





Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能
它是一个工具箱,通过解析文档为用户提供需要抓取的数据
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码
安装
pip install bs4
创建一个字符串
html="""
The Dormouse's storyThe Dormouse's story
Once upon a time there were three little sisters; and their names were,LacieandTillie;
and they lived at the bottom of a well.
...
"""使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出
from bs4 importBeautifulSoup
soup=BeautifulSoup(html,"html.parser")print(soup.prettify())

也可以用本地 HTML 文件来创建对象
soup=BeautifulSoup(open("index.html"),"html.parser")
prettify()格式化输出,将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行
四种Beautiful Soup对象类型
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象有4种
Tag
HTML 中的标签
print(soup.title)

print(soup.a)

Tag的属性, name 和 attrs
name
print(soup.name)print(soup.p.name)
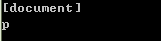
soup 对象的name 即为 [document],对于其他标签,输出的值便为标签本身的名称
attrs
print(soup.p.attrs)print(soup.p['class'])
soup.p['class']="newClass"
print(soup.p.get('class'))print(soup.p)del soup.p['class']print(soup.p)

NavigableString
获取标签内部的文字,用 .string
print(soup.p)print(soup.p.string)print(type(soup.p.string))

BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.可以把它当作特殊的Tag 对象
print(type(soup.name))print(soup.name)print(soup.attrs)

Comment
Comment 对象是一个特殊类型的 NavigableString 对象
用CDATA来替代注释
from bs4 importBeautifulSoup,CData
markup= ""soup= BeautifulSoup(markup,"html.parser")print(soup.b.prettify())
comment=soup.b.string
cdata= CData("A CDATA block")
comment.replace_with(cdata)print(soup.b.prettify())

遍历文档树
1.子孙节点
(1)contents
将tag的子节点以列表的方式输出
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")
head_tag=soup.headprint(len(soup.contents))print(head_tag)
contents=head_tag.contentsprint(contents)
title_tag=head_tag.contents[0]print(title_tag)
text=title_tag.contents[0]print(text)

说明:
字符串没有 .contents 属性,因为字符串没有子节点
(2)children
得到一个节点的迭代器,可以遍历之获取其中的元素
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")
head_tag=soup.head
contents=head_tag.contents
title_tag=head_tag.contents[0]for child intitle_tag.children:print(child)

(3)descendants
对所有tag的子孙节点进行递归循环
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")
head_tag=soup.headfor child inhead_tag.descendants:print(child)

from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")print(len(list(soup.children)))print(len(list(soup.descendants)))

(4)string
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")
head_tag=soup.head
contents=head_tag.contents
title_tag= head_tag.contents[0]
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点
print(title_tag.string)

如果一个tag仅有一个子节点,那么这个tag也可以使用
print(head_tag.string)

如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None
print(soup.html.string)

(4)strings
如果tag中包含多个字符串 ,可以使用 .strings 来循环获取
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")for string insoup.strings:print(repr(string))

.stripped_strings 可以去除多余空白内容
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")for string insoup.stripped_strings:print(repr(string))

全部是空格的行会被忽略掉,段首和段末的空白会被删除
2.父亲节点
(1)parent
获取某个元素的父节点
soup=BeautifulSoup(open("index.html"),"html.parser")
head_tag=soup.head
contents=head_tag.contents
title_tag=head_tag.contents[0]print(title_tag)#
标签是标签的父节点print(title_tag.parent)#顶层节点比如的父节点是 BeautifulSoup 对象
print(type(soup.html.parent))#BeautifulSoup 对象的 .parent 是None
print(soup.parent)

(2).parents
递归得到元素的所有父辈节点
遍历了标签到根节点的所有节点
soup=BeautifulSoup(open("index.html"),"html.parser")
link=soup.aprint(link)for parent inlink.parents:if parent isNone:print(parent)else:print(parent.name)

