





这段时间,又有个应用隔几天就挂死,昨天直接一天死两次,我也是无语了。转过头来想,也说明使用系统的人越来越多了。为了客户,下定决心,必须解决这个顽疾。
拿出我之前备好的利器,开始收拾它。


- 提取故障日志
tomcat运行日志已经好几天没清理,一瞅好几个G。服务器上vi,半天打不开。不怕不怕,上日志查找神器。
这样就从大文件中提取到我们关心的内容了,我是提取了故障前后一段时间的日志。
du -sm catalina.out#显示出查找内容,以及所在行号grep -ano '20200407 17:18' catalina.out#100,200p 打印100,200行之间的内容sed -n 100,200p catalina.out > mylog- 碰上这种故障,首先怀疑是否又sql返回内容过多?
来,咱们看看,应为应用日志中又每条sql影响的行数,我们以此为突破口,从底向上查找一些蛛丝马迹。
用上另一款神器,不错,就是UE,拷贝到另外一个文件中,继续查找Total记录数巨大的行,果然发现有。
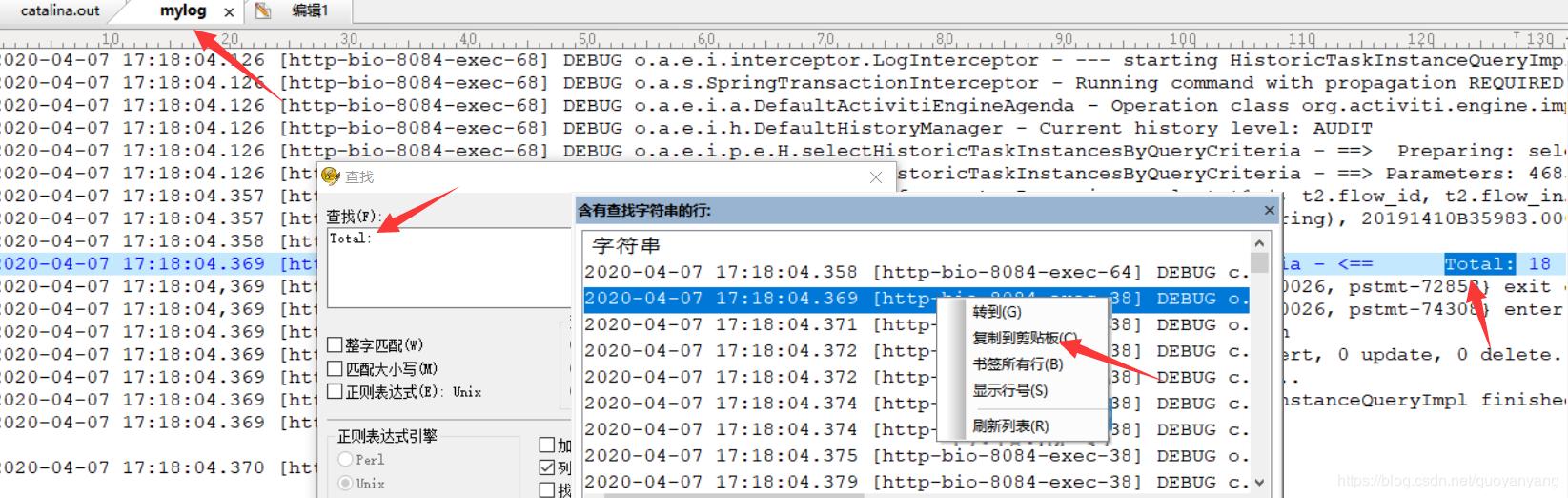


- 找到对应的sql了,然后根据业务规则, 要么加限制,要么改造sql
我们的应用只要加限制即可。
- 我们还留有应用异常时,几分钟内的stack信息,通过stack信息的记录,发现每次异常时一直都在运行的业务,可以查找相关代码是否又引起系统异常的隐患。如果系统还异常,可以用另一款神器arthas,可以通过watch某个方法的出入参,发现另一些端倪。
jstack -l 21864 >>stackinfo.log##等几分钟,再次执行jstack -l 21864 >>stackinfo.log
- 更新应用后,继续观察两天,没有发现系统再挂过,我们还需要继续观察......















 2754
2754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









