





全文共2391字,预计学习时长14分钟

图源:morioh
工作中,无穷无尽的表格有时会令人抓狂。Excel无处不在,即便有着像Python这样的强大工具任你使用,你也难以从中逃脱。
也许你的老板和同事仍然需要这种简单的方法来访问重要数据。但没关系!那并不意味着你不能通过使用Python来简化Excel工作。
全程无需使用Excel,逃离报表魔爪!
用Python将Excel报表自动化
你还在天天做Excel报表吗?而且还是为不同的客户做着四五次同样的报表吗?不如让Python代劳吧!
通过使用笔者在数据透视表教程中的数据(https://towardsdatascience.com/a-step-by-step-guide-to-pandas-pivot-tables-e0641d0c6c70),概览一下我们将要自动化到底是什么。
数据格式将使你期望从公司数据库中获得的内容与客户销售数据相匹配,与你期望从公司数据库中获得的数据相匹配。它按区域细分这些数据,并且创建两个带有格式和图表的汇总表。无需使用Excel!
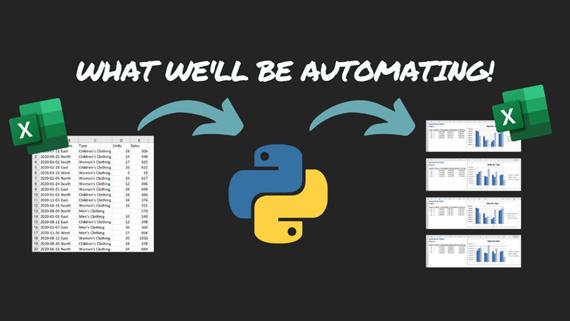
最终的数据流—一个工作簿转化为四个格式化报告 | 图源:Nik Piepenbreier
加载库
使用Pandas和Openpyxl。笔者的“用Python自动化这三项(无聊!!!)Excel任务”( https://towardsdatascience.com/automate-these-3-boring-excel-tasks-with-python-666b4ded101b)一文中涵盖了许多关于Openpyxl的内容,对其如何运行提供了详细介绍。
#Section 1 - Loading our Libraries import pandas as pd fromopenpyxl import load_workbook from openpyxl.styles importFont from openpyxl.chart importBarChart, Reference你使用如下两个Librariy:
1. Pandas负责转化数据,并创建初始Excel文件
2. Openpyxl将工作薄格式化,并插入图表
加载数据
加载数据,并概览正在处理的内容。正如笔者所提到的,这些数据与读者从公司数据库系统获得的数据相似。
#Section 2 - Loading our Data df = pd.read_excel('https://github.com/datagy/pivot_table_pandas/raw/master/sample_pivot.xlsx', parse_dates=['Date']) print(df.head()) # Date Region Type Units Sales #0 2020-07-11 East Children's Clothing 18.0 306 #1 2020-09-23 North Children's Clothing 14.0 448 #2 2020-04-02 South Women's Clothing 17.0 425 #3 2020-02-28 East Children's Clothing 26.0 832 #4 2020-03-19 West Women's Clothing 3.0 33在这里,使用Pandas读取Excel文件,并读取Date/日期列的日期。
创建数据透视表
接着我们要创建最终报告中所需要的汇总表。这里将创建一个数据透视表以作为例子,其中仅使用东部地区进行代码的实验。
#Section 3 - Testing Pivot Tables filtered= df[df['Region'] =='East'] quarterly_sales= pd.pivot_table(filtered, index =filtered['Date'].dt.quarter, columns ='Type', values ='Sales', aggfunc='sum') print("Quarterly Sales Pivot Table:") print(quarterly_sales.head()) #Quarterly Sales Pivot Table: #Type Children's Clothing Men'sClothing Women's Clothing #Date #1 12274 13293 16729 #2 5496 17817 22384 #3 14463 9622 15065 #4 13616 10953 16051创建第一个Excel文件
有了数据透视表后,将其导入到一个Excel文件中,我们将用pandas来导入:
#Section 04 - Creating and Excel Workbook file_path=#Path to where you want your file saved quarterly_sales.to_excel(file_path, sheet_name ='Quarterly Sales', startrow=3)这一步是在做什么:
· 创建一个文件路径变量,以确定要将文件存储在何处,
· 使用ExcelWriter保存文件
· 将两个透视表保存到单独的工作表中,从第3行开始(稍后从中保留以用于页眉)
使报表更漂亮
Pandas有助于将数据导入到Excel中。既然数据已经导入Excel,不妨将其美化一下,来添加一些可视化效果。
