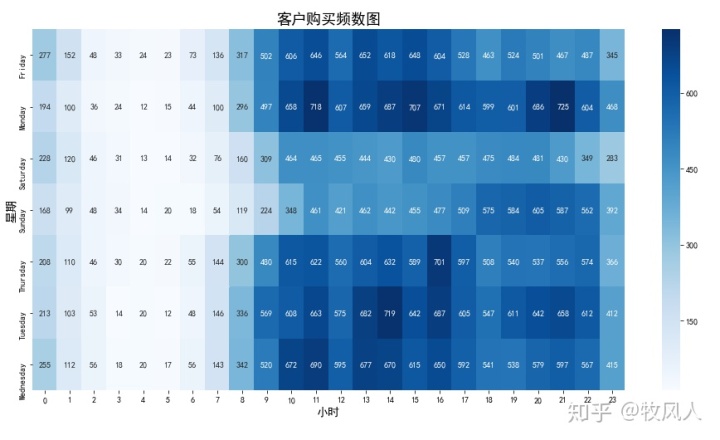
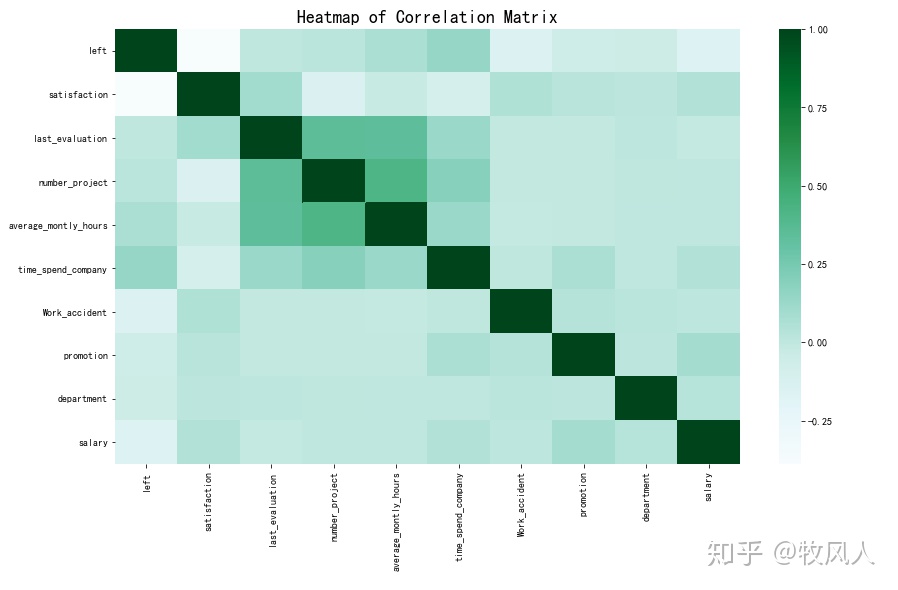
当数据为多列时,可以用df.corr()求出每列的相关系数,然后画出热力图
sns.heatmap(df.corr(),cmap="BuGn");
plt.title('Heatmap of Correlation Matrix')
结果如下
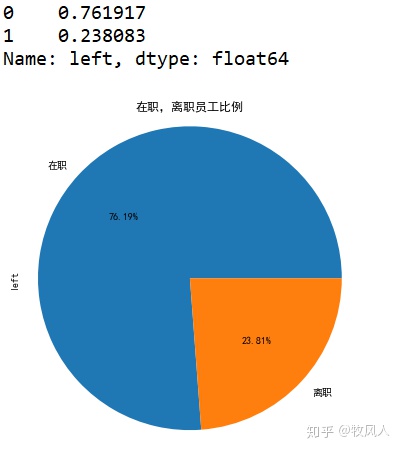
2.饼图
left_rate=df['left'].value_counts()/df['left'].count()#饼图的数据类型
#用饼状图表示
left_rate.plot.pie(labels = ['在职','离职'],autopct = '%.2f%%',figsize=(8,8))
plt.axis('equal') #将坐标系设置为正方形,也就是使饼状图为圆形
plt.title('在职,离职员工比例')
plt.savefig('scatr.png',dpi=1000)
plt.show()#不能放到前面,否则保存不了图片结果如下:
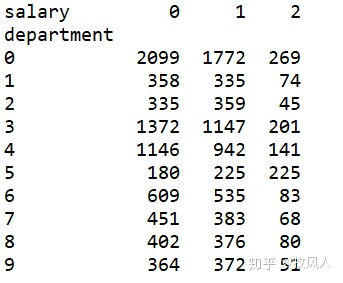
3.柱状图
#crosstab是数据交叉表,计算数据因子的频率值,对比数据透视表pivot_table()
depart_salary_table=pd.crosstab(index=df['department'],columns=df['salary'])
print(depart_salary_table)
#两种数据叠加在一起显示stacked=Ture
depart_salary_table.plot(kind="bar",figsize=(10,10),stacked=True)结果如下:
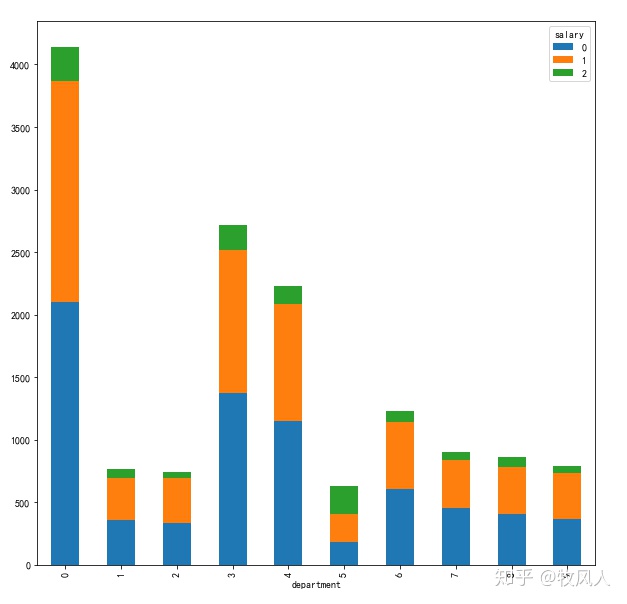
4.折线图
import matplotlib.pyplot as plt
import random
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
x=range(2,26,2)
y=[random.randint(15,30)for i in x]#列表生成式
#设置背景颜色
#print(plt.style.available)
plt.style.use('bmh')
#设置图片的大小,画布大小
plt.figure(figsize=(10,6),dpi=80)
#设置xy轴刻度标签
x_ticks_lable=['{}:00'.format(i) for i in x]
plt.xticks(x,x_ticks_lable,rotation=30)
y_ticks_lable=['{}℃'.format(i) for i in range(min(y),max(y)+1)]
