





大家好,今天给大家带来本人经过7小时钻研爬虫,从requests库爬取失败,寻找原因→学习selenium库进行网页动态模拟→一步步尝试+改错后爬出第一条内容→模拟浏览器进行点击操作爬取更多内容→完善代码,整个过程有太多心酸泪水,现就将今天的各种发现、代码总结在这里(1600多字),一起快乐爬虫~
(以后再展示具体数据可视化、分析)
(文中展示具体操作步骤与思路,爬虫代码整体附在最后,喜欢的话记得给我点赞哟hhhhh)
开始正文:
主要使用技术:selenium动态模拟浏览器并爬取内容、正则表达式匹配需要信息、读写文件
先给大家介绍一下本次爬取对象,Mooc上首都经济贸易大学刘经纬老师的《零基础学Python人工智能》,链接为:https://www.icourse163.org/learn/CUEB-1450000234?tid=1450406511#/learn/content,此外老师还有《零基础做毕业设计(Web开发与创新创业思维)》,欢迎大家进行学习~
本次爬取的签到,在“课件”→“第一章python准备”→“签到”中,先展示一下页面:
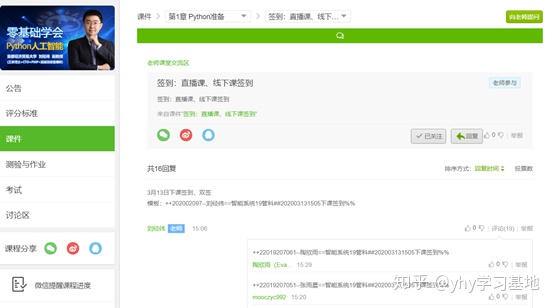
爬取后的结果为:(各列分别为学号、名字、班级、时间戳)

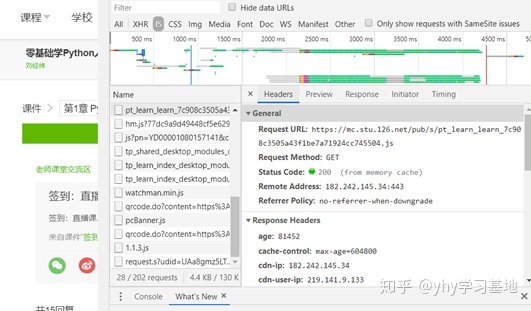
首先需要查看一下网页类型,鼠标右键→检查→选择Network→刷新页面→双击第一个文件,如下图,可看到Request Method为GET类型,不为post类型,则不需要request body传递参数,直接复制url即可。
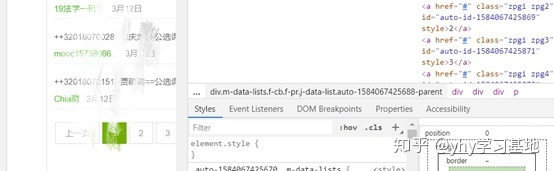
接下来具体点击Elements审查元素,查看需要的内容具体在哪里:
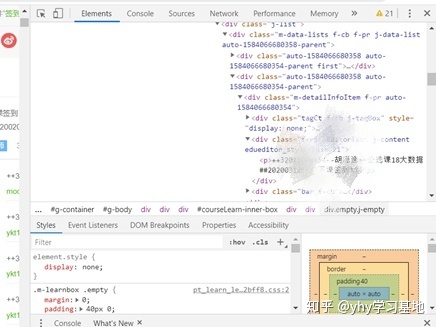
根据内容写出正则表达式:
+第一次尝试爬取(失败):
思路:使用request爬取网页整体源代码,使用正则表达式匹配出需要的内容
结果:返回的列表为空,没匹配到我需要的内容
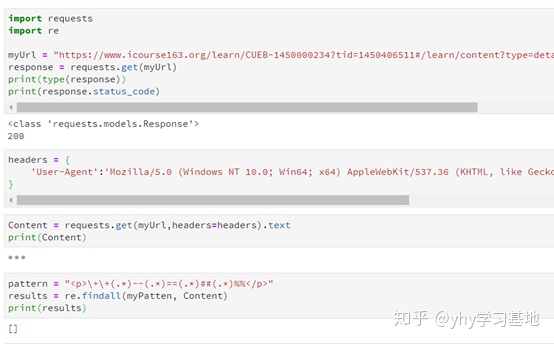
失败理由:使用requests.get(myUrl,headers=headers).text查看爬取网页的源代码,发现爬取出的内容与自己审查元素中看到的代码不一样。花了一番时间各种百度无果,上某宝花了10元向别人咨询,告诉我这种情况说明页面需要浏览器引擎动态渲染,需要用headless browser。
得到这个建议后说实话内心是有点懵的,于是又开始各种百度,发现有人针对动态渲染使用了selenium库!!!!于是开始寻找资料学习selenium库。
推荐上selenium库官方文档进行学习:https://selenium-python.readthedocs.io/
=============以下开始讲解成功的办法===========
通过一番学习,开始第二次尝试(成功):
整体思路:selenium模拟浏览器,定位提取出需要的信息→正则表达式对提取出的内容进行匹配→转化为列表形式,写入csv文件
- 使用selenium库,webdriver.Chrome( )模拟打开Chrome浏览器,输入url,打开“签到”页面,通过find_element_by_xpath定位到我需要的元素,通过.text得到元素中的文本内容。最终获取单条数据成功
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = "https://www.icourse163.org/learn/CUEB-1450000234?tid=1450406511#/learn/content?type=detail&id=1229081086"
browser.get(url)
browser.implicitly_wait(10)
input = browser.find_element_by_xpath("//*[@id="courseLearn-inner-box"]/div/div/div[3]/div[1]/div[2]/div/div/div[4]/div/div[1]/div[1]/div[1]/div[2]/div[1]/div[1]/div/div[1]/div[1]/div[1]/div/div[2]")
print(input.text)注意:
