





【关键术语】
Redo log file 重做日志文件
Archive log file 归档日志文件
SCN(system change number)系统改变号
Checkpoint 检查点
Log switch 日志切换
Redo entry 重做条目
Log sequence number 日志序列号
Log file groups 重做日志组
Archive mode 归档模式
1.1 重做日志文件
在数据库的使用过程中,可能会出现断电、死机等意外情况,在出现意外时如何保证数据的有效性、一致性和完整性?Oracle 作为大型关系数据库管理系统,必须要通过合理的机制确保在任何情况下都不会出现数据丢失,通过合理的配置重做日志可以实现并完成这项任务。利用重做日志文件,在数据库发生故障时,可以重新处理事务。每个事务在处理的同也会写入重做日志缓冲区,然后由 LGWR 进程写入到重做日志文件,这样,如果发生介质故障,重做日志文件将提供恢复机制。(但也存在例外情况,例如,在启用 NOLOGGING 子句的情况下对象中的直接加载插入。)重做日志文件用来在例程失败等情况下恢复尚未写入数据文件的但是已提交的数据。重做日志文件只用于恢复。
在 Oracle 当中,事务对数据库所做的修改将以重做记录的形式保存重做日志缓存中。在提交事务时,由 LGWR 进程将缓存中该事务相关的重做记录全部写入重做日志文件,这时,事务认为已经成功提交。这种机制称为“快速提交”。
1.1.1 重做日志结构
重做日志文件具有以下特征:
- • 记录对数据所做的所有更改
- • 提供恢复机制
- • 可以划分成组
- • 至少需要两个组
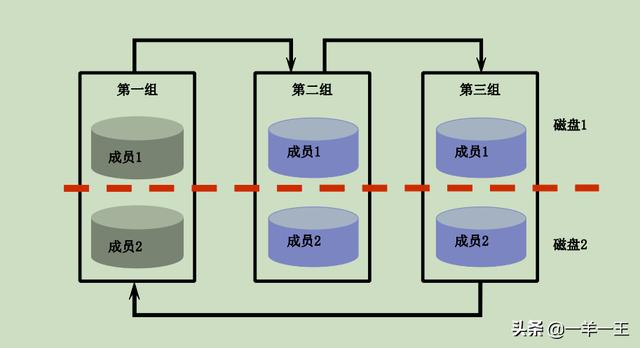
那么什么是日志组呢(Redo Log Group)?重做日志组是一组相同的重做日志文件副本,LGWR 后台进程向组内所有联机重做日志文件并发写入相同信息,为保证数据库的正常操作,Oracle 服务器最少需要两个联机重做日志文件组。属于同一日志组的每个日志文件被称为日志成员,并且同一个日志组的不同日志成员互为镜像,即组内的每个成员都有相同的日志序列号和同样的大小。Oracle 服务器每次写入日志组时,都分配一个日志序列号以唯一地标识每个重做日志文件。当前日志序列号存储在控制文件和所有数据文件的头部。在Oracle 数据库中,多个重做日志组是循环使用的,如图 p1-1 所示。
假定数据库包含三个日志组,在图 6-1 中,初始阶段后台进程 LGWR 将事务变化写入到日志组一的两个成员中;在日志组一写满之后,LGWR 进程切换到日志组二,并将事变化写入到日志组二的两个成员中;在日志组二写满之后,LGWR 进程切换到日志组三,并将事务变化写入到日志组三;在日志组三写满之后,LGWR 又切换回日志组一,并将事务变化写入到日志组一,覆盖原有记录。经过以上说明,大家可以知道,所有事务变化都可以通过日志组予以保留(归档方式下)。这样,即使将来出现实例失败(Instance Failure)或介质失败(Media Failure)时,DBA 将会使用这些已经保留下来的事务变化进行实例恢复或介质恢复,最终可以确保 Oracle 不会出现数据丢失。
以下查询显示了当前数据库的重做日志文件的位置和名称。当前数据库共有 3 个日志文件 REDO01.LOG、REDO02.LOG 和 REDO03.LOG,位于 D:ORACLEORADATADB01目录下。
SQL> SELECT member FROM v$logfile;MEMBER------------------------------------------D:ORACLEORADATADB01REDO03.LOGD:ORACLEORADATADB01REDO02.LOGD:ORACLEORADATADB01REDO01.LOG1.1.2 日志序列号和日志切
Oracle 服务器将对数据库所做的所有更改按顺序记录到重做日志缓冲区中。LGWR 进程把重做条目从重做日志缓冲区写入联机重做日志组的其中一个组,这个组叫做当前重做日志组。LGWR 进程将在以下情况下写入:
- • 当提交事务处理时(Commit)
- • 当重做日志缓冲区被写满三分之一时
- • 当重做日志缓冲区内的已更改记录超过 1MB 时
- • 每隔 3 秒
- • 在 DBWn 将数据库缓冲区高速缓存中修改的块写入数据文件之前
重做日志文件是以循环方式使用的。每个重做日志文件组用一个递增日志序列号来标识,每次重新使用日志时就会覆盖原来的序列号。
LGWR 按顺序向联机重做日志组写入重做信息。一旦当前联机重做日志组被写满,LGWR 就开始写入下一个组。这称为日志切换(Log Switch)。当最后一个可用联机重做日志文件已满时,LGWR 将返回第一个联机重做日志文件组并开始重新写入。假定数据库有三个重做日志组,第一个日志组为当前日志组,当前日志序列号为 56,LGWR 进程将事务变化写入第一个重做日志组中,当第一个日志组写满后,LGWR 进程自动切换到第二个日志组,在进行日志切换时,Oracle 服务器完成如下任务:
- • 日志序列号自动加 1,即当前日志序列号变为 57,并且将日志序列号连同 SCN 息写入到控制文件的日志历史记录中。
- • 促使 CKPT 进程发出检查点,从而使得后台进程 CKPT 将检查点时刻的 SCN 信息写入到控制文件和数据文件头部,并促使后台进程 DBWR 将数据高速缓存中的缓冲区写入到数据文件中。
- • 当数据库处于 ARCHIVELOG 模式时,日志切换还会促使 ARCH 进程开始归档。
当日志组写满之后 Oracle Server 会自动进行日志切换;另外,在一些特定情况 DBA 还可以强制系统进行日志切换,这要求用户必须具有 ALTER SYSTEM 系统权限。例如:果要删除正在使用的日志组,那么首先强制日志切换;当日志组很大,需要很长时间才能写满时,可以强制执行日志切换,以避免重做日志损坏所带来的损失。强制日志切换的命令如下:
ALTER SYSTEM SWITCH LOGFILE。
【实例 】切换日志,显示日志状态。1)以管理员身份登录SQL> CONNECT / AS SYSDBA已连接。2)显示日志状态SQL> SELECT GROUP#,SEQUENCE#,MEMBERS,STATUS FROM V$LOG;GROUP# SEQUENCE# MEMBERS STATUS---------- ---------- ---------- ----------------1 306 1 INACTIVE2 307 1 ACTIVE3 308 1 CURRENT3)切换日志SQL> ALTER SYSTEM SWITCH LOGFILE;系统已更改。4)重新显示日志状态SQL> SELECT GROUP#,SEQUENCE#,MEMBERS,STATUS FROM V$LOG;GROUP# SEQUENCE# MEMBERS STATUS---------- ---------- ---------- ----------------1 309 1 CURRENT2 307 1 INACTIVE3 308 1 ACTIVE由实例可见,数据库工作一共有 3 个重做日志组,组号是 1、2 和 3,每个组有一个成员。日志切换前,当前日志组为 3(状态为 CURRENT),对应的最大日志序号为 308。日志切换后,最小日志序号的日志组 1 被覆盖,日志序号增一变为 309,并成为新的当前日志组。日志组就是这样被循环的使用。1
1.1.3 检查点
在介绍检查点之前,首先回顾一下实例恢复。假定当前日志序列号为 56,先前检查点时的 SCN 值为 3456231,并且该 SCN 值被记载到了控制文件和数据文件头部,某用户执了事务变化操作,并提交了事务,SCN 值变化为 3456239,并且此时突然出现了系统断电,那么首先应考虑控制文件、数据文件和重做日志的 SCN 值分别为多少。因为只有在发出检查点才会将 SCN 信息写入到控制文件和数据文件头部,所以控制文件和数据文件的 SCN 值都是 3456231,而当执行了提交操作后,重做记录连同 SCN 会写入到重做日志文件,所以此时重做日志文件的当前 SCN 值为 3456239。因为数据文件、控制文件的 SCN 一致,而与重做日志所记录的 SCN 不一致,所以在重新启动 Oracle Server 时后台进程 SMON 会进行实例恢复,此时 SMON 程将自动重新执行从 3456231 至 3456239 之间的所有事务变化,然后才会打开数据库。重做日志为何被称为“Redo Log File”?因为在进行实例恢复或介质恢复时要重新执行日志文件记录的所有事务变化。
