





Numpy学习笔记(上篇)
[TOC]
一、Jupyter Notebook的基本使用
首先需要安装anaconda,安装完成之后会自带Jupyter Notebook,启动之后会自动打开默认浏览器,启动一个“在线终端”,然后选择路径之后,就可以开心滴使用啦!debug时很好用,能随时随地可视化每一步的结果。小Tip:查看jupyter Notebook中的快捷键:
常用快捷键:
A: 在上面插入代码块 B: 在下面插入代码块 X: 剪切选择的代码块
C: 复制选择的代码块 Y: 把代码块变成代码 M: 把代码块变成标签
L: 显示行号
Shift-Enter: 运行代码块, 选择下面的代码块
Ctrl-Enter: 运行选中的代码块
Alt-Enter: 运行代码块并且插入下面
此外,在Jupyter Notebook中可以使用markdown格式写一些备注等。markdown使用方法:
二、Jpuyter Notebook的魔法命令
1、%run
用来直接调用外部脚本命令,举个例子,现在有这么一个函数:
def main():
for i in range(5):
print("hello world")
main() 如果直接pycharm这种IDE中很容易就能运行出结果,但是如果想要在Jupyter Notebook中调用这个函数呢?
%run xxx文件路径/xxx.py 这样就把这个函数加载进了jupyter notebook,这样方便再次调用。
2、%timeit & %%timeit
%timeit L = [i**2 for i in range(1000)]运行输出结果:275 µs ± 6.83 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit L = [i**2 for i in range(1000000)]运行输出结果:302 ms ± 2.17 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
它会自动运算很多次,然后取平均值,至于多少次需要根据你的运算量和电脑性能综合考虑。timeit这个魔法命令后面智能接一行代码也就是一个语句,如果想要运行一个代码块呢?那就使用%%timeit
%%timeit
L = []
for i in range(1000):
L.append(i**2)运行输出结果:288 µs ± 4.03 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
那么此时还有一个问题,就是有时我们不需要计算多次取平均值,就是想只算一次时间。怎么办?
此外还有一个问题需要注意的是在相同一段程序执行多次时间差异很大的时候,比如排序算法,事先排好序和乱序丢一个数据查找或搜索,所用的时间一定是不一样的。因此在计算时间的时候需要留意。
3、%time
使用方法和timeit一样,区别就是time对于时间只计算一次。但是如果只计算一次时间是不准确的,因为在运算的过程中不仅要考虑cpu的运行状态,线程等还要有初始加载一些包所带来的延迟,所以同一段代码运行的多次,时间可能不太一样。
%time L = [i**2 for i in range(1000000)]运行输出结果: Wall time: 292 ms
%%time
L = []
for i in range(1000):
L.append(i**2)运行输出结果:Wall time: 12.7 ms
有人评论说这块写的有点乱,我在这里再对上面进行一下总结: 1、%%time将会给出cell的代码运行一次所花费的时间 2、%time将会给出当前行的代码运行一次所花费的时间。 这是%和%%的区别之处。
4、其他魔法命令
%lsmagic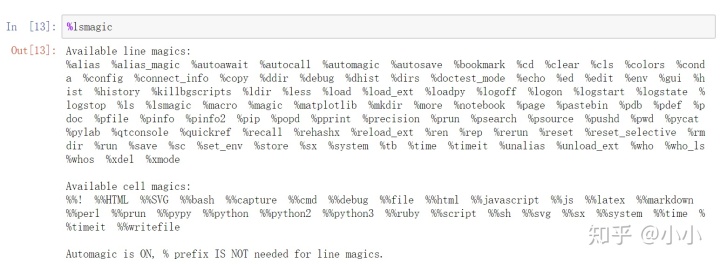
这样就能查看到所有的魔法命令,如果有需要可以去单独查询某个魔法命令的具体用法。或者使用jupyter Notebook中的帮助命令,在jupyter notebook中运行%xxx?命令之后,会出一个弹框,里面有具体的使用方法,其他命令也是如此。
二、Numpy.array基础
- 查询版本号
python import numpy numpy.__version__
运行输出结果:'1.16.2'
python import numpy as np np.__version__sion__
运行输出结果:'1.16.2'
- 为什么要使用numpy.array呢?
