






目录
- 序言
- 理论基础
- 生态介绍
- 安装和配置
- 多节点部署
- 交互
- Spark
- HBase
目标
前一篇里我们已经有了一台部署完成hadoop的服务器,但只有一台机器,而现实中通常都是分布式的部署,要不然其实也没有太大使用hadoop的意义。
这一篇我们在前面“单机”的基础之上扩展成为分布式的部署方式,使我们的环境成为名副其实的分布式大数据环境。
互通
要部署分布式hadoop系统,需要首先让各服务器之间可以通讯,需要做到:
- 服务器各自有确定的IP
- 服务器各自有确定的名字
- 每个服务器知道所有其他服务器的名字和对应的IP
- 服务器之间通过SSH可以免密码访问
对于最后两条,最低限度是要让NameNode知道所有其他的服务器相关信息,并且可以免密码访问所有其他服务器,因为通常我们会在这上面直接启动或停止整个集群,它需要可以控制其他节点。但如果没有特别的原因,最好可以做到所有的服务器相互之间都可以访问。
下面我们一项项来简单说明:
- 服务器各自有确定的IP,这个需要在网络配置。如果是本地网络或VM可以做IP绑定或用静态IP,但VM需要注意所有的机器的MAC地址应该刷新成不一样的。如果是云服务器,通常是有固定IP的。
- 服务器各自有确定的名字,需要修改/etc/hostname文件。
- 每个服务器知道所有其他服务器的名字和IP,这个需要修改/etc/hosts文件。
- 服务器之间通过SSH互相访问。需要做两个步骤:
1). 通过ssh-keygen生成key。但注意是一路回车。具体方法请自行搜索。
2). 通过ssh-copy-id将一台服务器的公钥拷贝到其他需要访问它的服务器上去。具体方法请自行搜索。
在我的环境中:
- 我有四台机器(VM),IP分别是192.168.2.201-204,名字分别是bd1.sos、bd2.sos、bd3.sos、bd4.sos。其中bd1是做NameNode的“主”服务器。
- 所有四台服务器上的hosts文件都配置了完整的四台机器的IP和名字。如图:

我们可以通过在每台机器上运行如下命令检查服务器之间是不是通的,比如在第一台机器上试着访问第二台机器:
ssh bd2如果不需要密码就可以进去,那么说明成功了。

配置Hadoop
在我的环境中每台服务器中数据保存的路径都是一样的,所以多数配置文件都一样。而我的第二、三、四台服务器是直接从配置好的第一台服务器拷贝出来的,所以已经有了完全相同的hadoop目录以及配置。我只需要做相应调整。
如果你的环境不是VM,只需要把hadoop目录拷贝到新的机器中,并配置好上面说过的hosts、hostname、IP、MAC地址和SSH等即可。
添加更多机器后,需要修改的主要有以下几个地方(所有的服务器都做修改):
- hdfs-site.xml,主要是设置dfs.replicaton和dfs.datanode.hostname,分别对应于一个文件在hdfs中分布式地保存在几个DataNode中,这个设置的值不能超过DataNode节点的个数,和每个DataNode自己的名字。如下是我第一台机器上的配置:

- yarn-site.xml,主要是添加yarn.resource.manager.hostname,使得所有的nodemanager都知道resourcemanager在哪:
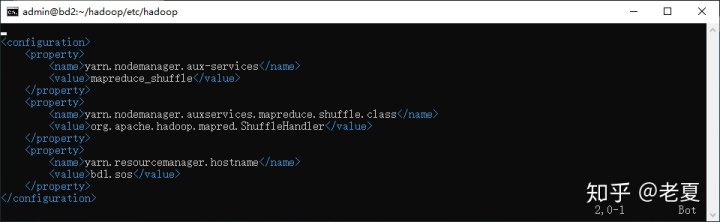
- workers文件。这个文件主要用来在NameNode中使hadoop知道我们总共有几个workers,也就是DataNode,需要把所有DataNode的名字放进去。而这个文件默认可能没有,需要手动创建。而且在Hadoop 2.x中应该叫slaves,请注意区分。修改后的workers如下(注意,这里我的NameNode也是一个DataNode,现实中可以不是):

- HADOOP_PID_DIR目录。这个是在Hadoop-env.sh文件中,用来保存hadoop相关进程和pid,方便一些命令的运行,比如在NameNode中停止整个集群,它会试着命令所有节点的服务都停止,但如果因为某些原因其他节点的服务不能正常停止,它就可以通过这个pid去强行kill掉远程的服务进程。

启动和停止
配置完之后,我们可以试着启动整个集群。通过在NameNode上运行如下命令:
~/hadoop/sbin/start-all.sh这和单机下的启动是一样的,但是现在因为hadoop知道自己是分布式的部署,也知道了其他服务器是谁,并且了访问权限,所以它会自动帮我们把所有节点的服务都启动起来。
结果如下图:

如果要停止整个集群,可以在NameNode上使用如下命令:
~/hadoop/sbin/stop-all.sh结果如下图:

