







木 头 课 堂

实现接口自动化测试框架的设计,必然需要考虑到分层概念,那么具体分几层,如何分层,为什么要分层?
具体为什么要分层,如何分层前面已经详细讲过了,详见2.3.1 自动化测试如何分层
有同学肯定现在会说你前面讲的不是web自动化的吗?现在是接口自动化呀,实际分层的思想是不变的,只是略微实现上发生变化而已。例如:我们今天首先要考虑如何提取接口自动化的测试用例,那么我们就会将这部分操作定义到数据层。
——————————————
❶接口自动化测试用例模板
——————————————
首先,接口测试用例我们得思考使用什么进行管理,可以使用各种平台或者excel管理。假设使用禅道管理用例和缺陷,那么我们应该如何提取呢?
其实解决方式有很多,最常用的我们可以直接使用python读取禅道的数据库,分析出用例和bug对应的数据表,然后提取对应字段的数据即可。
再者还可以使用web自动化进行元素定位,获取核心的相关数据,当然这种稳定性不是很好,因为web自动化本身就存在环境的一定依赖问题,所以不建议使用这种方式。
当然,如果能够直接获取到禅道的后台的接口,那么直接访问禅道所提供的接口api即可。
我们传统大多数都是使用excel进行管理测试用例,那么我们也必须先制定一个模板,这个模板是根据公司或者自身后期自动化测试框架设定而定义的。
现在我给大家一个参考模板,具体如下图所示:

不同的项目,可以自定义额外的新增列或者删除某些列。
——————————————
❷实现测试用例中数据读取操作
——————————————
声明一个模块Read_TestCase.py,该模块主要实现该测试用例的数据读取操作,具体代码如下:
#-*- coding:utf-8 -*-##-------------------------------------------------------------------------#ProjectName: Python2020#FileName: Read_TestCase.py#Author: mutou#Date: 2020/8/1 16:15#Description:实现测试用例读取操作并完成代码封装,要将excel中的每行每列进行提取出来#--------------------------------------------------------------------------import openpyxlfrom AutoInterFaceFrame.Data_Layer.EXCEL_CONSTANT import *from AutoInterFaceFrame.Data_Layer.From_File.Read_Yaml import ReadYamlfrom AutoInterFaceFrame.Common_Layer.PATH_CONSTANTS import EXCEL_PATH,EXPECT_PATH,PARAMS_PATHclass ReadTestCase(object): def __init__(self): #获取操作excel的对象,需要传入execl文件所在路径 self.read_excel=openpyxl.load_workbook(EXCEL_PATH) def get_cell_value(self,column,sheet_name,row): return self.read_excel[sheet_name][column+str(row)].value #获取到请求的url、请求的参数、请求的方法 #分析发现获取一个单元格要求由行与列所构成,但是如果两个都变动那么维护或者代码实现过于复杂,所以我们就 #列固定,行不固定,列就会设置为常量 def get_url(self,sheet_name,row): return self.get_cell_value(CASE_URL,sheet_name,row) #获取到excel中的方法 def get_method(self,sheet_name,row): return self.get_cell_value(CASE_METHOD,sheet_name,row) #获取到excel中的参数 def get_params(self,sheet_name,row): return self.get_cell_value(CASE_PARAMS,sheet_name,row).split(":") #获取excel中的最大行 def get_max_row(self,sheet_name): return self.read_excel[sheet_name].max_row #直接调用sheet对象的max_row属性 #获取是否mouck的值 def get_ismock(self,sheet_name,row): return self.get_cell_value(CASE_MOCK,sheet_name,row) #获取预期结果的值 def get_expect(self, sheet_name, row): return self.get_cell_value(CASE_EXPECT, sheet_name, row).split(":") if __name__ == '__main__': read=ReadTestCase() for i in range(2,read.get_max_row("Sheet1")+1): print(read.get_method("Sheet1",i),read.get_url("Sheet1",i),read.get_params("Sheet1",i))上面代码执行后输出结果:
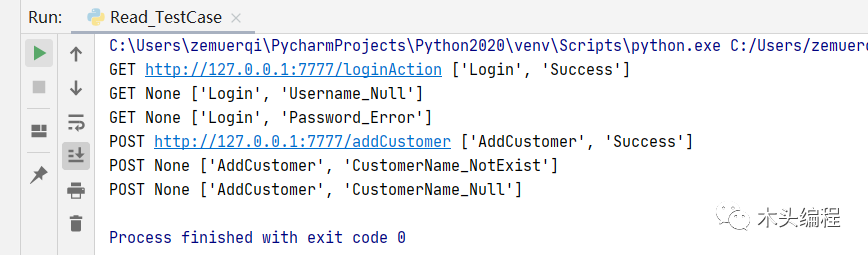
——————————————
❸Excel合并单元格数据处理
——————————————
我们分析会发现合并单元格的数据只能够取到第一个数据,合并的其他单元格的数据都是None值,所以我们需要自定义方法完成数据的提取操作。
首先,我们可以通过sheet对象进行调用merged_cells.range(官网给出的属性时merged_cell_range,但是执行后会警告该属性后期会被舍去,已经被merged_cells.range方法给替代)对象进行获取到合并单元格对象。
if __name__ == '__main__': read=ReadTestCase() for cellrange in read.read_excel["Sheet1"].merged_cells.ranges: print(cellrange)输出结果如下:
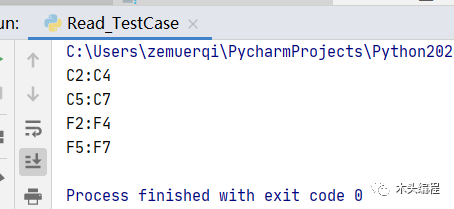
也就是能够读取到整个sheet中的所有合并单元格的范围值。
那么下面我们可以思考了,要是我们能够将所有合并单元格的值全部提取出来,并且以字典的形式显示的话(这个字典应该显示为:
{"C2":["C2","C3","C4"],"C5":["C5","C6","C7"].....}),那么后期只需要判定那个单元格是否处于这些值当中,如果处于则默认取第一个单元格的值即可,如果不处于则取当前单元格本身的值。这就是我们需要实现的思路。
所以我们可以在当前类中声明一个方法完成这个格式的处理操作,具体实现代码如下:
def get_merge_cells(self): list_cell = [] dict_cell = {} for cellrange in self.read_excel["Sheet1"].merged_cells.ranges: # 获取到excel中的所有合并单元格对象 # 想要的格式:{"C2":["C2","C3","C4"],"C5":["C5","C6","C7"]} key = cellrange.coord.split(":")[0] # 合并单元格的coord的形式就是 开始的单元格形式:结束的单元格形式 # 获取每个cellrange的行 rows = len([value for value in cellrange.rows]) start_row = int(key[1:]) # 定义一个开始行 for row in range(start_row, start_row + rows): list_cell.append(key[0] + str(row)) dict_cell.update({key: list_cell}) # 每个cellrange存储一个list,那么没存储完之后要将list清空 list_cell = [] return dict_cell上述代码核心步骤都有注释说明,大家应该能够理解吧~~~
既然我们都已经提取到所有单元格的数据了,现在我们就只需要在get_cell_value方法中添加判定即可,具体添加的方法如下:
def get_cell_value(self,column,sheet_name,row): cell_coord=column+str(row) for key,value in self.get_merge_cells().items(): if cell_coord in value: return self.read_excel[sheet_name][key].value #如果传入的单元格形式是在我合并单元格的值中的话,那么我直接返回键的值即可 return self.read_excel[sheet_name][column+str(row)].value此时进行执行main方法后,执行结果如下:
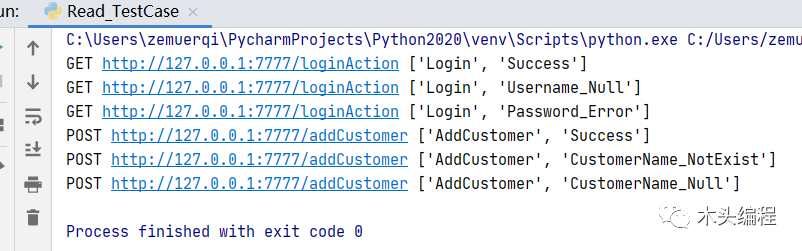
也就是我们上面完美解决了合并单元格取值为None的情况了。当然每个人应该拥有自己的解决思路,上面只是一种参考。
——————————————
❹常量声明
——————————————
因为一个单元格是由行与列所构成的,才能够获取具体的单元格的值。而又必须提取每行的单元格的值,所以我们可以将列进行固定,即将其设置为常量。我们就会新建一个模块:EXCEL_CONSTANT.py#-*- coding:utf-8 -*-##-------------------------------------------------------------------------#ProjectName: Python2020#FileName: CONSTANT.py#Author: mutou#Date: 2020/8/1 16:35#Description:该文件为常量文件#--------------------------------------------------------------------------#设置列的常量CASE_ID="A"CASE_NAME="B"CASE_MODULE="C"CASE_PRECONDITION="D"CASE_METHOD="E"CASE_URL="F"CASE_PARAMS="G"CASE_EXPECT="H"CASE_ACTUAL="I"CASE_MOCK="J"例如:创建另外一层:Common_Layer公共层,专门处理配置信息或者公共操作。
新建一个ini配置文件,具体数据如下:
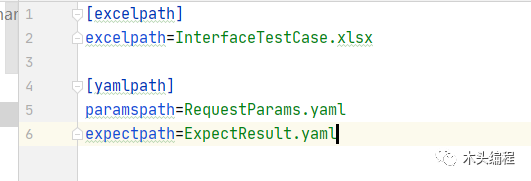
后期我们改变yaml和excel文件的名称只需要修改该配置文件即可,不需要额外的去看具体的代码了。
然后再声明一个读取ini的模块:Read_Data_Ini.py,具体代码如下
#-*- coding:utf-8 -*-##-------------------------------------------------------------------------#ProjectName: Python2020#FileName: Read_Data_Ini.py#Author: mutou#Date: 2020/8/2 15:25#Description:#--------------------------------------------------------------------------#完成Ini的配置文件操作import osimport configparserBASE_DIR=os.path.dirname(os.path.abspath(__file__))class ReadDataIni(object): def __init__(self): self.config=configparser.ConfigParser() with open(os.path.join(BASE_DIR,"data.ini")) as fp: self.config.read_file(fp) def __call__(self,section,option): return self.config.get(section,option)if __name__ == '__main__': read=ReadDataIni() print(read("excelpath","excelpath"))再声明一个PATH_CONSTATANS.py模块用于进行获取EXCEL和YAML等文件的绝对路径,具体代码如下:
#-*- coding:utf-8 -*-##-------------------------------------------------------------------------#ProjectName: Python2020#FileName: PATH_CONSTANTS.py#Author: mutou#Date: 2020/8/2 15:28#Description:#--------------------------------------------------------------------------import osfrom AutoInterFaceFrame.Data_Layer.From_File.Data_Dir.PATH import FROM_FILE_BASE_DIRfrom AutoInterFaceFrame.Common_Layer.Read_Data_Ini import ReadDataIni#获取Excel文件所在的路径EXCEL_PATH=os.path.join(FROM_FILE_BASE_DIR,ReadDataIni()("excelpath","excelpath"))#获取YAML文件所在的路径PARAMS_PATH=os.path.join(FROM_FILE_BASE_DIR,ReadDataIni()("yamlpath","paramspath"))EXPECT_PATH=os.path.join(FROM_FILE_BASE_DIR,ReadDataIni()("yamlpath","expectpath"))# print(EXCEL_PATH)——————————————
❺完成Excel中的参数和预期结果映射操作
——————————————
我们会发现上面取出的请求参数的结果是一个列表。首先参数的形式是我们设定好的,表示格式是:模块名:具体用例名的形式进行存储在yaml中。例如:yaml文件的数据显示如下:

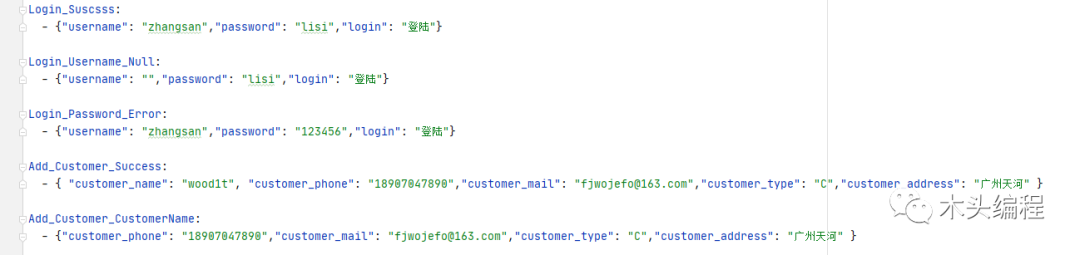
所以这个格式也是根据你们自己框架的实现进行提前定义好。
此时我们会声明一个新的模块:Read_Yaml.py
具体实现代码如下:
#-*- coding:utf-8 -*-##-------------------------------------------------------------------------#ProjectName: Python2020#FileName: Read_RequestParams.py#Author: mutou#Date: 2020/8/1 16:31#Description:主要完成的是接口所需要的参数提取的代码封装#--------------------------------------------------------------------------import yamlfrom AutoInterFaceFrame.Common_Layer.PATH_CONSTANTS import PARAMS_PATH,EXPECT_PATHclass ReadYaml(object): def __call__(self,yamlpath,parent,child): #请求参数会存储到的yaml中,如果预期结果也是使用yaml存储的话,那么该模块不能够单纯的只能够操作参数的形式,就必须合并一个模块操作 #如果说将预期结果存储到json中那就没关系 with open(yamlpath,encoding="utf-8") as fp: self.read_yaml=yaml.safe_load(fp) for value in self.read_yaml[parent]: for key, value in value.items(): if key == child: return valueif __name__ == '__main__': read=ReadYaml() print(read(PARAMS_PATH,"Login","Success"))输出结果如下:
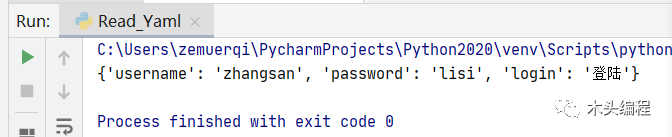
这个模块中我直接声明了一个call方法,相比以前有所改善,因为我们发现我们要读取yaml文件数据,直接可以返回结果值,那么就没必要声明普通函数以及初始化方法,我就声明一个call方法创建对象的时候直接调用即可。
首先我们从excel中提取到的数据是父节点:子节点,所以我们需要提取父节点得到的数据进行根据子节点提取数据。
这样我们也很好的完成了excel与yaml之间的数据映射操作了。
生活不易,还请小伙伴多多支持 ,顺手给小编加个鸡腿,万分感谢~~~
,顺手给小编加个鸡腿,万分感谢~~~
END
— — — — — — — — — — — — — 
更多信息,扫码关注我们哦!















 1866
1866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