plt.yticks(range( min(y),max(y)+1),y_ticks_lable)
#设置xy轴标题
plt.xlabel('时间',rotation=30)#旋转rotation
plt.ylabel('温度')
#设置标题
plt.title('每两小时温度变化',size=18,color = 'b')
plt.plot(x,y,color='red',linestyle='-.',linewidth=1.5,label='第一天',
marker = 'o',markersize = 7)
#设置图例
#设置位置loc(upper left, lower left, center left, upper center)
plt.legend(loc='upper left')#不带参数时自动选择位置
#绘制网格
plt.grid(alpha=0.3)
#保存图片
plt.savefig('line.png')
#显示图片
#plt.show()显示结果如下:
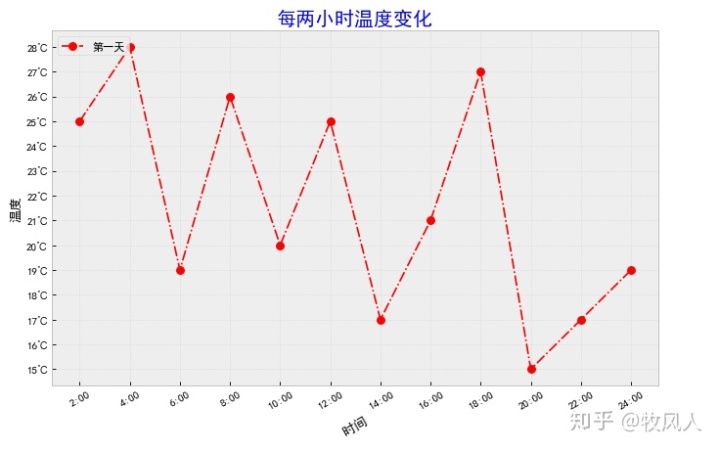
5.多个坐标系显示
import pandas as pd
from pylab import mpl
import pymysql
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif']=['SimHei']
#连接数据库
conn=pymysql.connect(host='localhost',port=3306,
user='root',password='123456',db='brazilian',charset='utf8')
query='select * from new_orders_merged'
sql_data=pd.read_sql(query,conn)
#对数据汇总分析,查看异常值
a=sql_data.describe()
#州交易额贡献
#sql语句
sql="""SELECT customer_state,ROUND(SUM(payment_value),2) AS "交易额"
FROM new_orders_merged
GROUP BY customer_state ORDER BY 交易额 DESC;"""
cursor= conn.cursor()
#执行sql语句
cursor.execute(sql)
#读取全部数据
state_pay=cursor.fetchall()
#转换数据类型
#转为list类型
state_pay_List=list(state_pay)
#转为DataFrame类型
state_pay_Data = pd.DataFrame(state_pay_List,columns=["state","交易额"])
state_pay_Data=state_pay_Data.set_index("state")