我们先来看一下python list的特点。
python L = [i for i in range(10)] L
运行输出结果:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
python L[5] = 100 L
运行输出结果:[0, 1, 2, 3, 4, 100, 6, 7, 8, 9]
python L[5] = "Macchine learning" L
运行输出结果:[0, 1, 2, 3, 4, 'Macchine learning', 6, 7, 8, 9]
通过上面的例子我们可以发现在python中list的元素可以很容易被修改或者替换,但是这也带来一个问题,就是效率相对比较低。因为它要检查每个元素是哪种类型。那么在python其实也有只能创建一种类型的数组。
python import array arr = array.array('i', [i for i in range(10)]) arr
运行输出结果:array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
那么此时我们再把array中的元素赋值为字符串时就会报错!这个虽然降低了array的灵活性,但是提高了效率。但是array又有一定的缺点,那就是它只是单纯滴把这个数组看成一组数据,既不是向量也不是矩阵,而且没有向量和矩阵的运算。所以numpy array出现!
3.numpy array
python import numpy as np nparr = np.array([i for i in range(10)]) nparr
运行输出结果:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
既然array只能存储一种数据类型,那么我们来查看一下:
python nparr.dtype
运行输出结果:dtype('int32')
python nparr[5] = 5.0 nparr
运行输出结果:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
此时我们可以发现哪怕我们把数据中某个元素赋值为浮点型数据,最终的结果依旧是int32。其实是np进行了隐式的数据转换。他会自动进行数据截位。
python nparr2 = np.array([1, 2, 3.0]) nparr2.dtype
运行输出结果:dtype('float64')
三、创建numpy数组与矩阵
- np.zeros(shape=?, dtype=?) 默认就是浮点型
python import numpy as np np.zeros(10)
运行输出结果:array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
通过运行结果就可以发现array是一个浮点型的数据,那么如果想要创建整形呢?
python import numpy as np np.zeros(10, dtype=int)
运行输出结果:array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
python import numpy as np np.zeros(shape=(3, 5), dtype=int)
运行输出结果:
array([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]])
- np.ones(shape=?, dtype=?)
python import numpy as np np.ones(10)
运行输出结果:array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
python import numpy as np np.ones(shape=(3, 5), dtype=int)
运行输出结果:
array([[1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1]])
- np.full(shape=?, fill_value=?)
python import numpy as np np.full((3, 5), 666)
运行输出结果:
array([[666, 666, 666, 666, 666], [666, 666, 666, 666, 666], [666, 666, 666, 666, 666]])
- np.arange(起始值,终止值,步长), 默认步长为1
np.arange()和range()用来基本相同,区别在于,range的步长必须为整数,而np.array可以是小数。
PYTHON import numpy as np np.arange(0, 1, 0.2)
运行输出结果:array([0. , 0.2, 0.4, 0.6, 0.8])
- np.linspace(起始值,终止值,数量),就是在起始值和终止值之间去数量个数,包括起始值和终止值。
python import numpy as np np.linspace(1, 20, 5)
运行输出结果:array([ 1. , 5.75, 10.5 , 15.25, 20. ])
- np.random
- np.random.randint() 从0-10之间创建一个随机整数
python import numpy as np np.random.randint(0, 10)
运行输出结果:5
python import numpy as np np.random.randint(0, 10, 10)
运行输出结果:array([9, 5, 2, 0, 5, 3, 5, 3, 0, 4])
python import numpy as np np.random.randint(0, 10, size=(3, 5))
运行输出结果:
array([[5, 2, 1, 9, 1], [0, 3, 9, 4, 1], [6, 2, 3, 6, 8]])
在机器学习算法中,有很多地方都会用到随机初始化的这一方法,那么这样对于调试代码就带来了一定的麻烦,其实,在计算机当中,所谓的随机数都是伪随机数。靠随机数生成算法完成的。那么就有了随机种子。在numpy中np.random.seed(),这样运行多少次都是这样的随机数。
