





- 线性回归用于拟合数据,寻找数据的规律,只适用于预测类型的回归问题,由于其算法简单,通常作为项目的BaseLine,损失函数通常使用最小二乘法,最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。用函数表示为:
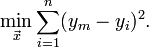
使误差(所谓误差,当然是观察值与实际真实值的差量)平方和达到最小以寻求估计值的方法,就叫做最小二乘法,用最小二乘法得到的估计,叫做最小二乘估计。
- 线性回归容易过拟合,为了防止过拟合,可以使用L2正则化,即在损失函数后面增加惩罚项,用于限制模型变得太过复杂。
- L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数 - L1范数可以使权值稀疏,方便特征提取。 L2范数可以防止过拟合,提升模型的泛化能力。
- L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?
看导数一个是1一个是w便知, 在靠近0附近, L1以匀速下降到零, 而L2则完全停下来了. 这说 明L1是将不重要的特征(或者说, 重要性不在一个数量级上)尽快剔除, L2则是把特征贡献尽量压缩最小但不至于为零. 两者一起作用, 就是把重要性在一个数量级(重要性最高的)的那些特征一起平等共事(简言之, 不养闲人也不要超人)。
- 逻辑回归是用于分类问题!用于分类问题!用于分类问题!本质上是在线性回归的表达式外面套了一个sigmod函数。Logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特征的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
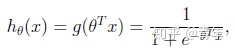
逻辑回归看似简单,在工业界却使用颇多,因为模型简单,分类效果还好。虽然现在深度学习盛行,但在一些传统行业,比如金融领域,使用逻辑回归的还是偏多。
通过Logistic Regression预测Titanic乘客是否能在事故中生还
1.导入工具库和数据
import numpy as np
import pandas as pd
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
import seaborn as sns
sns.set(style="white") # 设置背景色为白色
sns.set(style="whitegrid", color_codes=True)
df = pd.read_csv("./titanic_data.txt")
df.head()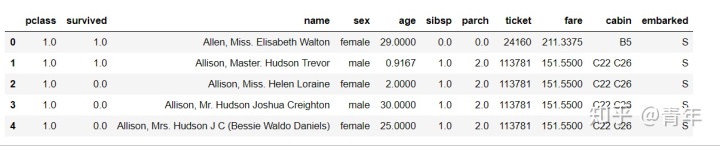
特征含义解释:
pclass: 1,2,3分别代表仓位等级;
sibsp: 兄妹妻子等的个数;