1.生成检查点
检查点(Checkpoint)是一个数据库事件,它用于同步所有数据文件、控制文件以及重做日志文件。当后台进程 CKPT 发出检查点时,会执行以下两个任务:
1)后台进程 CKPT 会修改控制文件和数据文件头部,并将当前 SCN 信息写入到这两种文件中,从而使得数据文件、控制文件和重做日志处于一致状态,这就是为何在执行SHUTDOWN NORMAL、SHUTDOWN TRANSACTIONAL 和 SHUTDOWN IMMEDIATE 之后不需要实例恢复(执行这些操作会发出检查点),而执行了 SHUTDOWN ABORT(不强发出检查点)之后需要进行实例恢复的原因。当启动 Oracle 服务器时,后台进程 SMON 总是会检查控制文件、数据文件以及重做日志的一致性:
- • 如果数据文件、控制文件、重做日志的当前 SCN 值完全一致,则系统会直接打开所有数据文件和重做日志。
- • 如果控制文件和数据文件的当前 SCN 值完全一致匹配,并小于重做日志的当前SCN,则需要进行实例恢复(例如执行 SUHTDOWN ABORT 后)。
- • 如果控制文件和数据文件的当前 SCN 值不匹配,则表示数据文件或控制文件存在损坏,此时就需要进行介质恢复,以恢复损坏的物理文件。
2)当后台进程 CKPT 工作时,同时会促使后台进程 DBWn 开始工作,并且将数据库高速缓存中的脏缓冲区(Dirty Buffer )写入到数据文件中。
检查点可发生在下面情况中:
- • 每次日志切换时
- • 当使用 NORMAL、TRANSACTIONAL、IMMEDIATE 选项关闭例程时
- • 通过设置初始化参数 FAST_START_MTTR_TARGET 强制执行时
- • 数据库管理员通过手动方式请求时
- • ALTER TABLESPACE [OFFLINE NORMAL|READ ONLY|BEGIN BACKUP]命令导致对特定数据文件执行检查点操作时。
2.强制检查点
假定数据库包含两个日志组,每个日志组尺寸为 100MB,并且初始阶段只有在日志切换时才会发出检查点。假定当前日志组为日志组一,当该日志组写满之后,系统会自动切到日志组二,并发出检查点将 SCN 信息写入到数据文件和控制文件。如果在日志组二记了 90MB 事务变化之后,系统出现断电。可以设想一下,数据库还能使用吗?答案是肯定的,将来在重新启动 Oracle Server 时后台进程 SMON 会自动执行实例恢复,最终将数据文件、控制文件、重做日志转变为一致状态。当进行实例恢复时,SMON 首先重新执行事务,然后打开数据库,最后回退未提交的事务。因为 SMON 需要重新执行日志组二所记载的 90MB事务变化,从而会使得实例恢复需要很长时间。为了降低实例恢复时间,必须要增加检查点次数。
日志切换和检查点操作是在数据库运行中的某些特定点自动执行的,但 DBA 可以强制执行日志切换或检查点操作。强制执行检查点有两种方式:
1)设置 FAST_START_MTTR_TARGET
可以在初始化参数文件中设置此参数,代表实例恢复所用时间,单位为秒。例如:设FAST_START_MTTR_TARGET=300,代表如果数据库需要实例恢复,那么恢复的时间不超过 300 秒。系统会根据 300 秒时间自动计算可以保留的脏块的数目,如果超过则自动发出检查点。
2)ALTER SYSTEM CHECKPOINT 命令
必要时,DBA 也可以手动发出检查点命令,命令如下:ALTER SYSTEM CHECKPOINT.
