





在开始文章之前,分享一个有趣的小故事:
1927年第五届索维尔会议上,爱因斯坦与波尔关于量子力学的争论达到了白热化。爱因斯坦严肃的说,“波尔,上帝不会投骰子!”。而波尔则回应说,“爱因斯坦,别去指挥上帝应该怎么做!”。爱因斯坦坚决不相信物理学最本质的规律是统计性的。
我们今天聊的也是关于统计的算法,看一看抛硬币的故事
一、提出问题
现在我提出这样一个问题:假设一个网站每日有数以亿计的IP访问,如何高效统计ip访问的规模?
这个问题的规模很大,ip访问记录数以亿计的规模,看上去是很吓人的,但其实我们并不关心具体哪些ip访问,也不是特别在意具体的精确数字,或许这只是个模糊的需求,提问题的同学只想要知道大概的规模,但是并不关心具体的精确数字。
二、解决问题
这个问题可以怎么来解决?我们可以非常容易的想到以下这些方法:
1. 字典或者哈希
将ip放到字典中,我们可以很容易的去重统计ip数。这个方法问题在于,当ip数量非常多时,非常消耗内存,我们假设一个IP占用4B,那么10亿个IP需要的内存为40GB,这个容量太大了!
如果一个应用中的一个统计功能需要40GB,显然我们是不能接受的。同时插入的复杂度也不低,并且两个计数量要合并的话,无论是树结构还是哈希结构效率都是不高的。
2. bitmap
内存太高,我们会想到用一个比特位来表示一个ip,ip本来就是个32位的整数,我们把这个整数映射到对应的一个比特位,这就成了一个bitmap。使用bitmap占用的空间约为上面方法的1/32,这也需要1.25GB的容量。减少了非常多,bitmap对于多个计数量的合并要简单的多。
但还是感觉不太满意。
三、更好的方法?
那么,有没有更好的方法呢?答案当然是有的。统计学里面有一类专门处理这个问题的方法,叫做基数统计。
基数统计(cardinality counting)指的是统计一批数据中的不重复元素的个数,常见于计算独立用户数(UV)、维度的独立取值数等等。实现基数统计最直接的方法,就是采用集合(Set)这种数据结构,当一个元素从未出现过时,便在集合中增加一个元素;如果出现过,那么集合仍保持不变。
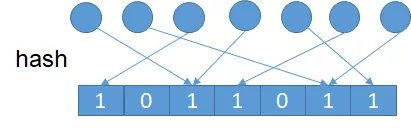
我们通过一个均匀的hash函数将元素hash到一个bit数组的一位,将其置为1。看起来和bitmap很像是不是?这里不一样的点是bitmap每个元素都通过一个唯一的bit位相关联,而这里则通过的hash函数。hash函数是必然可能存在冲突的,不会保证一一对应。设元素个数为n,bit数组的长度为m,n个元素hash后还有s个bit位为0。
我们可以通过下面这个公式来估计n, 这个方法称为LC(见参考文献1)。
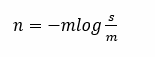
推导过程如下:由hash函数定义可知:n个元素的hash结果服从独立均匀分布,设Xi 为n个元素映射后第i位任为0。
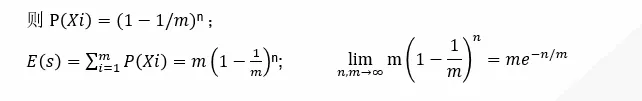
因此,可用上述公式估计元素规模。LC为了控制误差率,要求m为n约十分之一。相比bitmap只做了空间的常数级优化。
四、更上一层楼?
这样就结束了吗,能不能再精致点?我们先从一个游戏开始,我们叫它伯努利实验——没错这个名字就是借用统计学的伯努利硬币实验设计的游戏。

