





学习C语言,我们都听过堆(heap)和栈(stack)的概念。需要注意的是:有些地方“堆栈”这个词特指的是栈,而不是堆和栈。命名约定:本文中堆栈一次出现的地方,指的是两种东西,而非一种。
在数据结构中,我们也听过栈和堆这两种数据结构,当然和我本文要讲的东西是不同的概念。不过数据结构中的栈(算法、数学意义上的一种抽象),和本文中的栈(实际存在的存储区)有一共同之处就是FILO —— 先入后出。但是数据结构中的堆和我们本文中的堆则是毫不相干。
无图言卵
注意,这里指的都是虚拟内存空间,并不是实际的物理内存布局。每一个进程都有自己的虚拟内存空间,也就是说我们程序中指针所表示的地址实际是虚拟地址,而不是物理地址。
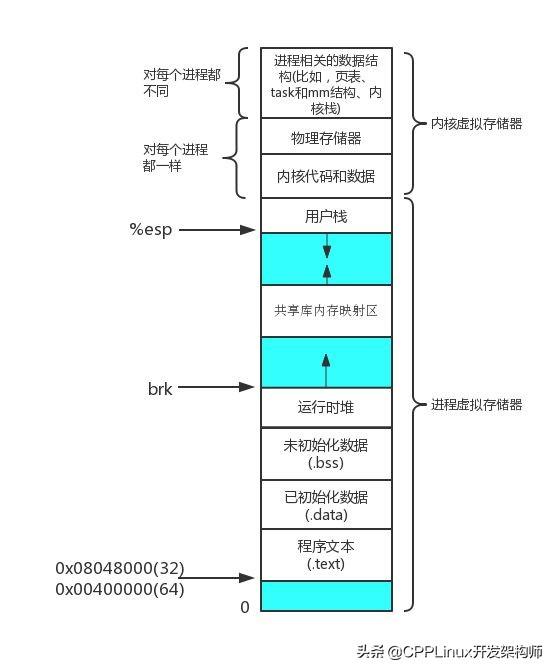
增长方式
所谓地址增长方式,是指堆或栈在分配内存的时候,其分得的内存空间的地址的增长方式。堆的地址增长方式是从低到高的,而栈的地址增长方式是从高到低的。(在说这句话的时候,要明确的一点就是这是指的x86系统,并非所有架构的系统都如此)
之所以它们会呈现出相反的两种地址增长方式是有其历史原因的:
早期的机器上内存的大小十分有限,如果堆和栈使用相同的地址增长方式(比如,都是从低到高),假设,一段内存空间的起始位置(先忽略其他段)设置为堆的起始地址,那么栈的起始地址必然在这段内存空间的中间某处,这个起始点如果选择得太靠后,则可能导致栈的内存大小不够,太靠前则会导致堆在分配内存的时候,可能与栈地址冲突。这时x86系统的设计师们,巧妙地将栈的起始位置定于内存空间的另一端,而其地址增长方式也是和堆相反的从高到低,这样从一定程度上,减轻了堆栈内存地址冲突或栈空间不足的可能性。就好比两个小伙伴在同一本笔记本上记笔记,两个人分别从笔记本的首页和尾页开始写,其笔记冲突的概率大大减小。
栈
函数栈
栈与函数有莫大的关系。简单说来,我们在函数中声明的任何局部变量(非静态)都是在栈中分配的(编译期间完成)。并且函数的参数,以及返回值也是依赖于栈。
为了深入地探讨这些概念,我们需要从汇编角度来展开研究。在使用gcc编译的时候,-S选项可以生成汇编代码。但此时生成的汇编代码是AT&T风格的,我们可以用-masm=intel生成intel风格的汇编。比如:gcc -S -masm=intel hello.c 这时就会生成汇编文件hello.s。请注意我们此时探讨的真相都是不开编译器优化选项的,因为如果开了编译器优化选项,那么其汇编行为往往已经完全不是我们代码本来的执行细节了。(编译器保证的是最终一致性,为了优化可能会改变我们的程序的细节)
变量
看一个简单的例子:
int main(){ int a; int b = 1; int c = 2;}其通过gcc -S -masm=intel汇编之后的汇编代码主要部分如下,注意不同版本的gcc编译器,不同位数的操作系统(32位或64位)其汇编代码可能不同,但大致的意思相同。
