






scrapy组件
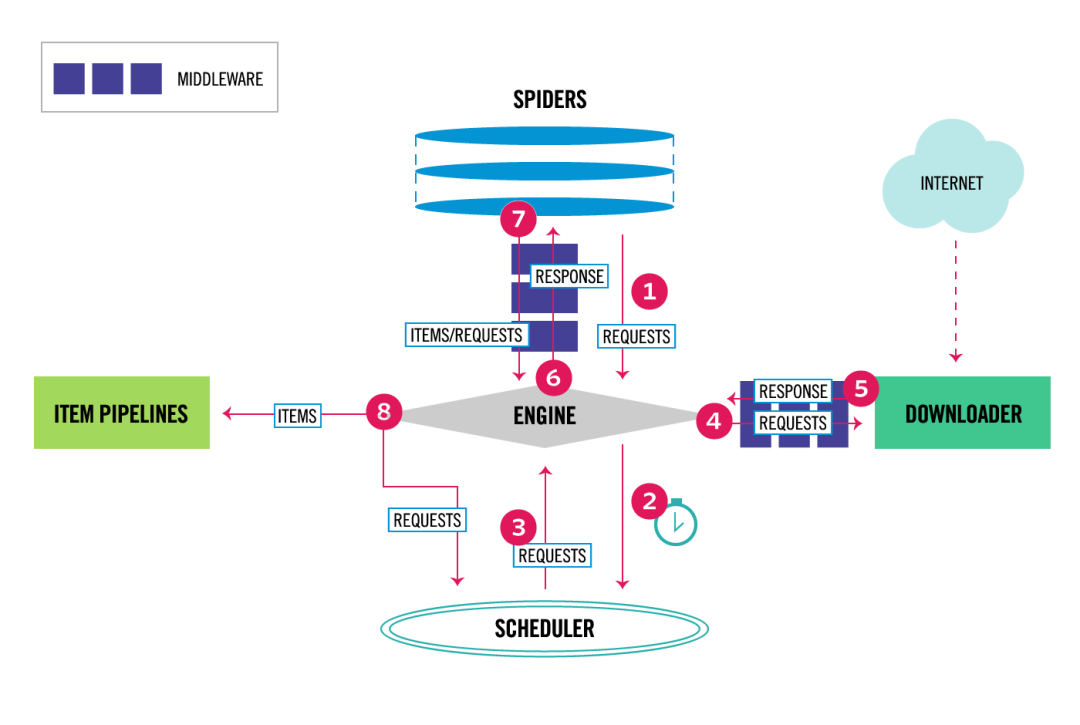
首先我们看下scrapy官网提供的新结构图,乍一看这画的是啥啊,这需要你慢慢的理解其原理就很容易看懂了,这些都是一个通用爬虫框架该具有的一些基本组件。上一篇博客说了项目管道(也就是图中的ITEM PIPELINES),可以看到中间的引擎(ENGINE)将item传递给了项目管道,也就是让项目管道来处理抓取到的内容。另外图中的所谓的组件只是抽象出来的东西比较容易让人理解,其实这些都是python的类实例化的东西。
下载中间件处于引擎和下载器的中间,就像是引擎和下载器有一根管道,管道上面有两个路障就是下载中间件了,而引擎和下载器之间只传递请求(REQUESTS)和响应(RESPONSE),所以这两个路障很明显的作用就是拦截请求和响应(至于拦截之后想干嘛就随便了,比如更改请求或响应内容,更改请求头或响应头,或者什么都不干,记录一下就放过去)。
蜘蛛中间件处于蜘蛛和引擎之间,这里说的蜘蛛就是我们在spider目录下编写的蜘蛛类,已经写过蜘蛛的应该知道,在蜘蛛中一般会处理响应(默认解析是parse方法),返回item,或者返回(准确点应该是迭代)请求(scrapy.Request)。而在图中也很明显,蜘蛛和引擎之间会传递请求(REQUESTS)、响应(RESPONSE)和items。响应是由下载器从网站上下载得到的,在传递给引擎后给蜘蛛来处理,而items一般是由蜘蛛从响应内容中解析出来传递给引擎在给项目管道处理,而请求一般是由蜘蛛中的start_urls中定义的URL和蜘蛛解析出的新的URL准备传递给引擎在交由调度器统一管理。
上面的一堆屁话说的:中间件的作用就是拦截两个组件传递的内容。
看了这些组件的功能和使用你会发现为什么要这么麻烦,你看我用requests库只需要请求一下得到响应直接处理就行了,这引擎和调度器感觉没什么存在的意义啊。这就需要慢慢理解了,或者自己写一个简单通用爬虫框架可能就知道了。
中间件的编写
中间件的启用
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'newspider.middlewares.UAMiddleware': 500 #newspider为scrapy项目名称,也就是settings.py中BOT_NAME的值,UAMiddleware为定义的中间件的名字
}
字典的值如何选择,500这个值改成其他的行不行呢?先看一下官方是怎么说的:
scrapy会将DOWNLOADER_MIDDLEWARES设置与DOWNLOADER_MIDDLEWARES_BASE设置合并,然后按值的顺序排序以获取启用的中间件的最终排序列表:值最小的中间件离引擎更近,最大的中间件离下载器更近。换句话说,每个中间件的process_request() 方法将以递增的顺序被调用,而每个中间件的process_response()方法将以递减的顺序调用。
要决定分配给中间件的顺序,请查看 DOWNLOADER_MIDDLEWARES_BASE设置并根据您要插入中间件的位置选择一个值。顺序很重要,因为每个中间件执行不同的操作,并且您的中间件可能取决于所应用的某些先前(或后续)中间件。
如果要禁用内置中间件(DOWNLOADER_MIDDLEWARES_BASE默认情况下在定义和启用的中间件 ),则必须在项目的DOWNLOADER_MIDDLEWARES设置为None。
上面的一些话中有一句很重要:每个中间件的process_request() 方法将以递增的顺序被调用,而每个中间件的process_response()方法将以递减的顺序调用。这应该就很清楚值怎么选吧,不过一般中间件并没有确定的顺序,只要不产生矛盾就行了。
举个例子吧:你已经写了一个中间件newspider.middlewares.UAMiddleware,但是你在启用的时候没有禁止内置的UserAgentMiddleware,怎么才能使你的中间件生效呢?代码如下:
DOWNLOADER_MIDDLEWARES = {
#'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'newspider.middlewares.UAMiddleware': 501 #newspider为scrapy项目名称,也就是settings.py中BOT_NAME的值,UAMiddleware为定义的中间件的名字
}
因为默认的UserAgentMiddleware值为500,因为修改请求头是在process_request,而process_request是以递增的形式被调用,所以会先调用内置UserAgentMiddleware,在调用你定义的UAMiddleware,则内置的会被覆盖。不过因为很多人修改请求头都是以字典访问的形式修改(request.headers["User-Agent"] = ""),这样的话即使你设置值为499,结果还是你设定的User-Agent,而不是默认内置的。
