







上篇:用户行为数据采集 第6节 数仓采集Kafka Manager安装脚本测试
1、项目经验之Kafka压力测试
-
Kafka压测
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈CPU,内存,网络IO)。一般都是网络IO达到瓶颈
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh -
Kafka Producer压力测试
(1)在module/kafka/bin目录下面有这两个文件。我们来测试一下
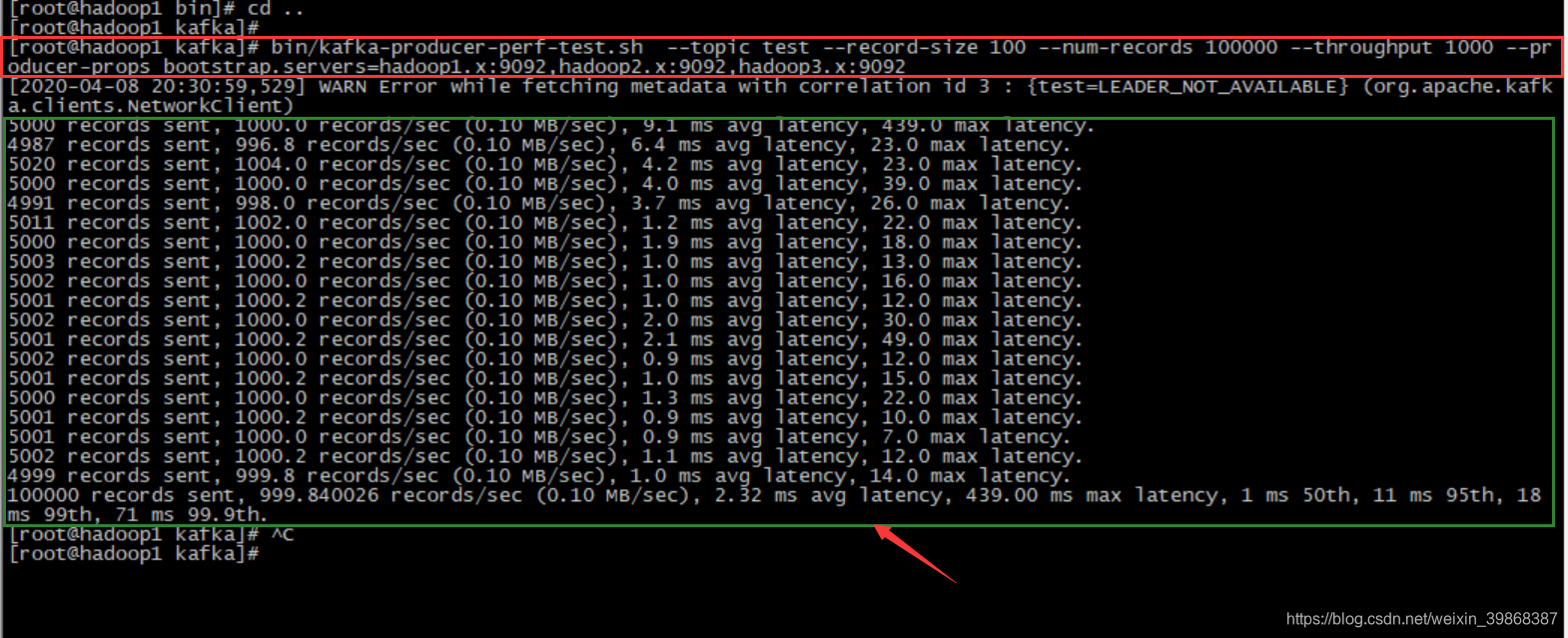
[root@hadoop1 kafka]# bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 1000 --producer-props bootstrap.servers=hadoop1.x:9092,hadoop2.x:9092,hadoop3.x:9092
//发送延迟时间
[2020-04-08 20:30:59,529] WARN Error while fetching metadata with correlation id 3 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 9.1 ms avg latency, 439.0 max latency.