parch: 老人孩子的个数;
fare: 票价;
cabin:仓位分布编号;
embarked: 上船港口。
print("数据集包含的数据个数{}.".format(df.shape[0]))out: 数据集包含的数据个数1310.
2.查看缺失数据
# 查看数据集中各个特征缺失的情况
df.isnull().sum()
2.1 年龄
print('"age"缺失的百分比 %.2f%%' % ((df['age'].isnull().sum() / df.shape[0]) * 100))out: "age"缺失的百分比 20.15%
可以看出,年龄有20%左右缺失,接下来查看年龄分布情况
ax = df['age'].hist(bins=15, color='teal', alpha=0.6)
ax.set(xlabel='age')
plt.xlim(-10, 85)
plt.show()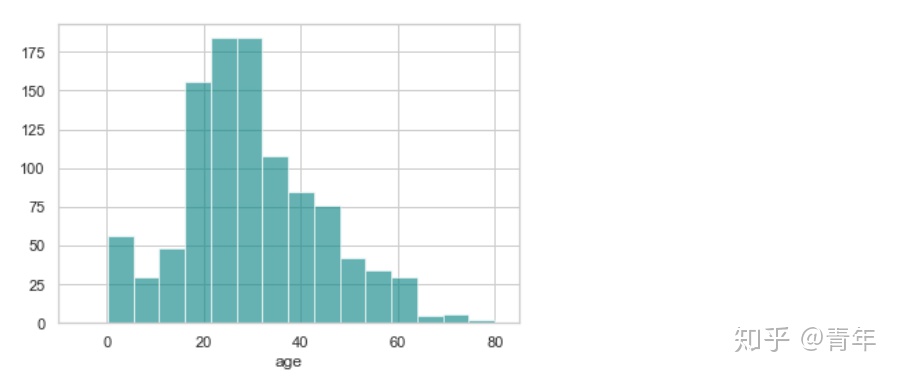
由于“age”的偏度不为0,使用均值代替缺失值不是最佳选择,这里可以选择使用中间值代替缺失值。
# 年龄的均值
print('The mean of "Age" is %.2f' % (df['age'].mean(skipna=True)))
# 年龄的中间值
print('The median of "Age" is %.2f' % (df['age'].median(skipna=True)))out: The mean of "Age" is 29.88
The median of "Age" is 28.00
2.2 仓位
# 仓位缺失百分比
print('"Cabin"缺失的百分比 %.2f%%'%((df['cabin'].isnull().sum()/df.shape[0]) * 100))out: "Cabin"缺失的百分比 77.48%
约77%的乘客的仓位都是缺失的,最佳的选择是不使用这个特征
2.3 登船地点
# 登船地点的缺失率
print('"Embarked"缺失的百分比 %.2f%%'%((df['embarked'].isnull().sum()/df.shape[0]) * 100))out: "Embarked"缺失的百分比 0.23%
只有0.23%的乘客的登船地点数据缺失,可以使用众数替代缺失的值
print('按照登船地点分组(C = Cherbourg, Q = Queuetown, S = Southampton):')
print(df['embarked'].value_counts())
sns.countplot(x='embarked', data=df, palette='Set2')
plt.show()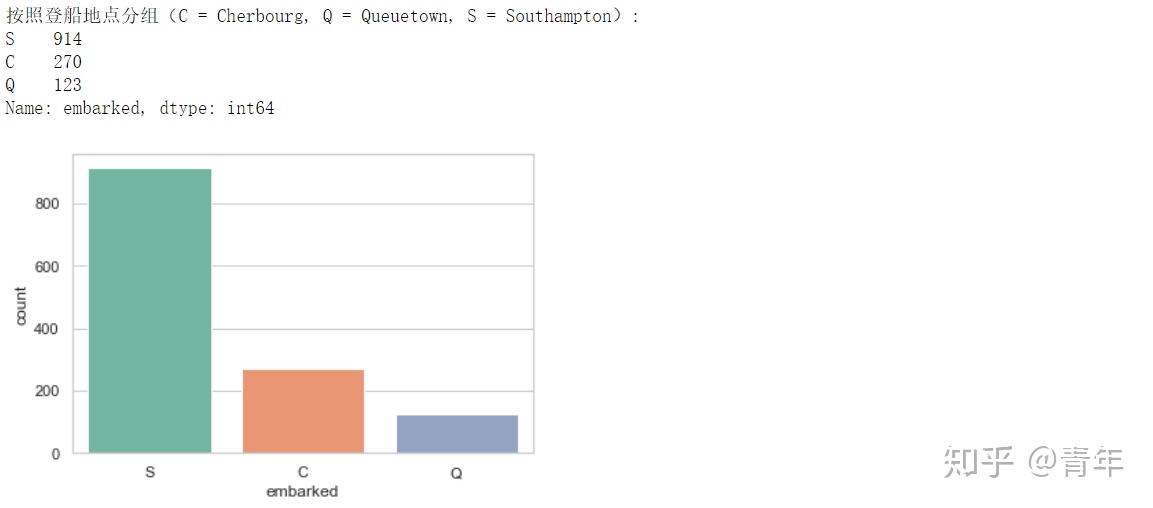
print('乘客登船地点的众数为 %s.' %df['embarked'].value_counts().idxmax())out: 乘客登船地点的众数为 S.
