





论文:https://arxiv.org/pdf/1603.02754.pdf
XGBoost是一个可扩展的tree boosting 系统,本论文提出了一种用于处理稀疏数据的稀疏感知算法,和用于近似学习的理论上合理的加权分位数草图。
XGBoost学习最耗时的一个步骤就是对特征的值进行排序, xgboost在训练之前,预先对数据按列进行了排序,然后保存为block结构,后面的迭代中重复使用这个结构,大大减小计算量。这个块结构也使并行成为了可能。在进行节点的划分时,需要计算每个特征的增益,最终选增益最大的那个特征去做划分,那么各个列的增益计算就可以多线程并行进行。
最后作者介绍了缓存访问模式,数据压缩和分片技术来实现tree boosting的高效利用处理器,内存,磁盘等资源。 通过结合这些技术,XGBoost能够使用最少量的资源解决现实大数据的规模问题。
1.论文主要目的:
1.1 设计一个端到端高可扩展的提升树系统(High Scalable End to End Boosting Tree System)。
1.2提供一个理论上合理的权重分位数草图来有效计算建议的分位点。
1.3 为并行计算树引入了一个树稀疏感知算法。
1.4 提出了一种有效的缓存感知块结构用于核外树学习。
2. XGBoost 目标函数
2.1 正则学习目标函数定义:
设一个有n个样本,m个特征数据集D:
存在K个树,对任意i样本的预测值输出为:
其中
每个树函数(例如回归树CART)
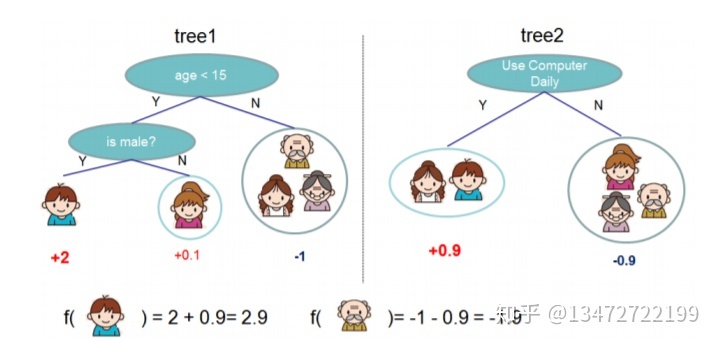
图一, 树集成模型。每个样本的预测值是每颗树的预测值之和。例如boy在第一颗树的预测值是2,第二颗树的预测值是0.9,boy最后得分2.9。
带有正则式的目标函数如下:
其中
2.2 Gradient Tree Booting
式(2)以函数作为参数不能用传统优化方法求解,使用一种附加的方式逐步训练模型的方式:
式(2)可以写成:
我们认为每颗提升树对预测的贡献很小的情况,根据泰勒展开式
式(4)可以进一步写成:
其中:
我们认为loss在前面的树结果不受后面树的影响,因此第t棵树预测来说,
由于
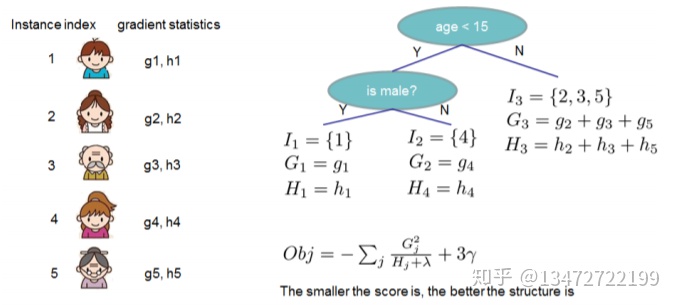
索引1的样本,映射到1的叶子节点。索引为4的的样本映射到2的叶子节点。索引为2,3,5的样本映射到3的叶子节点。按公式(7)有:
如果将相同的叶子节点项合并在一起上式又表示为:
定义
上式(7)可以写成:
对
式(9)代入式(8)求得:
式(10)通常用来评价这个颗树的效果。
通常不可能枚举所有可能树的结构来选择最佳的树。这种枚举所有可能树的贪心算法是:
先假设一个叶子节点的树,然后在它的基础上分裂一个树枝,不但做下去...
公式可以表示为:
假设某个叶子节点分裂成两个子节点。Loss 减少量记作:
=
.................................................(11)
式(11)用来评价叶子节点分裂的有效性。
2.3 收缩(学习速率)和列抽样(借鉴RF算法)
式(11)告诉应该通过哪个点分裂可以最大限度降低loss,同时树叶子点数会限制树无限划分下去。
有种贪婪算法:遍历所有属性及所有可能划分的点,找到最佳的划分点,算法如下:

算法复杂度: O(m*I)+ m*O(sort(n))
贪婪算法实例请参照我的另一篇文章:https://zhuanlan.zhihu.com/p/74284756
一个近似算法:

算法复杂度(m*l)l << n
使用按列下采样(column sub-sampling)一方面能防止过拟合,另一方面能并行加速计算。
3. 划分点发现算法(split finding algorithms)
3.1 基本的贪心算法
按式(11)能找到最好的分位点。一个暴力算法是在每个特征,枚举所有可能的分裂值来比较最好的分位点。这种计算还对数据集具有强烈的依赖关系。不同的训练集可能存在不同的划分点。另外需要对每个特征的值做一个排序。
3.2 近似算法
贪心算法一方面非常强大,另一方面效率低下,消耗非常多的系统资源。为了提高计算有效度一个近似算法是必要的。先按一个特征的分布的百分位数来预先选择一些候选的划分点。把连续值划分到对应的bucket中,减少划分点数。
根据给出划分时机不同,近似算法有两个变种:
全局的近似:是在新生成一棵树之前就对各个特征计算分位点并划分样本,之后在每次分裂过程中都采用近似划分
局部近似:就是在具体的某一次划分节点的过程中采用近似算法。
全局划分建议比局部划分建议需要更少的步骤,但需要更多的划分候选点才能达到局部划分建议的准确率。如下图所示:
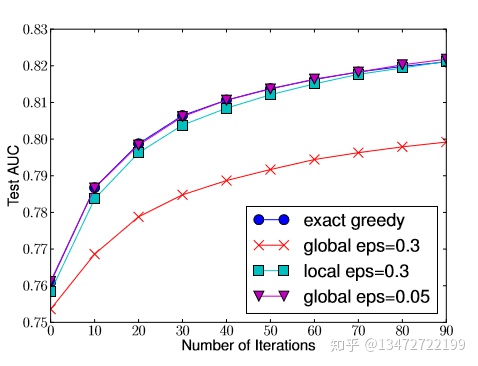
1 / eps 表示buckets数,在同等准确率的情况global比local需要更多的候选点。
作者的系统实现了贪婪算法,也可以选择全局划分和局部划分来实现近似算法。
3.3 带权重分位草图
在近似算法中,一个很重要的步骤是提议一些候选划分点。通常是用分布百分位进行划分。
假设有特征k分布的梯度统计数据集:
定义一个排序函数
目标是能找到候选的划分点
=
其中带有标签
3.4稀疏自适应划分发现
在现实世界中,属性
图:
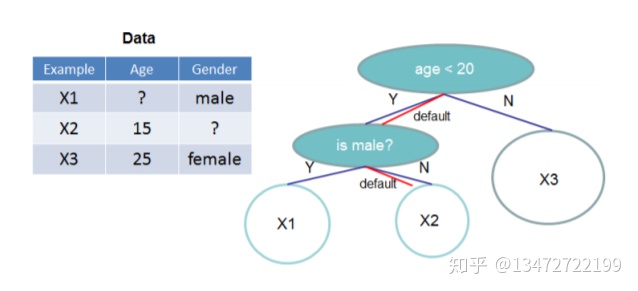
红色线表示在没有确定值时默认路径,例如实例X2属性Gender缺失的默认处理。

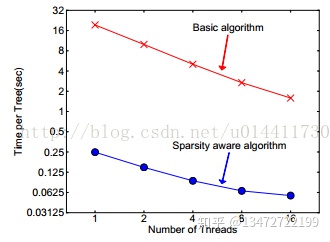
XGBoost通过一种统一的方式处理所有的稀疏性情况。当出现稀疏情况的时候,稀疏性计算只有线性的计算复杂度。如图所示,稀疏自适应算法比基本的非稀疏数据算法快大约50倍。
4.系统设计
4.1 并行计算列块
通常树学习要花费一段时间排序数据。为了减少这种花费,把数据存入叫块的内存单元。在块中数据以压缩格式存储,并且每列按特征值排序。输入数据每次训练前需要计算一次,以后的迭代中可以重用这次计算。
在贪婪算法中,整个数据集在单一块中,运行线性划分查找算法。对一个块的一次遍历可以收集所有分支划分点统计。
这种块结构也可以使用在近似计算中,它使用多块结构。每个块包含一个数据集的子集。不同的块可以分布在不同机器上。用这种结构,对已排序的列,划分查找也是线性复杂度。对每个列收集这种统计信息是并行的。更重要的是这种块结构支持列抽样,很容易对一个数据集的列进行选取列的子集。
时间复杂度分析:
设d是树的最大深度,k是树的棵数。贪婪并支持稀疏自适应算法复杂度是
对带有块结构的时间复杂度是
近似查找算法时间复杂度是
使用带块的结构,近似算法时间复杂度
4.2 缓存感知访问
虽然提出的块结构有助于优化计算复杂性的划分发现,新算法需要按行索引间接提取梯度统计信息,因为这些值是按特征顺序访问的。然而传统的实现需枚举的引入在累积和非连续之间引入立即读/写依赖性内存获取操作。如果不适合的CPU缓存导致缓存未命中, 这将降低划分查找梯度统计信息。
对贪婪算法,使用缓存感知的预提取算法来减轻这种问题。如果对数据集比较大时,对每个线程都分配一定缓存,把梯度信息保存在缓存中,然后执行收集在小批量训练。这种修改有助于减轻运行时间。
对近似算法,修改块的大小,使块能容纳这个块所有样本,但这样会加大统计梯度计算的缓存的负担。选择太小的块大小会导致每个线程只能担负小的工作量,导致没有效率的并行。大的块大小会导致缓存miss,从而降低了梯度统计运行效率。块大小要在并行效率和缓存效率取得平衡。
4.3块核外计算
我们目的是充分利用计算机资源实现可扩展学习。除了处理器和内存,在主存储设备外利用磁盘空间处理数据。为了使用核外计算,数据在磁盘上分成多个块。在计算时,一个独立的线程预先将数据加载到主内存。这样磁盘读和数据计算能并行运行。由于读数据需要花费很多时间,因此并不能解决所有问题。以下两个技术能提高核外计算能力。
块压缩技术:数据以压缩的形式存储在磁盘上,一个独立线程将压缩的数据读取到主内存中,这样平衡了从磁盘读取和计算时的效率,减少了读磁盘的时间和适当增加了计算时间花费。通过只存储起始行索引+16bit整数偏移量减少了行索引的存储。每个块可以存储
块分区:分区数据存储在多个磁盘上。每个磁盘分配一个预取线程将数据提取到一个
内存缓冲区。 训练线程从每个缓冲区读取数据。 这有助于增加多个磁盘可用时磁盘读取的吞吐量。















 4478
4478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