其实看一下内置的代码就可以理解了:源代码 代码使用的是request.headers.setdefault(b'User-Agent', self.user_agent),setdefault是当不存在键时设置,存在则不设置。
内置下载中间件
DOWNLOADER_MIDDLEWARES_BASE = {
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
下载中间件的编写
process_request(request,spider): 所有请求都会调用此方法
process_response(request, response, spider):这里的参数比上面的多了response,肯定是用来处理response的
process_exception(request, exception, spider):处理异常
from_crawler(cls, crawler):从settings.py获取配置
假设我们需要一个自动管理cookie的中间件,应该怎么编写?首先管理cookie一般就是将服务器返回的Set-cookie更新一下已保存的cookie。伪代码如下:
from scrapy.exceptions import NotConfigured
class CookieMiddleware(object):
def __init__(self):
# 实际上cookies并不能使用字典来保存,因为cookies是可以包含相同的键的
# 这里只做简单的演示,正常可以使用scrapy.http.cookies.CookieJar
self.cookies = {}
def process_request(request, spider):
self.addcookies(request, self.cookies)
def process_response(request, response, spider):
newcookie = response.headers.getlist('Set-Cookie')
self.updatecookies(self.cookies, newcookie)
return response
def process_exception(request, exception, spider):
pass
def addcookies(self, request, cookies):
'''
给请求加cookie
'''
pass
def updatecookie(self, cookies, cookie):
'''
更新cookie字典(对象)
'''
pass
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.get('是否开启cookie'):
#这个方法在__init__之前,抛出异常的话,类中的所有方法就都不执行了
raise NotConfigured
其实scrapy已经内置了cookies管理的中间件,可以参考一下源代码:https://docs.scrapy.org/en/latest/_modules/scrapy/downloadermiddlewares/cookies.html#CookiesMiddleware
想要一个随机User-Agent的中间件也很简单,只需要在process_request方法中改变请求头就行了。其实process_request和process_response这两个方法是有返回值的,在上面的例子中只是对请求头和响应头做了修改,所以没有涉及到返回值。如果我们需要对请求和响应整个做更改的话就需要重新构造请求和响应。这里最典型的例子就是selenium中间件了。
spider示例代码:
import scrapy
from selenium import webdriver
class SeleniumSpider(scrapy.Spider):
name = 'seleniumspider'
start_urls = ['https://example.com']
# 实例化浏览器对象, 因为浏览器对象只需要实例化一次, 所以不在中间件中进行实例化
bro = webdriver.Chrome(executable_path=r'E:\spiderman\day13\wynews\wynews\wynews\chromedriver.exe')
def parse(self, response):
'''
和正常一样,该怎么解析怎么解析
'''
pass
selenium中间件示例代码(只是简单演示,为了更好理解中间件怎么写):
from selenium.common.exceptions import TimeoutException
from scrapy.http import HtmlResponse
class SeleniumMiddleware(object):
def __init__(self, timeout=None, options=None):
pass
def process_reqeust(self, request, spider):
try:
url = request.url