print(state_pay_Data)
#绘图
#创建画板
plt.figure(figsize=(10,5),dpi=80)
#绘图
state_pay_Data.plot(kind='bar',label="交易额",figsize=(12,6))
#plt.bar - 这个网站可出售。 - 最佳的Server monitoring 来源和相关信息。(range(len(state_pay_Data.index)),state_pay_Data['交易额'],label="交易额")
#设置轴标签
plt.ylabel("交易额")
#设置图例
plt.legend(loc="center right")
#设置x轴刻度
plt.xticks(range(len(state_pay_Data.index)),state_pay_Data.index,rotation=0,ha='center')
#绘制累计曲线
plt.twinx()
#累计百分比
p=state_pay_Data["交易额"].cumsum()/state_pay_Data["交易额"].sum()
print(p)
#找出累计80%的点
key=p[p>0.8].index[0]
#找到点对应的位置
key_num=state_pay_Data.index.tolist().index(key)
#输出结果
print("累计超过80%的州:",key)
print("累计超过80%的州的索引位置:",key_num)
print("---------------------------------")
#显示核心州
key_state=state_pay_Data[:key]
print("核心州:",key_state)
#绘制曲线
p.plot(color = 'orange',style = '-o',linewidth=1) #次坐标曲线
#设置80%标识线
plt.axvline(key_num,hold=None,color="red",linestyle="--")
#设置80%文本
plt.text(key_num+0.2,p[key]-0.02,"累计占比为:%.2f%%"%(p[key]*100),color="red")
#设置轴标签
plt.ylabel("交易额占比")
#整个图标题
plt.title("州交易额贡献分布情况",fontsize=15)
plt.show()结果如下:
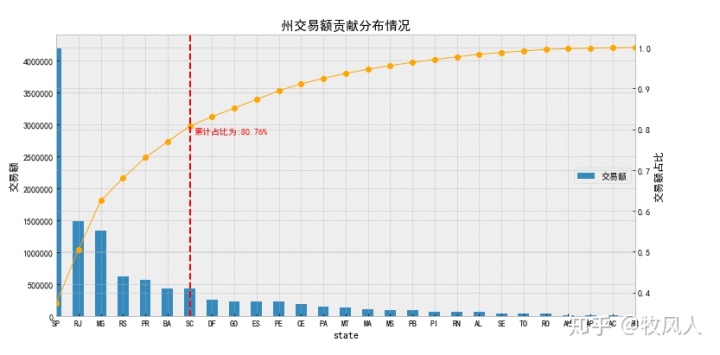
根据实际业务情况提出问题并找出问题的原因是数据分析的关键,在分析数据的过程中,如何选择合适的模型是重中之重,以上只是对数据分析流程的操作做了大概的总结。















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









