





羁绊前行的,不是肆虐的狂风,而是内心的迷茫。---王争。
最近有些偷懒,距离上次更新也有两个星期了,原因我也很清楚,就是又开始有些迷茫了,购买了不少课程,仍不能减轻内心的焦虑。焦虑的原因还是想得太多,做得太少,总想一口吃个胖子,而实际上,学习是有滞后性的,而且因人而异,因此学习时不应报着是否有用无用的功利心态,书到用时方恨少,学习重在积累,你学习到的知识可能短期内用不到,但说不定未来某天某个时机,或者眼界的提升都有助于未来的选择和发展,这样想,内心平静了许多。其实脚踏实地的去干就行了,空想无用,不如学也。
荀子说过:学不可以已。古人都有这样的认知,我们这种从事 IT 行业的,更应践行终身学习,否则,干不过那群小学生。
今天,接着分享最近学习到的算法相关的工程应用,代码仍用 Python 实现,Python 语言非常易读,你可以方便地转化为自己擅长的语言。今天要分享的是图这种数据结构和遍历算法。
王争老师说过,一定要带着问题去学习算法。这里先抛出一个问题:如何找出社交好友中的三度好友关系?
这里解释下:一个用户的一度好友,就是他的直接好友,二度好友就是他好友的好友,三度好友就是他好友的好友的好友,还记得著名的 6 度理论吗,也就是说你最多通过 6 个人认识你想认识的世界上任何一个人。在社交网络中,我们往往通过用户之间的连接关系,来实现推荐「可能认识的人」这么一个功能。给你一个用户,如何找出这个用户的所有三度(其中包含一度、二度和三度)好友关系?
如何存储社交网络中的好友关系呢?图这种数据结构就非常适合表达社交网络中的好友关系,图中的顶点代表一个人,边代表两个人之间是好友关系(无向图),有方向的边可以表达单向的好友关系,比如 A 是 B 的粉丝而 B 不是 A 的粉丝,边上的权重还可以表达两个人的亲密度。
以无向图为例,假如求一个顶点的一度好友,就是该顶点直接相连的顶点的集合,二度好友,就是其一度好友的一度好友,三度好友就是二度好友的一度好友,是不是有点递归的味道。这就跟图的遍历算法有关。
众所周知,图有两种最基本的遍历算法:广度优先遍历(BFS)和深度优先遍历(DFS)。广度优先就是一层一层的遍历,是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。而深度优先就是一条道走到黑,如果走不通再回退一下继续走,直到找到目标位置。
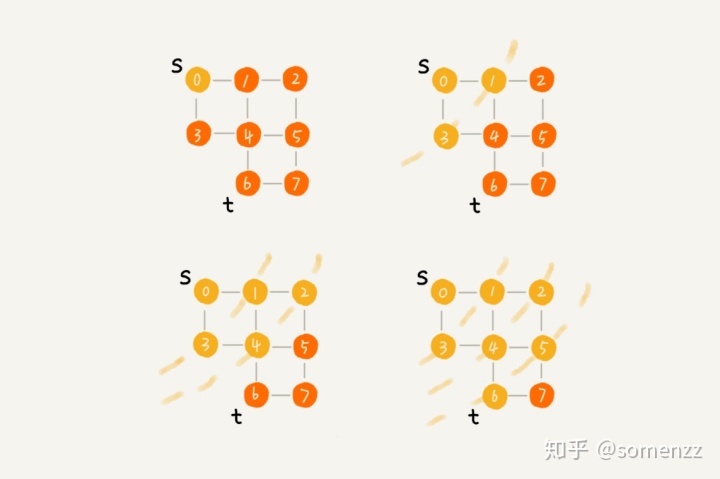
直观地感觉,广度优先算法可以满足查找三度好友关系,由于是一层一层地遍历,当遍历到第三层时,所有的一度二度三度好友都找到了。而且广度优先能找到最短路径,而深度优先则不一定。
下面我们来实现广度优先算法,并找出一个顶点的三度顶点。写代码前先思考下如何使用基础的数据结构比如数组、链表来存储一张图。数组和链表都是可以的,而且各有千秋。
一是使用二维数组来表达一张表,如下图所示:
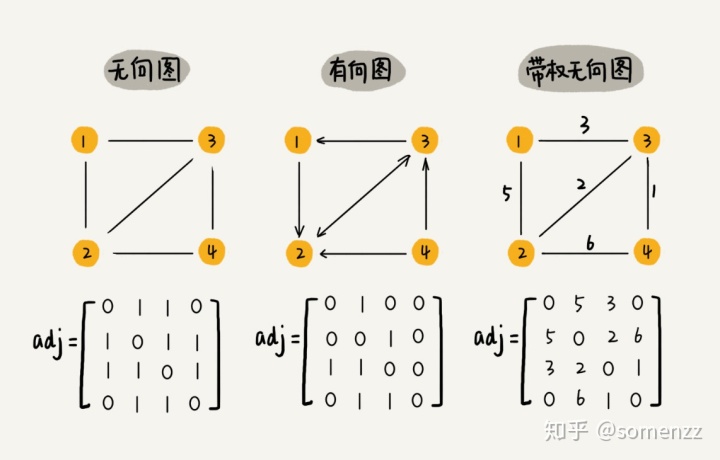
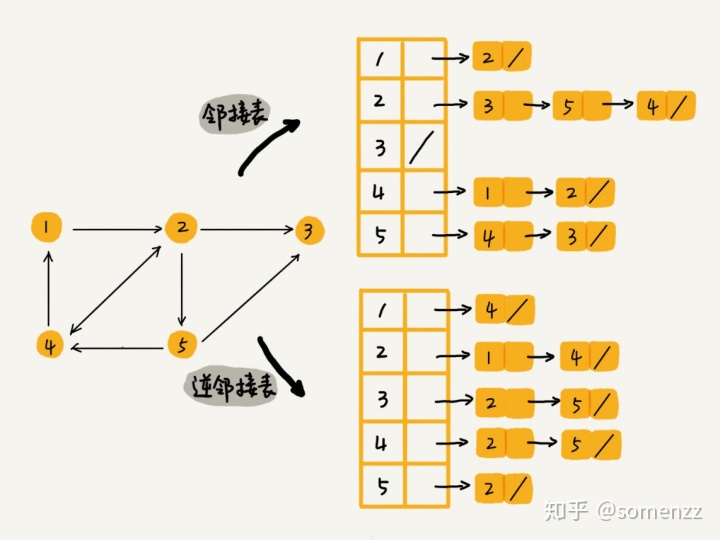
这也叫邻接矩阵,这处存储的好处是利用数组随机访问的特性,查找和插入的速度快,缺点就是浪费内存。而链表的方式正好相反,节省了内存,但降低了访问速度。
1、存储一个图
Python 是一种非常灵活的编程语言,我们可以使用 Python 中的字典来存储一个表,使用键来代表一个顶点,使用值来存储与该顶点相连的顶点。在实际的开发中,大家可能多使用 Python 的字典,它是一种 hash 表,查找的速度非常高效。