1.1.4 日志管理策略
要确定一个数据库例程的联机重做日志文件的合适数量,必须测试不同的配置。在规划重做日志的配置时,需考虑如下几点:
1)重做日志组的个数
在某些情况下,数据库例程可能只需要两个组。在其它情况下,数据库例程可能需要更多的组以保证各个组始终可供 LGWR 进程使用。例如,如果跟踪文件或警告文件中出现如下消息:Checkpoint not complete 或 Redo Log Group not archived,表明 LGWR 经常不得不因为检查点操作尚未完成或者日志组尚未归档而等待,这时就需要添加日志组。
2)重做日志文件的复用
重做日志对于数据库正常运作和维护都是至关重要,因此建议创建复用重做日志文件来提高重做日志的可靠性。即一个重做日志组中包含多个互为镜像的重做日志成员。复用重做日志文件后,LGWR 进程将同步写入位于一个重做日志组中的多个成员日志文件,即多个日志成员是互为镜像的关系,因此,即使由于某个单独的日志文件破坏或丢失,数据库运行和恢复也不受任何影响。
尽管 Oracle 服务器允许多元备份的组可以包含不同数量的成员,但应该尽量建立对称配置。不对称配置应只是非常情况(如磁盘故障)的临时结果。在这种情况下,必须先创建新的不同大小的联机重做日志文件组,然后删除旧组。
3)重做日志文件的位置
复用联机重做日志文件时,最好将组内的成员放置在不同磁盘上。这样即使一个日志员所在磁盘发生物理损坏,而其它的日志成员至少还有一个是可用,那么数据库实例不会被中断动行。将归档日志文件和联机重做日志文件分放在不同磁盘上,以减少 ARCn 和 LGWR后台进程之间的争用。数据文件和联机重做日志文件应当放置在不同的磁盘上以减 少LGWR 和 DBWn 的争用,并降低发生介质故障时同时丢失数据文件和联机重做日志文件的风险。
4)重做日志文件的大小
联机重做日志文件最小为 50 KB,最大文件大小视操作系统而定。假定日志组尺寸很小(500KB),那么可能会导致日志切换非常频繁,间接地增加检查点次数,从而降低系统性能;假定日志组尺寸很大(100MB),那么出现意外情况时可能会导致实例恢复的时间很长。Oracle推荐日志切换时间应该在 20—30min 之间,至于到底应该将日志组尺寸设置为多少,还应该根据实际情况进行反复测试。
另外,如果数据库处于 ARCHIVELOG 模式,还应该考虑存放归档日志的存储介质(磁带或磁盘),以使得存储介质剩余空间最小。例如,假定磁带空间为 100MB,并且该磁带只能存放两个归档日志,那么设置重做日志的尺寸略低于 50MB。
下面的情况可能影响联机重做日志文件的配置:
- • 日志切换和检查点的数量
- • 重做记录的量和个数
- • 存储介质的空间量;例如,启用归档时归档文件所在磁盘上的空间量

写在最后的话
感谢各位的支持与阅读,后续会继续推送相关知识和交流,欢迎交流、转发和关注,感谢!














 5650
5650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