4987 records sent, 996.8 records/sec (0.10 MB/sec), 6.4 ms avg latency, 23.0 max latency.
5020 records sent, 1004.0 records/sec (0.10 MB/sec), 4.2 ms avg latency, 23.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 4.0 ms avg latency, 39.0 max latency.
4991 records sent, 998.0 records/sec (0.10 MB/sec), 3.7 ms avg latency, 26.0 max latency.
5011 records sent, 1002.0 records/sec (0.10 MB/sec), 1.2 ms avg latency, 22.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 1.9 ms avg latency, 18.0 max latency.
5003 records sent, 1000.2 records/sec (0.10 MB/sec), 1.0 ms avg latency, 13.0 max latency.
5002 records sent, 1000.0 records/sec (0.10 MB/sec), 1.0 ms avg latency, 16.0 max latency.
5001 records sent, 1000.2 records/sec (0.10 MB/sec), 1.0 ms avg latency, 12.0 max latency.
5002 records sent, 1000.0 records/sec (0.10 MB/sec), 2.0 ms avg latency, 30.0 max latency.
5001 records sent, 1000.2 records/sec (0.10 MB/sec), 2.1 ms avg latency, 49.0 max latency.
5002 records sent, 1000.0 records/sec (0.10 MB/sec), 0.9 ms avg latency, 12.0 max latency.
5001 records sent, 1000.2 records/sec (0.10 MB/sec), 1.0 ms avg latency, 15.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 1.3 ms avg latency, 22.0 max latency.
5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.9 ms avg latency, 10.0 max latency.
5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.9 ms avg latency, 7.0 max latency.
5002 records sent, 1000.2 records/sec (0.10 MB/sec), 1.1 ms avg latency, 12.0 max latency.
4999 records sent, 999.8 records/sec (0.10 MB/sec), 1.0 ms avg latency, 14.0 max latency.
100000 records sent, 999.840026 records/sec (0.10 MB/sec), 2.32 ms avg latency, 439.00 ms max latency, 1 ms 50th, 11 ms 95th, 18 ms 99th, 71 ms 99.9th.
[root@hadoop1 kafka]#
说明: record-size是一条信息有多大,单位是字节。
num-records是总共发送多少条信息。
throughput是每秒多少条信息。
Kafka会打印下面的信息,如图表示:
参数解析:
本例中一共写入10w条消息,每秒向Kafka写入了0.10MB的数据,平均是1000条消息/秒,每次写入的平均延迟为0.8毫秒,最大的延迟为254毫秒。
- Kafka Consumer压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[root@hadoop1 kafka]# bin/kafka-consumer-perf-test.sh --zookeeper hadoop1.x:2181 --topic test --fetch-size 10000 --messages 10000000 --threads 1
//消费数据
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2020-04-09 14:02:24:573, 2020-04-09 14:02:32:454, 9.5367, 1.2101, 100000, 12688.7451
参数说明:
–zookeeper 指定zookeeper的链接信息
–topic 指定topic的名称
–fetch-size 指定每次fetch的数据的大小
–messages 总共要消费的消息个数 测试结果说明: start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2020-04-09 14:02:24:573, 2020-04-09 14:02:32:454, 9.5367, 1.2101, 100000, 12688.7451