如果要单独启动或停止某一个DataNode,可以在其上运行如下两条命令(因为到目前,我们的每个DataNode只需要运行两个服务,一个是DataNode一个是NodeManager):
hdfs --daemon start datanode
yarn --daemon start nodemanager
hdfs --daemon stop datanode
yarn --daemon stop nodemanager结果如下图(包括了启动和停止):

检查结果
配置完成hadoop集群后我们需要知道,整个部署是不是成功,可以通过两种方式。
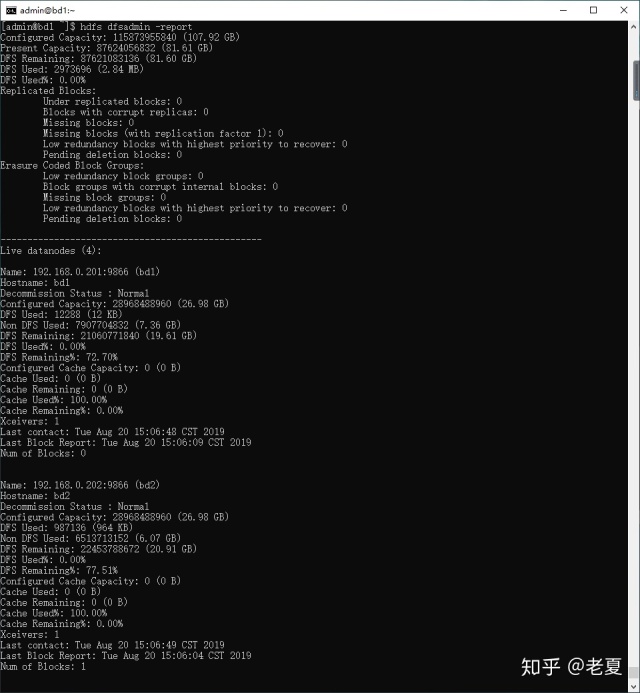
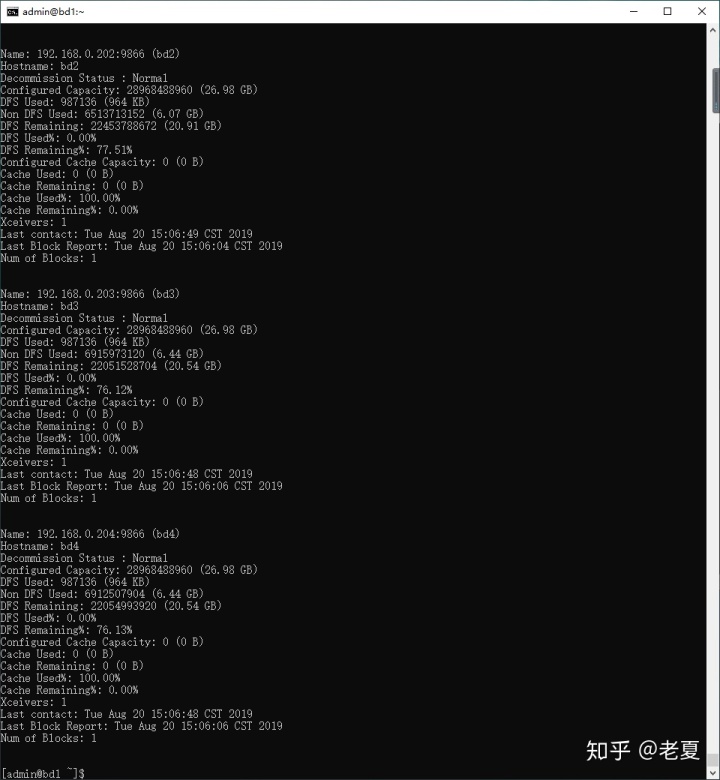
一种是在任何一个节点上运行如下命令:
hdfs dfsadmin -report得到如下结果,说明我们的四个节点都在正常运行(注意,两张图合一起是四个节点的信息):
另一种方式,是通过网页查看:http://bd1.sos:9870。结果如下图:

可以看到,有4个Live Nodes。或可以点击最上面的Datanodes查看详细信息:

我们可以简单地往HDFS里保存一个文件,来查看整个HDFS各DataNode的变化。用下面的命令从本地系统往HDFS保存一个文件:
hdfs dfs -copyFromLocal ~/hadoop/etc/hadoop/hdfs-site.xml /此命令会将hdfs-site.xml文件拷贝到HDFS中的根目录。之后我们可以通过如下命令查看:
hdfs dfs -ls /
也可以通过网页查看:

上图中我们可以看到,节点1、2、4中多了一个Blocks,因为我们设置的replication是3,所以所有的文件会被保存在3个节点上,而到底是哪3个节点,由hadoop自己决定。

上图我们可以看到HDFS的根目录中多了一个hdfs-site.xml文件,而且Replication是3.
至此,我们已经有了一个工作的分布式Hadoop集群。下一篇,我会深入探讨一下如何与Hadoop的交互。
声明
- 目录中的文章在陆续更新中,如果无法访问,请耐心等待。
- 本人是个实用主义者,有时候为了方便理解和记忆,并不一定完全严谨,欢迎交流。
- 文章中用到的一些图片是借来的,如有版权问题,请及时与我联系更换。















 4328
4328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