由于大多数人是在南安普顿(southhampton)登船,可以使用“S”替代缺失的数据值。
2.4 根据缺失数据情况调整数据
基于以上分析,我们可以进行如下调整: ·如果一条数据的“Age”缺失,使用年龄的中位数28替代 ·如果一条数据的“Embarked”缺失,使用登船地点的众数“S”替代 ·如果太多数乘客的“Cabin”数据缺失,从所有数据中丢弃这个特征值。
data = df.copy()
data['age'].fillna(df['age'].median(skipna=True), inplace=True)
data['embarked'].fillna(df['embarked'].value_counts().idxmax(), inplace=True)
data.drop('cabin',axis=1, inplace=True)
# 确认数据是否还包含缺失数据
data.isnull().sum()
按照以上处理的方式,处理仍然存在缺失数据的情况
TODO:
# 姓名和船票编号应该对结果没有影响,这两个特征直接删除
data = data.drop(["name","ticket"], axis=1)
#survived为标签,缺失的话,直接删除该样本
data = data.dropna(subset=['survived'], axis=0)
# pclass仓位等级缺失,使用众数代替
data['pclass'].fillna(df['pclass'].value_counts().idxmax(), inplace=True)
# sex性别缺失,使用众数代替
data['sex'].fillna(df['sex'].value_counts().idxmax(), inplace=True)
# sibsp缺失,使用众数代替
data['sibsp'].fillna(df['sibsp'].value_counts().idxmax(), inplace=True)
# parch缺失,使用众数代替
data['parch'].fillna(df['parch'].value_counts().idxmax(), inplace=True)
# fare缺失,使用众数代替
data['fare'].fillna(df['fare'].value_counts().idxmax(), inplace=True)
data.isnull().sum()