- selenium的find_element方法有很多可通过定位查找元素的方式,如通过id、class、css等(如果对class、css这些不了解,建议上“菜鸟驿站”网站,了解一下html网页编程,了解网站原理才能更好的爬取)。
- 原本使用的是class_name定位,但是返回为空,代码找不到我的元素(具体理由不知),然后换为通过xpath定位,定位成功
- 获取需要的信息xpath编码的方式:鼠标放在需要的元素处→右键→copy→copy XPath,自动复制其xpath编码,粘贴到代码引号中即可。注意粘贴时,编码中有引号的,要手动给她加上’’
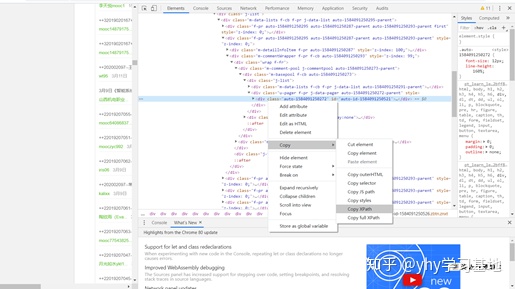
2.爬取整个页面所有的文字内容并写入txt文件保存,为方便调用,我将获取网页文本内容的代码与写入txt文件的代码单独封装成了自定义函数。
def text_get(xpath):
input = browser.find_element_by_xpath(xpath)
text = input.text
# print(text)
return text
def write_text(text):
f = open('text1.txt','a')
f.write(text)
f.close()3. 再通过具体看页面,会发现有的评论下,会需要进行翻页操作,因此将思路调整为:先爬取整个页面的内容,对需要翻页的评论单独找出来,使用.click( )函数,模拟鼠标进行翻页操作
爬取文本内容的代码如下(只举了一个需要翻页的例子,其他还需要翻页的需要模拟for循环中的内容,修改“下一页”按钮的xpath代码)
from selenium import webdriver
import time
import re
browser = webdriver.Chrome()
url = "https://www.icourse163.org/learn/CUEB-1450000234?tid=1450406511#/learn/content?type=detail&id=1229081086"
browser.get(url)
browser.implicitly_wait(10)
xpath = "//*[@id="courseLearn-inner-box"]/div/div"
text = text_get(xpath)
write_text(text)
print("整体页面已爬完,开始进行翻页操作")
for i in range(3):
browser.find_element_by_xpath("/html/body/div[4]/div[2]/div[4]/div[2]/div/div[1]/div/div/div[3]/div[1]/div[2]/div/div/div[4]/div/div[1]/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[1]/div[2]/div/a[11]").click()
i = i+2
print("12号签到,第"+str(i)+"页,已爬取")
xpath = "//*[@id="courseLearn-inner-box"]/div/div/div[3]/div[1]/div[2]/div/div/div[4]/div/div[1]/div[1]/div[2]"
text = text_get(xpath)
write_text(text)
注意:
- 自定义函数中,f = open('text1.txt','a')第二个参数用a,表示写入内容是往后添加,而不覆盖文件中的原本内容。这是因为后面进行翻页操作过后,还需要再次调用write_text函数,往文件里写入内容
- 翻页从第2页开始爬取,评论中第1页的内容已经爬取过了,不要重复
- 为便于自己了解进度,输出爬取的内容有点太占页面了,因此使用print输出内容进行提示
4.将text文件中的内容读取出来,使用正则表达式进行匹配
with open("text1.txt", "r") as f:
content = f.read()
pattern = "++(.*)--(.*)==(.*)##(d+).*%%"
results = re.findall(pattern,content)
print(results)
- findall函数用于将文本内容(已读取到content变量中)与自己写好的正则表达式(pattern)进行匹配
5.将内容写入列表
for result in results:
oneNews = {}
oneNews['number'] = result[0]