开始测试时间,测试结束数据,最大吞吐率9.5367MB/s,平均每秒消费1.2101/s,最大每秒消费100000条,平均每秒消费12688.7451条。
2、项目经验之Kafka机器数量计算
Kafka机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
先要预估一天大概产生多少数据,然后用Kafka自带的生产压测(只测试Kafka的写入速度,保证数据不积压),计算出峰值生产速度。再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们采用压力测试测出写入的速度是10M/s一台,峰值的业务数据的速度是50M/s。副本数为2。
Kafka机器数量=2*(50*2/100)+ 1=3台
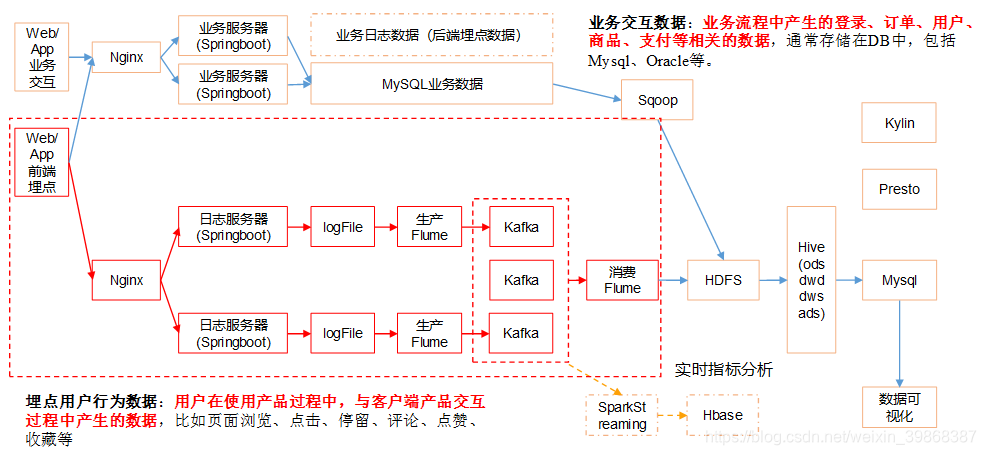
3、消费Kafka数据Flume
架构图:
集群规划
| 服务器hadoop1.x | 服务器hadoop2.x | 服务器hadoop3.x | |
|---|---|---|---|
| Flume(消费Kafka) | Flume |
日志消费Flume配置
-
Flume配置分析
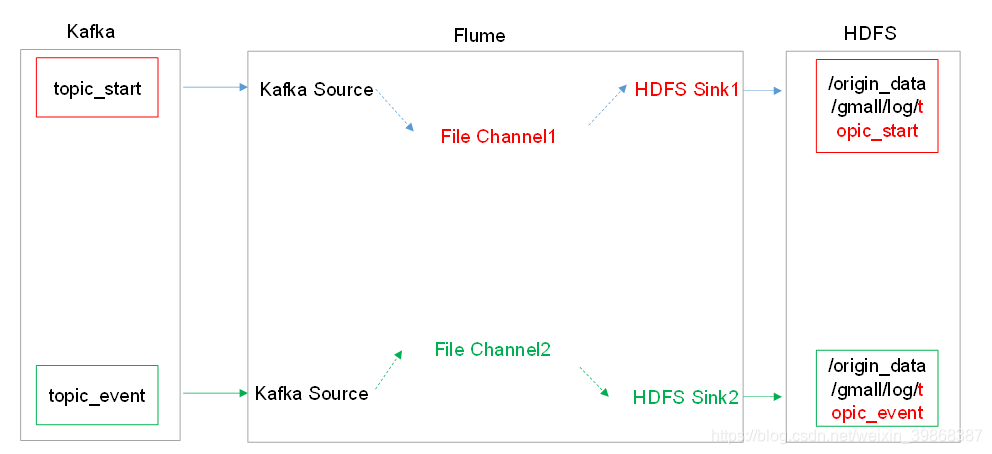
-
Flume的具体配置如下:
(1) 在hadoop1.x的module/flume-1.7.0/conf目录下创建kafka-flume-hdfs.conf文件
[root@hadoop1 conf]# vim kafka-flume-hdfs.conf
//在文件配置如下内容
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop1.x:9092,hadoop2.x:9092,hadoop3.x:9092
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop1.x:9092,hadoop2.x:9092,hadoop3.x:9092
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/local/etc/hadoop/module/flume-1.7.0/checkpoint/behavior1
a1.channels.c1.dataDirs = /usr/local/etc/hadoop/module/flume-1.7.0/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = /usr/local/etc/hadoop/module/flume-1.7.0/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2
配置属性说明图

2) 编写这个配置的脚本
(1) 在/home/MrZhou/bin目录下创建脚本f2.sh
[root@hadoop1 bin]# vim f2.sh
//在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop3.x
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /usr/local/etc/hadoop/module/flume-1.7.0/bin/flume-ng agent --conf-file /usr/local/etc/hadoop/module/flume-1.7.0/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/usr/local/etc/hadoop/module/flume-1.7.0/log.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop3.x
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
(2) 增加脚本执行权限
[root@hadoop1 bin]# chmod 777 f2.sh
(3) 查看当前进程
[root@hadoop1 bin]# ./xcall.sh jps
--------- hadoop1.x ----------
12514 ResourceManager
12195 DataNode
12933 Jps
10150 QuorumPeerMain
12630 NodeManager
10443 Kafka
12364 SecondaryNameNode
12063 NameNode
--------- hadoop2.x ----------
7728 QuorumPeerMain
8460 Jps
8013 Kafka
--------- hadoop3.x ----------
7987 Kafka
7702 QuorumPeerMain
8441 Jps
(4) f2集群启动脚本
[root@hadoop1 bin]# ./f2.sh start
--------启动 hadoop3.x 消费flume-------
是否启动起来,在hadoop3.x看日志
[root@hadoop3 flume-1.7.0]# ll
total 144
drwxr-xr-x. 2 root root 62 Apr 6 00:37 bin
-rw-r--r--. 1 root root 77387 Apr 6 00:37 CHANGELOG