#Section 05 - Loading the Workbook wb =load_workbook(file_path) sheet1= wb['Quarterly Sales'] # Section 06 - Formatting the First Sheet sheet1['A1'] ='Quarterly Sales' sheet1['A2'] ='datagy.io' sheet1['A4'] ='Quarter' sheet1['A1'].style ='Title' sheet1['A2'].style ='Headline 2' for i inrange(5, 9): sheet1[f'B{i}'].style='Currency' sheet1[f'C{i}'].style='Currency' sheet1[f'D{i}'].style='Currency' # Section 07 - Adding a Bar Chart bar_chart=BarChart() data=Reference(sheet1, min_col=2, max_col=4, min_row=4, max_row=8) categories=Reference(sheet1, min_col=1, max_col=1, min_row=5, max_row=8) bar_chart.add_data(data, titles_from_data=True) bar_chart.set_categories(categories) sheet1.add_chart(bar_chart, "F4") bar_chart.title ='Sales by Type' bar_chart.style=3 wb.save(filename = file_path)在Section 5中,将工作簿和工作表加载到Openpyxl可以处理的单独对象中。
而Section 6中操作更多:
· 在表一的A1和A2单元格中添加标题和副标题。
· 更改“quarters”列的标题,使其更能反映数据。
· 对标题和副标题应用样式。
· 将金融领域的单元格转换为货币。这需要对每单个单元格进行单独处理。因此使用了for循环。
在Section 7中,添加了条形图:
· 创建一个条形图对象,并识别存储数据和类别的字段。
· 随后将数据和类别应用于对象。
· 最后,添加描述性标题和样式。使用许多不同的样式都试试!
这就是工作簿现在的样子:
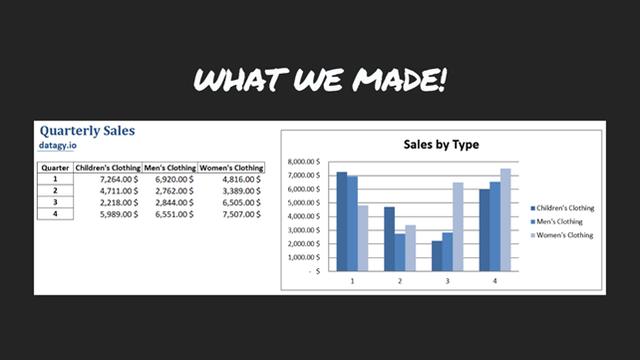
所得工作簿之一 | 图源: Nik Piepenbreier
对多个工作簿执行工作流自动化
虽然已经很方便了,但是仅在一个区域执行这样的操作只能节约一点点的时间。我们可使用for循环,对所有的区域执行此操作。
#Section 08 - Getting Region Names regions =list(df['Region'].unique()) # Section 09 - Looping Over All Regions folder_path=#Insert the path to the folder you want tosave the reports in for region in regions: filtered =df[df['Region'] ==f'{region}'] quarterly_sales = pd.pivot_table(filtered, index =filtered['Date'].dt.quarter, columns ='Type', values ='Sales', aggfunc='sum') file_path =f"{path to your folder}{region}.xlsx" quarterly_sales.to_excel(file_path,sheet_name ='QuarterlySales', startrow=3) wb =load_workbook(file_path) sheet1 = wb['Quarterly Sales'] sheet1['A1'] ='Quarterly Sales' sheet1['A2'] ='datagy.io' sheet1['A4'] ='Quarter' sheet1['A1'].style ='Title' sheet1['A2'].style='Headline 2' for i inrange(5, 10): sheet1[f'B{i}'].style='Currency' sheet1[f'C{i}'].style='Currency' sheet1[f'D{i}'].style='Currency' bar_chart =BarChart() data =Reference(sheet1, min_col=2, max_col=4, min_row=4, max_row=8) categories =Reference(sheet1, min_col=1, max_col=1, min_row=5, max_row=8) bar_chart.add_data(data,titles_from_data=True) bar_chart.set_categories(categories) sheet1.add_chart(bar_chart,"F4") bar_chart. bar_chart.style =3在Section 8中,创建了一个列表,其中包含了想要覆盖的不同区域的所有唯一值。
在Section 9中,在for循环中重复先前的代码:
· 创建一个新变量,该变量用于保存文件所在文件夹的路径
· 接下来,使用f-strings将区域名插入到脚本中,使得脚本对每个区域都是动态的。

图源:unsplash
Python的好处在于,它可使重复的任务具有可伸缩性。
想象一下,如果你每天都会收到这份文件,并且每天都要创建这些工作簿。这种方法能帮你节省多少时间!

留言点赞关注
我们一起分享AI学习与发展的干货
如转载,请后台留言,遵守转载规范
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