3.兄弟节点
(1)next_sibling下一个节点
(2)previous_sibling上一个节点
sibling_soup = BeautifulSoup("text1text2",'html.parser')print(sibling_soup.prettify())
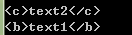
print(sibling_soup.b.next_sibling)
print(sibling_soup.c.previous_sibling)
(3)next_siblings所有的后续节点
(4)previous_siblings所有之前的节点
soup=BeautifulSoup(open("index.html"),"html.parser")for sibling insoup.a.next_siblings:print(repr(sibling))for sibling in soup.find(id="link3").previous_siblings:print(repr(sibling))
4.前后节点
(1)next_element
下一个被解析的对象
(2)previous_element
前一个解析对象
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")
last_a_tag= soup.find("a", id="link3")print(last_a_tag)print(last_a_tag.next_element)print(last_a_tag.previous_element)

树的搜索
(1) find_all()
搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
from bs4 importBeautifulSoup
soup=BeautifulSoup(open("index.html"),"html.parser")print(soup.find_all("a"))print(soup.find_all(id="link2"))importreprint(soup.find(string=re.compile("sisters")))#Once upon a time there were three little sisters; and their names were
格式: find_all( name , attrs , recursive , string , **kwargs )
说明:
(a)name 参数
可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉
eg:soup.find_all("title")
(b)keyword 参数
指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索
如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性
eg:soup.find_all(id='link2')
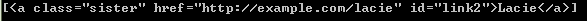
如果传入 href 参数,Beautiful Soup会搜索每个tag的”href”属性
eg:soup.find_all(href=re.compile("elsie"))

查找所有包含 id 属性的tag,无论 id 的值是什么
eg:soup.find_all(id=True)

有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性,可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag
from bs4 importBeautifulSoup
data_soup= BeautifulSoup('

(c)CSS搜索
eg:soup.find_all("a", class_="sister")
(d)string参数
eg:
soup.find_all(string=["Tillie", "Elsie", "Lacie"])
(e)limit参数
限制返回结果的数量
eg:
soup.find_all("a", limit=2)
(f)recursive
只搜索tag的直接子节点,使用参数 recursive=False
(1)find()
格式: find( name , attrs , recursive , string , **kwargs )
soup.find_all('title', limit=1) #返回结果是值包含一个元素的列表,没有找到目标是返回空列表
soup.find('title') #直接返回结果,找不到目标时,返回 None
获取文档内容
get_text()
可以获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
frombs4 import BeautifulSoup
markup= '\nI linked to example.com\n'soup= BeautifulSoup(markup,"html.parser")
print(soup.get_text())
print(soup.i.get_text())

可以通过参数指定tag的文本内容的分隔符
frombs4 import BeautifulSoup
markup= '\nI linked to example.com\n'soup= BeautifulSoup(markup,"html.parser")
print(soup.get_text("|"))

可以去除获得文本内容的前后空白
frombs4 import BeautifulSoup
markup= '\nI linked to example.com\n'soup= BeautifulSoup(markup,"html.parser")
print(soup.get_text("|", strip=True))

用 .stripped_strings获得文本列表
frombs4 import BeautifulSoup
markup= '\nI linked to example.com\n'soup= BeautifulSoup(markup,"html.parser")
print([textfor text in soup.stripped_strings])

安装解析器
创建 BeautifulSoup 对象
解析器使用方法优势劣势
Python标准库
BeautifulSoup(markup, "html.parser")
Python的内置标准库
执行速度适中
文档容错能力强
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差
lxml HTML 解析器
BeautifulSoup(markup, "lxml")
速度快
文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup, ["lxml-xml"])
BeautifulSoup(markup, "xml")
速度快
唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, "html5lib")
最好的容错性
以浏览器的方式解析文档
生成HTML5格式的文档
速度慢
不依赖外部扩展
pip install html5lib
pip install lxml
lxml解析器,效率更高
参考资料:
http://beautifulsoup.readthedocs.io/zh_CN/latest/















 2958
2958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