- np.random.seed()
python import numpy as np np.random.seed(666) np.random.randint(0, 10, size=(3, 5))
运行输出结果:
array([[2, 6, 9, 4, 3], [1, 0, 8, 7, 5], [2, 5, 5, 4, 8]])
- np.random.random() 生成一个0-1之间均匀分布的随机数。
python import numpy as np np.random.random()
运行输出结果:0.7315955468480113
python import numpy as np np.random.random(10)
运行输出结果:
array([0.8578588 , 0.76741234, 0.95323137, 0.29097383, 0.84778197, 0.3497619 , 0.92389692, 0.29489453, 0.52438061, 0.94253896])
python import numpy as np np.random.random((2, 3))
运行输出结果:
array([[0.07473949, 0.27646251, 0.4675855 ], [0.31581532, 0.39016259, 0.26832981]])
- np.random.normal() 生成一个0-1之间正态分布的随机数。
python import numpy as np np.random.normal()
运行输出结果:0.7760516793129695
python import numpy as np np.random.normal(10, 100) # 均值为10,方差为100
运行输出结果:128.06359754812632
python import numpy as np np.random.normal(0, 1, (3, 5))
运行输出结果:
array([[ 0.06102404, 1.07856138, -0.79783572, 1.1701326 , 0.1121217 ], [ 0.03185388, -0.19206285, 0.78611284, -1.69046314, -0.98873907], [ 0.31398563, 0.39638567, 0.57656584, -0.07019407, 0.91250436]])
- 查询文档,查看函数中的每个参数的默认值等等
python np.random.normal? np.random? help(np.random.normal)
四、Numpy.array的基本操作
import numpy as np
x = np.arange(10)
X = np.arange(15).reshape(3, 5)运行输出结果:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
运行输出结果:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])- 基本属性
- ndim
python x.ndim X.ndim
运行输出结果:1
运行输出结果:2
- shape
python x.shape X.shape
运行输出结果:(10,)
运行输出结果:(3, 5)
- size
python x.size X.size
运行输出结果:10
运行输出结果:15
- 数据访问
- 一维数组
python x[0] X[0][0] # 在多维数组中不建议这样使用,建议使用X[0, 0]
运行输出结果:0
运行输出结果:0
python x[2:] x[5:] x[::2] # 表示从头到尾每间隔2取一个
py x[::-1]
运行输出结果:array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
- 二维数组
比较一下下面这两种方法。
python X[:2][:3] X[:2, :3]
python X[::-1, ::-1]
运行输出结果:
array([[14, 13, 12, 11, 10], [ 9, 8, 7, 6, 5], [ 4, 3, 2, 1, 0]])
- 子数组
python subX = X[:2, :3] subX
运行输出结果:
array([[0, 1, 2], [5, 6, 7]])
如果对subX中的元素进行修改赋值,那么会不会对X造成影响呢?
python subX[0, 0] = 100 subX
运行输出结果:
array([[100, 1, 2], [ 5, 6, 7]])
python X
运行输出结果:
array([[100, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [ 10, 11, 12, 13, 14]])
此时,会发现X也发生了变化,在python中对列表进行切片的时候是创建了一个新的列表,但是在numpy.array中采取的是引用的方式,如果对其子数组进行修改原数组也会进行相应的改变,这样能够提升效率。
- reshape
python x.reshape(2, 5)
运行输出结果:
array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
此时x并没有发生改变,因此我们需要将其进行赋值给一个变量。
python B = x.reshape(1, 10) B
运行输出结果:array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
python C = x.reshape(10, -1) C
运行输出结果:
array([[0], [1], [2], [3], [4], [5], [6], [7], [8], [9]])
我是尾巴
每篇一句毒鸡汤:明明才二十来岁,为什么有一种一辈子就这样了的感觉?
这是上篇,下篇继续!本次推荐:一款可以随意编辑pdf的软件,Icecream PDF editor
加油ヾ(◍°∇°◍)ノ゙















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









