





话不多说先上代码:
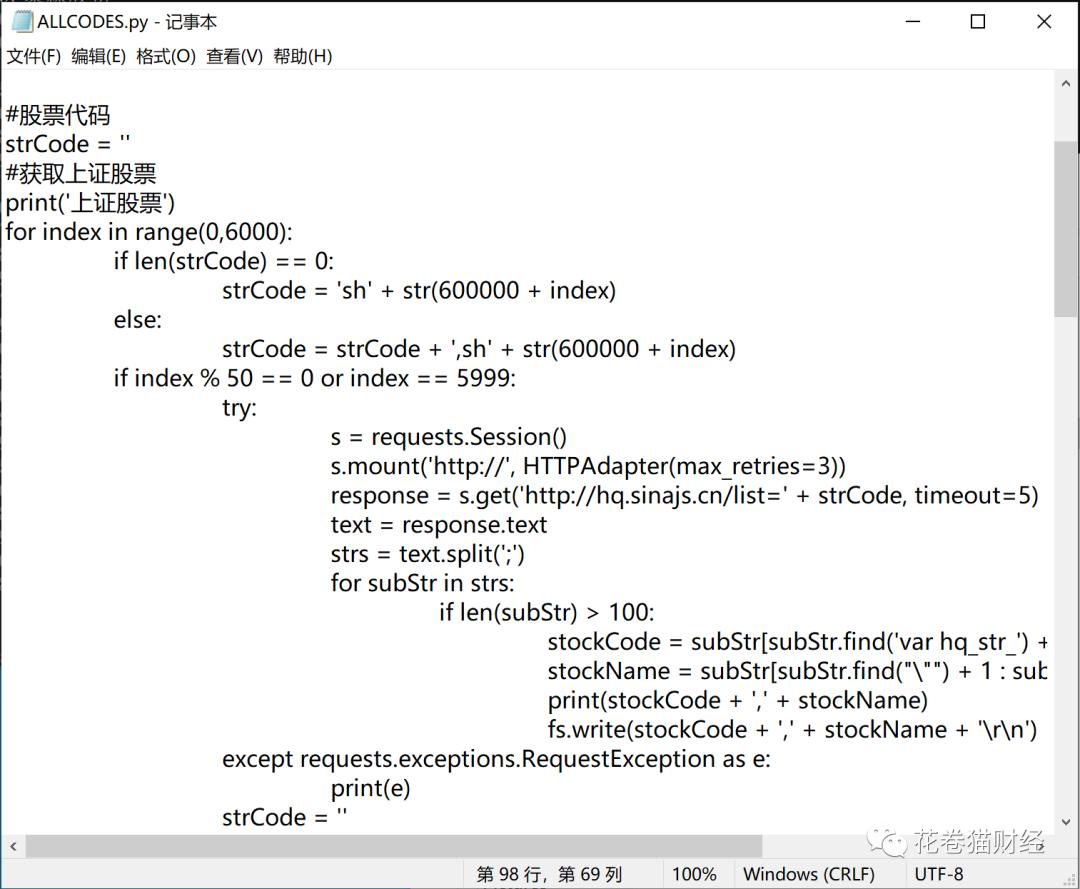
import os#这里可能需要pip install requestsimport requestsfrom requests.adapters import HTTPAdapter#打开日志文件fs = open(r'C:\Py\codes.txt','a+')#股票代码strCode = ''#获取上证股票for index in range(0,6000): if len(strCode) == 0: strCode = 'sh' + str(600000 + index) else: strCode = strCode + ',sh' + str(600000 + index) if index % 50 == 0 or index == 5999: try: s = requests.Session() s.mount('http://', HTTPAdapter(max_retries=3)) response = s.get('http://hq.sinajs.cn/list=' + strCode, timeout=5) text = response.text strs = text.split(';') for subStr in strs: if len(subStr) > 100: stockCode = subStr[subStr.find('var hq_str_') + len('var hq_str_') : subStr.find('=')] stockName = subStr[subStr.find("\"") + 1 : subStr.find(',')] print(stockCode + ',' + stockName) fs.write(stockCode + ',' + stockName + '\r\n') except requests.exceptions.RequestException as e: print(e) strCode = ''#深证股票for index in range(0,4000): if len(strCode) == 0: strCode = 'sz' + str(1000000 + index)[1 : 7] else: strCode = strCode + ',sz' + str(1000000 + index)[1 : 7] if index % 50 == 0 or index == 3999: try: s = requests.Session() s.mount('http://', HTTPAdapter(max_retries=3)) response = s.get('http://hq.sinajs.cn/list=' + strCode, timeout=5) text = response.text strs = text.split(';') for subStr in strs: if len(subStr) > 100: stockCode = subStr[subStr.find('var hq_str_') + len('var hq_str_') : subStr.find('=')] stockName = subStr[subStr.find("\"") + 1 : subStr.find(',')] print(stockCode + ',' + stockName) fs.write(stockCode + ',' + stockName + '\r\n') except requests.exceptions.RequestException as e: print(e) strCode = ''#创业板股票for index in range(0,1200): if len(strCode) == 0: strCode = 'sz' + str(300000 + index) else: strCode = strCode + ',sz' + str(300000 + index) if index % 50 == 0 or index == 1199: try: s = requests.Session() s.mount('http://', HTTPAdapter(max_retries=3)) response = s.get('http://hq.sinajs.cn/list=' + strCode, timeout=5) text = response.text strs = text.split(';') for subStr in strs: if len(subStr) > 100: stockCode = subStr[subStr.find('var hq_str_') + len('var hq_str_') : subStr.find('=')] stockName = subStr[subStr.find("\"") + 1 : subStr.find(',')] print(stockCode + ',' + stockName) fs.write(stockCode + ',' + stockName + '\r\n') except requests.exceptions.RequestException as e: print(e) strCode = ''#科创版股票for index in range(0,1000): if len(strCode) == 0: strCode = 'sh' + str(688000 + index) else: strCode = strCode + ',sh' + str(688000 + index) if index % 50 == 0 or index == 999: try: s = requests.Session() s.mount('http://', HTTPAdapter(max_retries=3)) response = s.get('http://hq.sinajs.cn/list=' + strCode, timeout=5) text = response.text strs = text.split(';') for subStr in strs: if len(subStr) > 100: stockCode = subStr[subStr.find('var hq_str_') + len('var hq_str_') : subStr.find('=')] stockName = subStr[subStr.find("\"") + 1 : subStr.find(',')] print(stockCode + ',' + stockName) fs.write(stockCode + ',' + stockName + '\r\n') except requests.exceptions.RequestException as e: print(e) strCode = ''#关闭文件流fs.close()新建一个文件,命名为ALLCODES.py,并将上述代码粘贴到你的文件中。

如果没有安装Python,就到这个地址下载安装一下:
https://www.python.org/ftp/python/3.9.0/python-3.9.0-amd64.exe
注意第一个界面的Add to Path一定要勾上。
然后你需要安装Pip,下载地址是:
https://bootstrap.pypa.io/get-pip.py
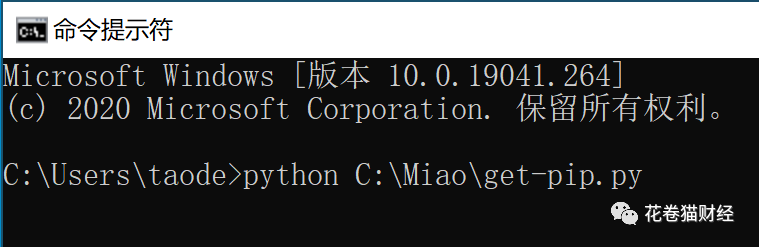
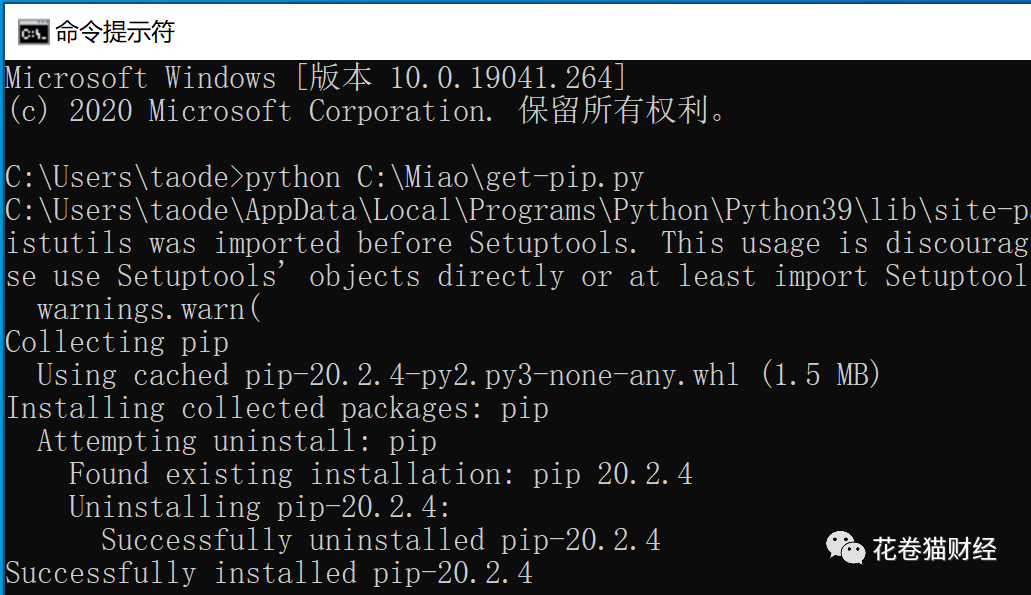
保存到电脑中,在命令行中输入如下命中后执行:
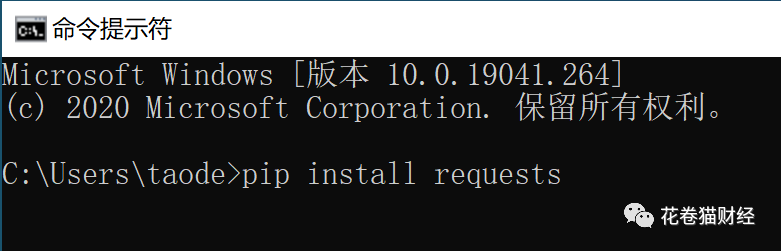
安装成功后,在用pip来安装http服务requests:
打开命令提示行,输入python C:\PY\ALLCODES.py
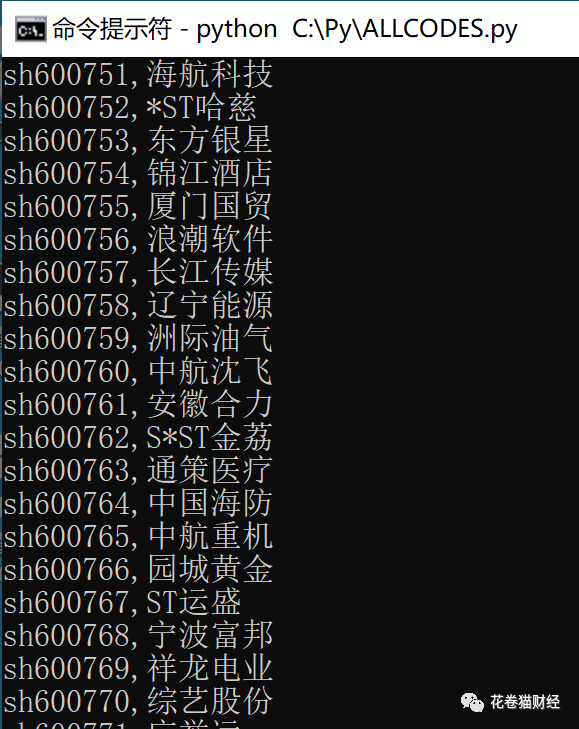
输入回车运行脚本,得到如下结果:
result.txt中也输出了结果:

网上能自动拉取实时码表的接口极少,这里采用了试错法,例如上证指数是从600000开始的,然后不断累加1,用新浪接口来查询是否存在行情,如果存在就摘取名称和其他信息。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









