







去年共有278天领用了物料,记录在278张Excel表中。现在,老板想将所有物料按领用量从高到低排序,以便查看前10种领用最多的物料的情况。如果手工操作,需要把每张工作表的内容合并在一起,再用数据透视表来做。而对于这种重复操作,Phthon最擅长。我们可以用 实例22 的方法用Python将所有工作表合在一起,再用数据透视表操作。
但Python还有个功能强大的pandas(Python Data Analysis Library)库,专门用于做数据分析。它包含很多数据处理的函数和方法,可帮助我们快捷高效地处理数据。现在,我们就来演示如何用pandas统计一个Excel工作簿中278张表的数据并汇总,排序。我们先导入pandas库,为方便后续简化书写,大家都习惯于给它起个小名叫pd。
import pandas as pd然后我们先用pd.read_excel()打开第一张工作表,试试水,打开后存入变量df。传入要打开的工作簿,即'日领料单.xlsx'。数据的字段名在第三行,指定header=2。因为header是用0表示第一行,所以第三行对应的索引为2。第一张表的名称叫01-03,所以指定参数sheet_name = '01-03'。打开后,用df.head()看一下效果,这个函数值看头几行数据,括号内不填具体数量,则默认头五行。相对应的,df.tail()则是看末尾5行。
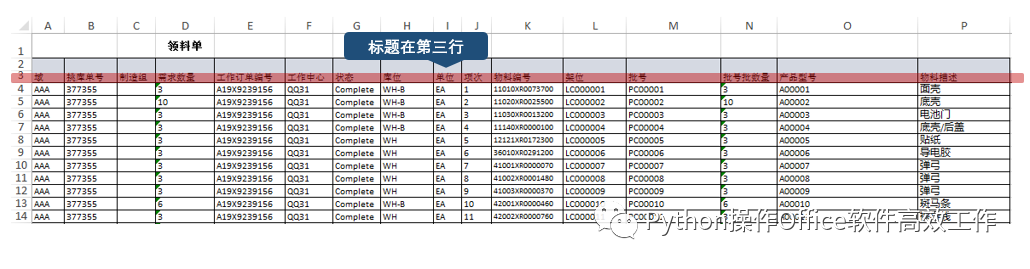
df = pd.read_excel('日领料单.xlsx' ,header=2, sheet_name = '01-03')
df.head()
数据显示与Excel表中完全一致,那就可以开始下一步了,即按照“物料编号”和“物料描述”字段将“批号批数量”加总。这里将使用到groupby(),它的作用是分组聚合,有点类似数据透视表中的“行”。此处我们按“物料编号”和“物料描述”分组聚合数据,并按“批号批数量”加总['批号批数量'].sum()。因为汇总数据后,行会减少(从191行减少到163行),所以需要重设行编号reset_index(),按0~162重新编号。
#按物料编号加总领料数量
df_sum = df.groupby(['物料编号 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