查看年龄在调整前后的分布
plt.figure(figsize=(15,8))
ax = df['age'].hist(bins=15, density=True, stacked=True, color='teal', alpha=0.6)
df["age"].plot(kind='density', color='teal')
ax=data['age'].hist(bins=15, density=True, stacked=True, color='orange', alpha=0.5)
data["age"].plot(kind='density', color='orange')
ax.legend(['Raw Age', 'Adjusted Age'])
ax.set(xlabel="Age")
plt.xlim(-10, 85)
plt.show()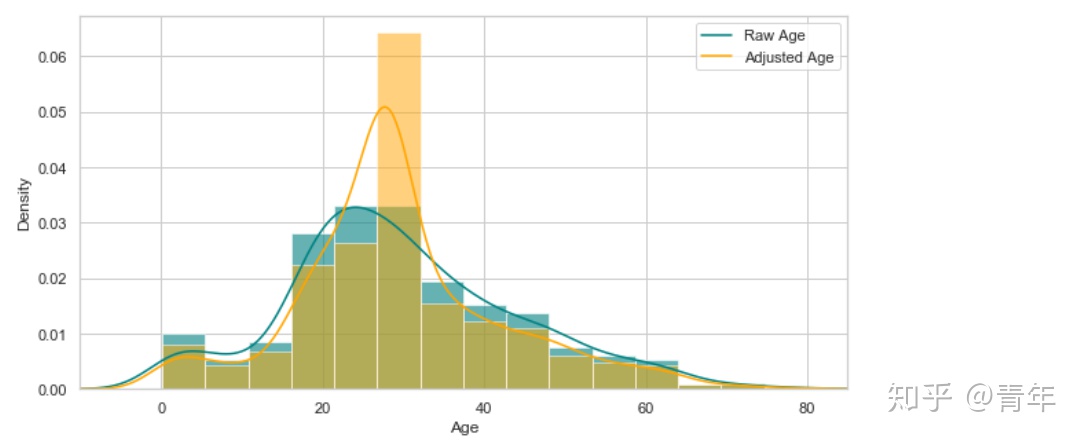
2.4.1 其它特征的处理
数据中的两个特征 “sibsp” (一同登船的兄弟姐妹或者配偶数量)与“parch”(一同登船的父母或子女数量)都是代表是否有同伴同行. 为了预防这两个逼啊了可能的多重共线性, 我们可以将这两个变量转为一个变量 “TravelAlone” (是否独自一人成行)
# 创建一个新的变量‘TravelAlone’记录是否独自旅行,
data['TravelAlone'] = np.where((data["sibsp"] + data["parch"]) > 0, 0, 1)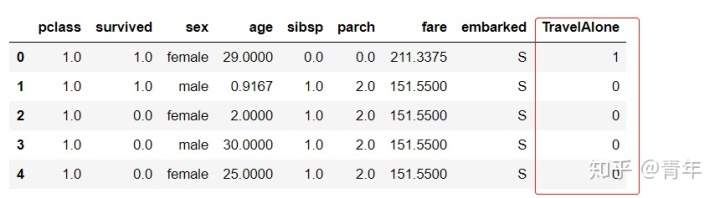
# 删除sibsp和parch两个特征
data.drop('sibsp', axis=1, inplace=True)
data.drop('parch', axis=1, inplace=True)
data.head()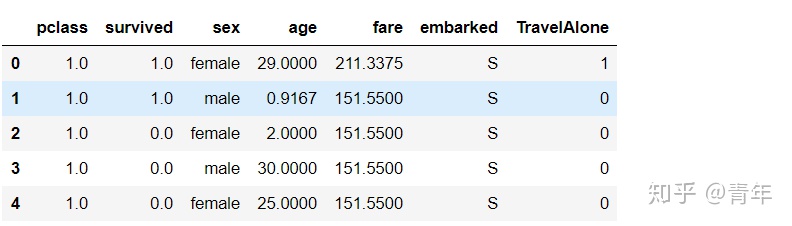
对类别变量(categorical variables)使用独热编码(One-Hot Encoding),将字符串类别转换为数值。
# 对Embarked, Sex 进行独热编码
final = pd.get_dummies(data, columns=["embarked", "sex"]) # 类别类型向量化