假设A和B两个人进行抛硬币的游戏,A来抛硬币,B来猜,规则如下:
1.A每轮抛硬币直到出现一次正面为止,记为一次伯努利实验,并记下抛的次数,记为伯努利值K;
2.A进行n轮伯努利实验,并记下n次伯努利值的最大值M;
3.A将M告诉B,B猜A大概进行了多少次伯努利实验即n的大概大小。
如果你是B,如何猜测n的大小呢?答案是:N约等于2的M次方。
为什么会是这样一个结果呢?我们来简单分析一下:
回忆伯努利实验的规则,我们可以得出以下两个结论:
1. n次伯努利过程,每轮投掷次数都不大于M;
2. n次伯努利过程,至少有一轮投掷次数等于M;
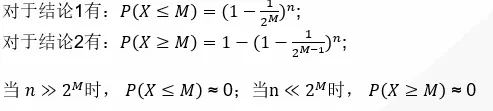
显然,我们可以用上述公式来估计n的规模,详细数学论证及误差率控制参考文末论文LLC(见参考文献2)和HLLC(见参考文献3)。那么如何实现LLC和HLLC呢?

首先我们将元素a通过hash映射为长度为L的bit串,从左向右扫描第一个不为0的比特位的过程,可以理解为统计意义上的伯努利过程,设M为n个元素第一个不为0的比特位最大的位置。则可根据N约等于2的M次方,通过M可估计n的大小规模。
为减少偶然性因素对算法的影响,如某个元素不为0的比特位非常靠后。可以将比特位分组。
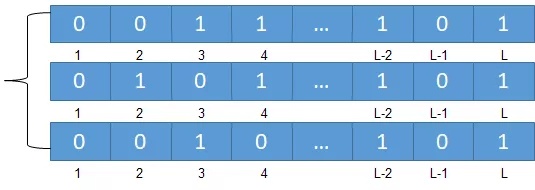
证明过程来啦:假设哈希长度为16bit,分桶数m定为32。设一个元素哈希值为“00010 01010001010”,前5个bit为桶编号,所以元素放入“00010”即2号桶,而剩下部分第一个非0比特位为2。这里设元素的hash值为“00010 01010001010”,如果不分桶的情况下,我们用从左向右扫描的方式来模拟伯努利过程,找到第一个非0的位置为4,这个也就是这轮的情况的情况,我们可以用一个变量记录这个最大值,假设n个元素映射后最大的任然为4,那我们可以猜测这个元素集合个数为16;但这里存在一个问题,假设某个元素映射值极为偶然,导致前面位数都为0,1的位置非常靠后(当然我们可以按照均匀分布计算这种情况的概率极低),这个时候会导致计算的n值非常大,也就是存在较低的概率使计算结果偏差非常大。
但是如果我们把hash值的前面s位用来分桶,也就是我们用多个变量来记录最大值M,这种情况下,多个桶同时出现偏差值的概率可以忽略不计,多个平均值将异常值平衡掉。

LLC和HLLC的不同点,就在于如何统计M值,LLC采用算术平均值;HLLC采用调和平均数。两者差别在于算术平均数更容易受离群值的影响,导致容易受偶然因素干扰。
根据估算公式,可以很容易的得到LLC和HLLC的算法空间复杂度为O(log(log(n))。
最后就是见证奇迹的时候,假设有一个2的64次方的元素个数,采用LLC或者HLLC只需要6个比特位就可以估算元素规模。
回忆下我们前面提到的字典或者bitmap方法,按照这样的方法,我们就需要2^64/2^10/2^10/2^10=2^36GB,需要EB级的存储,数学的魅力在这里就体现的淋漓尽致!而Redis的HyperLogLog正是采用的HLLC算法来实现集合元素统计的。
参考文献:
【1】A linear-time probabilistic counting algorithm for database applications
【2】Loglog Counting of Large Cardinalities
【3】HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm

↓↓更多惊喜优惠请点这儿~
云数据库 超值采购专场cloud.tencent.com














 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