spider.bro.get(url)
return HtmlResponse(url=url, body=spider.bro.page_source, request=request,encoding='utf-8',status=200)
except TimeoutException:
return HtmlResponse(url=url, status=500, request=request)
@classmethod
def from_crawler(cls, crawler):
pass
在代码中HtmlResponse类就是我们新构建的响应,这样前面的spider处理的response就是这个响应了。这里有个疑问?为什么要在process_reqeust这个方法中返回响应,就不能在process_response中吗?其实也可以,区别在于process_reqeust返回的话,会忽略其他中间件中的process_reqeust和process_exception方法,只执行其他中间件的process_response方法。试想一下如果你还有一个cookie管理的中间件,process_reqeust的操作是不是就和SeleniumMiddleware中的矛盾了,所以我们要在process_reqeust返回response来使其他中间件的process_reqeust方法失效。
返回值
process_reqeust方法返回值
None:如果返回None,则一切正常传递
request对象:如果返回request对象,scrapy会停止调用接下来的中间件而重新处理request对象(也就是交由引擎重新管理)
response对象:...,Scrapy不再调用其他中间件的process_request()或process_exception()方法,它将直接调用其他中间件的process_response方法
IgnoreRequest异常:依次调用所有中间件的process_exception方法
process_response方法返回值(注意这个方法必须返回一个对象,不能是None)
response对象:传递给下一个中间件的process_response方法
request对象:scrapy会停止调用接下来的中间件而重新处理request对象(也就是交由引擎重新管理)
IgnoreRequest异常:依次调用所有中间件的process_exception方法
process_exception方法返回值
None:继续传递
request对象:scrapy会停止调用接下来的中间件的process_exception方法而重新处理request对象(也就是交由引擎重新管理)
response对象:停止传递接下来的中间件中的process_exception,而开始调用所有process_response方法
蜘蛛中间件
process_spider_input(response, spider):所有请求都会调用这个方法
process_spider_output(response, result, spider):spider解析完response之后调用该方法,result就是解析的结果(是一个可迭代对象),其中可能是items也可能是request对象
process_spider_exception(response, exception, spider):处理异常
process_start_requests(start_requests, spider):同process_spider_output,不过只处理spider中start_requests方法返回的结果
from_crawler(cls, crawler):...
同样是拦截请求和响应,那么和下载中间件有什么区别呢?因为下载中间件是连通引擎和下载器的,所以如果修改请求只会影响下载器返回的结果。如果修改响应,会影响蜘蛛处理。而蜘蛛中间件是连通引擎和蜘蛛的,如果修改请求则会影响整个scrapy的请求,因为scrapy的所有请求都来自于蜘蛛,当然包括调度器和下载器。如果修改响应,则只会影响蜘蛛的解析,因为响应是由引擎传递给蜘蛛的。
上面说的有点乱,整理一下这两个的功能:蜘蛛中间件:记录深度、丢弃非200状态码响应、丢弃非指定域名请求等 下载中间件:修改请求头、修改响应、管理cookies、丢弃非200状态码响应、丢弃非指定域名请求等
丢弃非指定域名请求一般使用蜘蛛中间件,如果使用下载中间件会导致引擎和调度器的无效任务变多,丢弃非200状态码响应我感觉应该用下载中间件,但是scrapy内置的使用的是蜘蛛中间件,可能是我理解不够透彻吧。
scrapy已经提供了很多内置的中间件,只需要启用即可。另外,蜘蛛中间件一般用于操作蜘蛛返回的request,而下载中间件用于操作向互联网发起请求的request和返回的response。更多的示例可以看一些内置中间件的源码,蜘蛛中间件一般不需要自己编写,使用内置的几个也足够了














 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