drwxr-xr-x. 2 root root 118 Apr 7 23:05 conf
-rw-r--r--. 1 root root 6172 Apr 6 00:37 DEVNOTES
-rw-r--r--. 1 root root 2873 Apr 6 00:37 doap_Flume.rdf
drwxr-xr-x. 10 root root 4096 Apr 6 00:37 docs
drwxr-xr-x. 2 root root 4096 Apr 6 00:37 lib
-rw-r--r--. 1 root root 27625 Apr 6 00:37 LICENSE
-rw-r--r--. 1 root root 2079 Apr 9 11:12 log.txt
-rw-r--r--. 1 root root 249 Apr 6 00:37 NOTICE
-rw-r--r--. 1 root root 2520 Apr 6 00:37 README.md
-rw-r--r--. 1 root root 1585 Apr 6 00:37 RELEASE-NOTES
drwxr-xr-x. 2 root root 68 Apr 6 00:37 tools
//查看尾部日志
[root@hadoop3 flume-1.7.0]# tail -f log.txt
//信息如下:
Info: Including Hadoop libraries found via (/usr/local/etc/hadoop/module/hadoop-2.7.2/bin/hadoop) for HDFS access
Info: Including Hive libraries found via () for Hive access
+ exec /usr/local/etc/java/moduce/jdk1.8.0_221/bin/java -Xmx20m -Dflume.root.logger=INFO,LOGFILE -cp '/usr/local/etc/hadoop/module/flume-1.7.0/lib/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/etc/hadoop:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/common/lib/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/common/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/hdfs:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/hdfs/lib/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/hdfs/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/yarn/lib/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/yarn/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/mapreduce/lib/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/mapreduce/*:/usr/local/etc/hadoop/module/hadoop-2.7.2/contrib/capacity-scheduler/*.jar:/lib/*' -Djava.library.path=:/usr/local/etc/hadoop/module/hadoop-2.7.2/lib/native org.apache.flume.node.Application --conf-file /usr/local/etc/hadoop/module/flume-1.7.0/conf/kafka-flume-hdfs.conf --name a1
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/etc/hadoop/module/flume-1.7.0/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/etc/hadoop/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
20/04/09 11:12:48 ERROR node.Application: A fatal error occurred while running. Exception follows.
org.apache.commons.cli.ParseException: The specified configuration file does not exist: /usr/local/etc/hadoop/module/flume-1.7.0/conf/kafka-flume-hdfs.conf
at org.apache.flume.node.Application.main(Application.java:316)
待解决!!!!
遇到问题,无法HDFs没有数据














 3920
3920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