main:.LFB0:.cfi_startprocpushrbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movrbp, rsp.cfi_def_cfa_register 6movDWORD PTR [rbp-8], 1movDWORD PTR [rbp-4], 2poprbp.cfi_def_cfa 7, 8ret.cfi_endproc可以忽略掉其中点号. 开头的语句。再看一遍:
main:.LFB0:pushrbpmovrbp, rspmovDWORD PTR [rbp-8], 1movDWORD PTR [rbp-4], 2poprbpret因为我是64位系统,所以汇编代码中的寄存器都是r打头的(rbp,rsp)64位寄存器。x86架构(通常是32位系统)是e打头的(ebp,esp)。以下涉及到寄存器时,我通常会省略其前缀,而直接用bp和sp来称呼。bp是基址寄存器,sp是栈顶指针寄存器(sp的位置,是我们实际能使用的栈的大小)。
请自行区分操作系统位数和cpu架构位数的区别。x64(x86-64),x86是CPU架构。如果你是x64的CPU装了32位系统,那么也不会使用到x64的寄存器(比如r8d),或者不能完整使用x64CPU的寄存器,比如rax。你只能使用该寄存器的一半:eax
首先将bp入栈(push rbp),然后将当前sp位置存取bp(mov rbp, rsp)。这两步是通用操作。下面是重点。
给变量分配空间,可以看到只有两个赋值语句,说明我们的int a因为没有初始化,所以实际不会被分配空间。
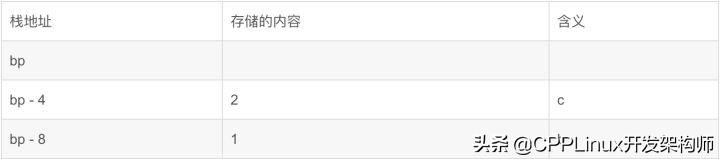
请注意下面(低地址)是栈顶。可以看到c在高地址,b在低地址。这与变量的初始化顺序相反。(如果你开优化选项-O来观察的话,你会发现汇编代码里什么都没有做,这是因为声明的变量b,c虽然被初始化了,但是后续并没有被调用,所以编译器在优化的时候,就什么都不做了。所以再次提醒请不要开编译器优化选项来研究本文的内容,本文不是讨论编译器优化原理的,因为举得例子过于简单,可能就被编译器优化抹掉了)
再验证一下,变量被分配的栈位置是否和变量初始化顺序相反:
int main(){ int a; int b = 1; int c = 2; a = 0;}其栈内存布局为:
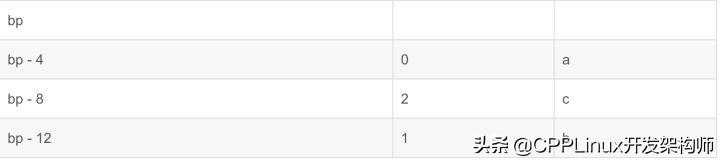
如果是数组的初始化,则每个数组元素分配的栈地址,与其初始化顺序就没有关系了。下标越大的地址越高。比如:int a[4];.....。那么a[0]是数组中栈地址最低的元素,a[3]是地址最高的元素。这里我就不一一演示了,大家可以自己写个demo,汇编一下看看。。其实很好里面,数组的地址位置与其下标的关系一定要严格遵守,这样才方便随机访问(通过下标直接计算偏移)。要注意的是,a[0]在最低的地址。
参数
面试的时候可能出遇到以下类型的题目:
int main(){ int a = 1; int b = 2; printf("%d,%d













 3415
3415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