oneNews['name'] = result[1]
oneNews['class'] = result[2]
oneNews['time'] = result[3]
print(oneNews)
6.将内容写入csv文件
with open('qiandao1.csv', 'w', newline='') as wf:
writer = csv.writer(wf)
for result in results:
writer.writerow(result)到这里爬取目的就完成了,附上完整源码(翻页只做了一个例子):
from selenium import webdriver
import time
import re
import csv
# 自定义函数:爬取网页对应元素位置的文本
def text_get(xpath):
input = browser.find_element_by_xpath(xpath)
text = input.text
# print(text)
return text
# 自定义函数:将爬取内容写入txt文件
def write_text(text):
f = open('text1.txt','a',errors='ignore')
f.write(text)
f.close()
browser = webdriver.Chrome()
url = "https://www.icourse163.org/learn/CUEB-1450000234?tid=1450406511#/learn/content?type=detail&id=1229081086"
browser.get(url)
browser.implicitly_wait(10)
xpath = "//*[@id="courseLearn-inner-box"]/div/div"
text = text_get(xpath)
write_text(text)
print("整体页面已爬完,开始进行翻页操作")
#对12号签到进行翻页操作,并爬取
for i in range(3):
browser.find_element_by_xpath("/html/body/div[4]/div[2]/div[4]/div[2]/div/div[1]/div/div/div[3]/div[1]/div[2]/div/div/div[4]/div/div[1]/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[1]/div[2]/div/a[11]").click()
i = i+2
print("12号签到,第"+str(i)+"页,已爬取")
xpath = "//*[@id="courseLearn-inner-box"]/div/div/div[3]/div[1]/div[2]/div/div/div[4]/div/div[1]/div[1]/div[2]"
text = text_get(xpath)
write_text(text)
# 还有其他日期签到需模仿此循环的操作,需获取对应xpath码(2处)进行替换
with open("text1.txt", "r") as f:
content = f.read()
pattern = "++(.*)--(.*)==(.*)##(d+).*%%"
results = re.findall(pattern,content)
print(results)
for result in results:
oneNews = {}
oneNews['number'] = result[0]
oneNews['name'] = result[1]
oneNews['class'] = result[2]
oneNews['time'] = result[3]
print(oneNews)
with open('qiandao1.csv', 'w', newline='') as wf:
writer = csv.writer(wf)
for result in results:
writer.writerow(result)(最终想说一句,自己编代码,运行了100多次,收获会很多很多,感觉还有很多细节需要自己去码才能感受到,大家加油!)
(此外,还觉得自己模拟浏览器慢慢翻页的方式有点本且麻烦,如果您有好的建议一定告诉我~~~感谢!!!!)














 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