class 现在我们来验证一下使用字典存储的无向图:
if 运行结果如下
0 它际上长这样:
2、广度优先遍历
下面给出广度优先遍历的代码:
def bfs 函数是从 fromVertex 到 toVertex 广度优先遍历,_generate_path 用来打印出遍历的路径。
这段代码不是很好理解,里面有三个重要的辅助变量 visited、queue、prev。只要理解这三个变量,读懂这段代码估计就没什么问题了。
其中: visited 是一个集合,存放被访问过的顶点,防止顶点被重复访问。
queue 是一个队列,用来存储已经被访问、但相连的顶点还没有被访问的顶点。因为广度优先搜索是逐层访问的,也就是说,我们只有把第 k 层的顶点都访问完成之后,才能访问第 k+1 层的顶点。当我们访问到第 k 层的顶点的时候,我们需要把第 k 层的顶点记录下来,稍后才能通过第 k 层的顶点来找第 k+1 层的顶点。所以,我们用这个队列来实现记录的功能。
prev 是一个字典,存储从 fromVertex 到 toVertex 的遍历路径,需要注意的是 prev[a] = b 则代码从 b 走到 a,也就是 a 前面的顶点是 b ,它是反向存储的。因此使用 _generate_path 函数来生成这个路径。
执行结果如下:
>>>复杂度分析:
最坏情况下,终止顶点 toVertex 离起始顶点 fromVertex 很远,需要遍历完整个图才能找到。这个时候,每个顶点都要进出一遍队列,每个边也都会被访问一次,所以,广度优先搜索的时间复杂度是 O(V+E),其中,V 表示顶点的个数,E 表示边的个数。当然,对于一个连通图来说,也就是说一个图中的所有顶点都是连通的,E 肯定要大于等于 V-1,所以,广度优先搜索的时间复杂度也可以简写为 O(E)。
广度优先搜索的空间消耗主要在几个辅助变量 visited 、queue 、prev 上。这三个存储空间的大小都不会超过顶点的个数,所以空间复杂度是 O(V)。
3、查找三度好友
接下来考虑查找一个节点的三度好友。首先,遍历与起始顶点最近的一层顶点,也就是用户的一度好友,然后再遍历与用户距离的边数为 2 的顶点,也就是二度好友关系,以及与用户距离的边数为 3 的顶点,也就是三度好友关系。 我们只需要稍加改造一下广度优先搜索代码,用一个数组来记录每个顶点与起始顶点的距离,非常容易就可以找出三度好友关系。
def 这里计算了被访问的顶点距 fromVertex 的距离,并将它存储在字典中,运行结果如下:
>>>4、图的深度优先遍历
只需要将广度优先遍历中队列改为栈,就变成了深度优先遍历算法,请自行思考为什么。
def 运行结果如下:
>>>复杂度分析
这里仅仅是把队列变成了栈,因此时间复杂度和空间复杂度和广度优先遍历算法是一样的。
专栏有个留言总结得很好,我也放在这里:
学了这么久的数据结构和算法,今天突然顿悟,基础的数据结构就是数组和链表, 而后面更加复杂的树、队列、图等等,都可以通过数组和链表等方式存储, 出现树、队列、图等数据结构的原因就是为了解决部分问题处理过程中时间复杂度过高的问题, 所以数据结构就是为了算法而生的! 尤其是学习了时间复杂度过后 ,在工作和学习过程中就应该分析自己的代码复杂度,以进行优化或者选择更好的数据结构和算法!这样才能写出更好的代码更好的解决问题。
(完)
欢迎关注我的个人微信公众号somenzz,及时获取订阅消息。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