final.head()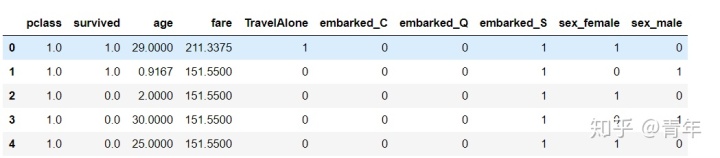
数据分析
3.1 年龄
plt.figure(figsize=(10,5))
ax = sns.kdeplot(final["age"][final.survived == 1], color="darkturquoise", shade=True)
sns.kdeplot(final["age"][final.survived == 0], color="lightcoral", shade=True)
plt.legend(['Survived', 'Died'])
plt.title('Density Plot of Age for Surviving Population and Deceased Population')
ax.set(xlabel='Age')
plt.xlim(-10,85)
plt.show()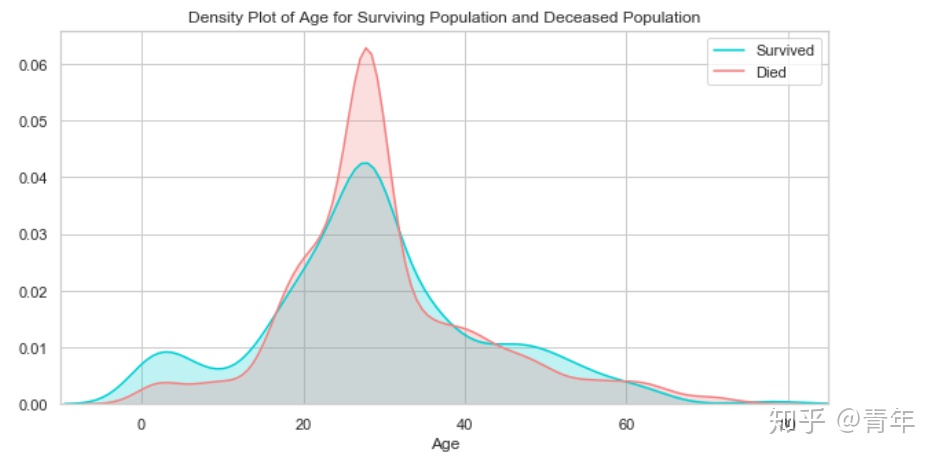
生还和遇难群体的分布相似,唯一的最大区别是生还群体中有一部分年龄小的乘客,说明当时的人预先保留了孩子的生还机会。
3.2 票价
plt.figure(figsize=(10, 5))
ax = sns.kdeplot(final["fare"][final.survived == 1], color="darkturquoise", shade=True)
sns.kdeplot(final["fare"][final.survived == 0], color="lightcoral", shade=True)
plt.legend(["Survived", "Died"])
plt.title("Density Plot of Fare for Surviving Population and Deceased Population")
ax.set(xlabel="Fare")
plt.xlim(-20, 200)
plt.show()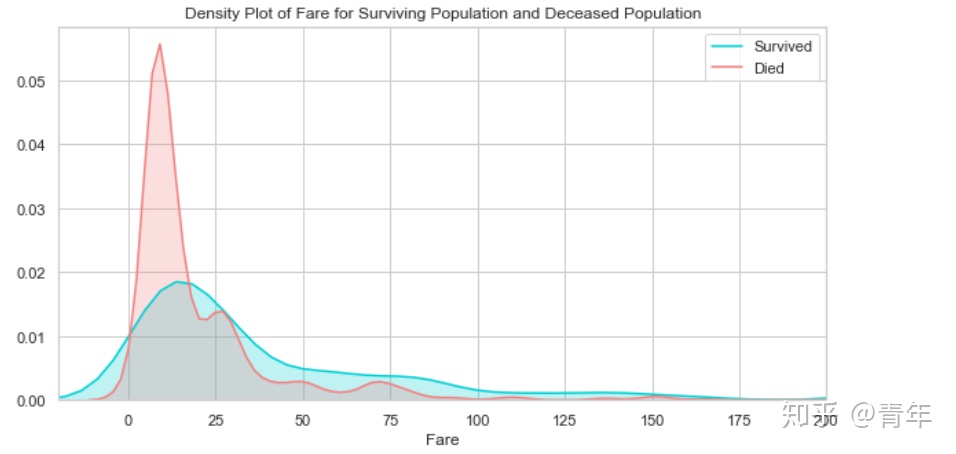
生还和遇难群体的票价分布差异比较大,说明这个特征对预测乘客是否生还还是非常重要,票价和仓位相关,也许是仓位影响了逃生的效果。接下来看仓位的分析。
3.3仓位
sns.barplot('pclass', 'survived', data=df, color="darkturquoise")
plt.show()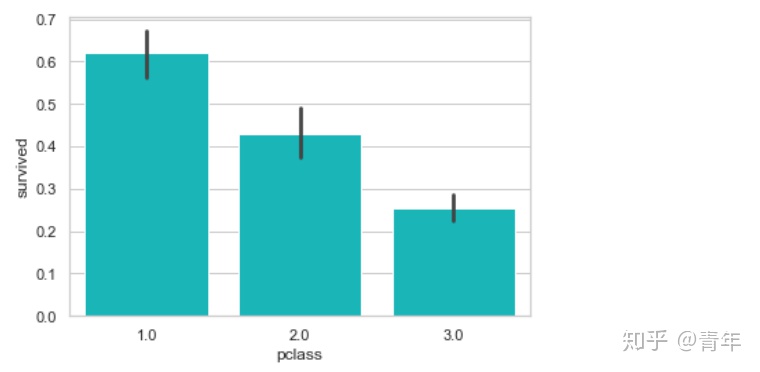
由图看以看出,一等舱的乘客生还几率最高。
3.4 登船地点
sns.barplot('embarked','survived', data=df, color="teal")
plt.show()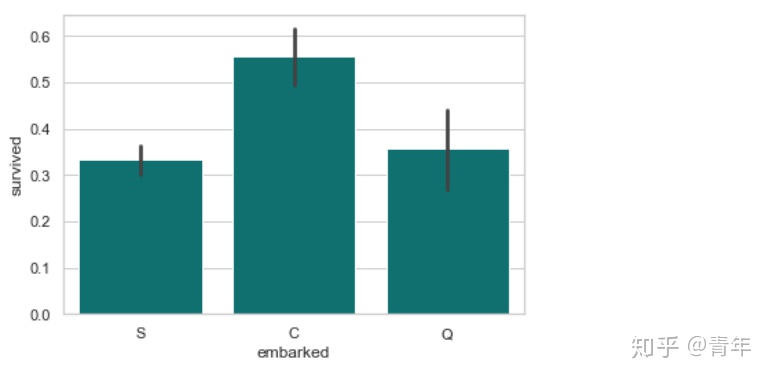
由图可以看出,从法国Cherbourge登录的乘客生还率最高。
3.5 是否独自旅行
sns.barplot('TravelAlone', 'survived', data=final, color="mediumturquoise")
plt.show()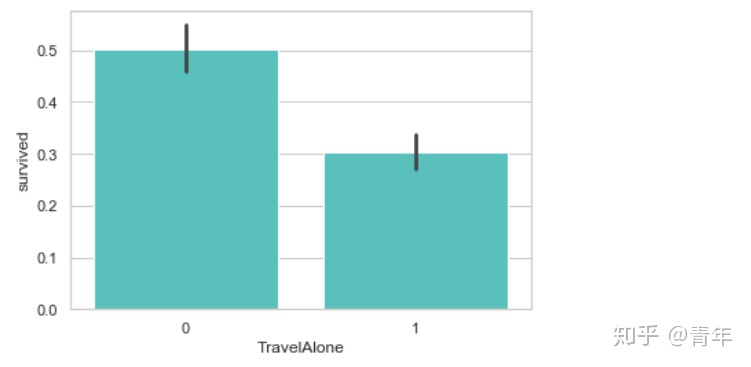
由上图可以看出,独自旅行的乘客生还率较低,当时的年代,独自旅行的乘客多为男性。
3.6 性别
sns.barplot('sex', 'survived', data=df, color="aquamarine")
plt.show()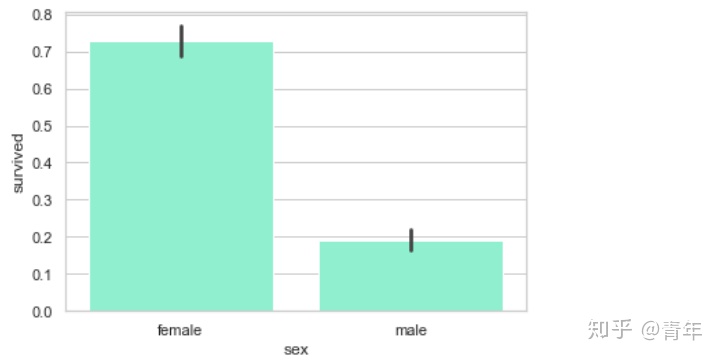
很明显,女性的生还率高。
4.使用Logistic Regression做预测
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 使用如下特征做预测
cols = ["age", "fare", "TravelAlone", "pclass", "embarked_C", "embarked_S", "sex_male"]
# 创建X(特征)和y(类别标签)
X = final[cols]
y = final['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2)TODO:训练模型, 根据模型,输出准确率
lr = LogisticRegression(solver='liblinear')
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
print("准确率为%2.3f" % accuracy_score(y_test, y_pred))out: 准确率为0.836
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









