





一.模块
首先,我们先看一个老生常谈的问题,什么是模块,模块就是一个包含了python定义和声明的文件,文件名就是模块的名字加上.py后缀,欢聚话说我们目前写的所有的py文件都可以看成是一个模块但是我们import加载的模块一共分成四个通用类别:
1. 使用pyhton编写的py文件
2. 已被变异为共享库或者DLL或C或者C++的扩展
3. 包好一组模块的包.
4. 使用c编写并连接到python解释器的内置模块
为什么要使用模块? 为了我们写的代码可以重用,不至于把所有的代码都写在一个文件内. 当项目规模比较小的时候,完全可以使用一个py搞定整个项目的开发,但是如果是一个非常庞大的项目. 此时就必须要把相关的功能进行分离,以便我们的日常维护,以及新项目的开发.
如何使用模块? 我们已用过很多模块了,导入模块有两种方式
1. import 模块
2. from xxx import xxxx
python开发IT技术交流群:887934385
二.import
首先我们先看import, 在使用import的时候, 我们先创建一个yitian.py. 在该文件中创建一些武林前辈和一些打斗场景, 代码如下:
print("片头曲. 啊! 啊~ 啊! 啊. 啊啊啊啊啊啊啊...")
main_person_man = "张无忌"
main_person_woman = "赵敏"
low_person_man_one = "成昆"
low_person_man_two = "周芷若"
def fight_on_light_top():
print("光明顶大战", main_person_man, "破坏了", low_person_man_one, "的大阴谋")
def fight_in_shaolin():
print("少林寺大战", main_person_man, "破坏了", low_person_man_two, "的大阴
谋")接下来,金庸上场
import yitian
print(yitian.main_person_man) # 使用模块中定义好的名字
print(yitian.low_person_man_one)
yitian.fight_in_shaolin() # 调用模块中的函数
yitian.fight_on_light_top()此时我们在金庸模块中引入了yitian模块.
在Python中模块是不能够重复导入的,当重复导入模块时,系统会根据sys.modules来判断该模块是否已经导入了,如果已经导入,则不会重复导入
import sys
print(sys.modules.keys()) # 查看导入的模块.
import yitian # 导入模块. 此时会默认执行该模块中的代码
import yitian # 该模块已经导入过了,不会重复执行代码
import yitian
import yitian
import yitian
import yitian导入模块的时候都做了些什么? 首先,在导入模块的一瞬间,python解释器会先通过sys.modules来判断该模块是否已经导入了该模块,如果已经导入了则不再导入,如果该模块还未导入过,则系统会做三件事.
1. 为导入的模块创立新的名称空间
2. 在新创建的名称空间中运行该模块中的代码
3. 创建模块的名字,并使用该名称作为该模块在当前模块中引用的名字.
我们可以使用globals来查看模块的名称空间
print(globals())
打印结果:
{‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘__package__‘: None,
‘__loader__‘: <_frozen_importlib_external.SourceFileLoader object at
0x10bbcf438>, ‘__spec__‘: None, ‘__annotations__‘: {}, ‘__builtins__‘:
<module ‘builtins‘ (built-in)>, ‘__file__‘:
‘/Users/sylar/PycharmProjects/oldboy/模块/模块/?庸.py‘, ‘__cached__‘: None,
‘yitian‘: <module ‘yitian‘ from ‘/Users/sylar/PycharmProjects/oldboy/模块/模
块/yitian.py‘>, ‘sys‘: <module ‘sys‘ (built-in)>}注意,由于模块在导入的时候会创建其自己的名称空间,所以我们在使用模块中的变量的时候一般是不会产生冲突的.
import yitian
main_person_man = "胡一菲"
def fight_in_shaolin():
print(main_person_man, "大战曾小贤")
print(yitian.main_person_man) # 张无忌
print(main_person_man) # 胡一菲
yitian.fight_in_shaolin() # 倚天屠龙记中的
fight_in_shaolin() # 自己的
注意,在模块中使用global,我们之前说global表示把全局的内容引入到局部,但是这个全局指的是py文件,换句话说,global指向的是模块内部,并不会改变外部模块的内容
模块 yitian 中:
print("片头曲. 啊! 啊~ 啊! 啊. 啊啊啊啊啊啊啊...")
main_person_man = "张无忌"
main_person_woman = "赵敏"
low_person_man_one = "成昆"
low_person_man_two = "周芷若"
def fight_on_light_top():
print("光明顶大战", main_person_man, "破坏了", low_person_man_one, "的大阴谋")
def fight_in_shaolin():
global low_person_man_two # 注意看, 此时的global是当前模块. 并不会影响
其他模块
low_person_man_two = "战五渣"
print("少林寺大战", main_person_man, "破坏了", low_person_man_two, "的大阴谋")
调用方:
import yitian
low_person_man_two = "刘海柱"
yitian.fight_in_shaolin()
print(yitian.low_person_man_two) # 战五渣
print(low_person_man_two) # 刘海柱. 并没有改变当前模块中的内容. 所以模块内部的
global只是用于模块内部特别特别要注意,如果我们在不同的模块中引入了同一个模块,并且在某一个模块中改变了被引入模块中的全局变量,则其他模块看到的值也跟着变,原因是python的模块只会引入一次,大家共享同一个名称空间
金庸前辈:
import yitian
yitian.main_person_man = "灭绝师太"
金庸二号:
import yitian
import 金庸前辈
print(yitian.main_person_man) # 灭绝师太. 上述问题出现的原因:
1. 大家共享同一个模块的名称空间.
2. 在金庸前辈里改变了主?的名字
如何解决呢?
首先, 我们不能去改python,因为python的规则不是我们定的,只能想办法不要改变主?的名字,但是在金庸里我就有这样的需求,那此时就出现了,在金庸被执行的时候要执行的代码,在金庸被别人导入的时候我们不想执行这些代码,此时我们就要利用一下__name__这个内置变量了. 在Python中,每个模块都有自己的__name__ ,但是这个__name__的值是不定的,当我们把一个模块作为程序运行的入口时,此时该模块的__name__是"__main__" , 而如果我们把模块导入时,此时模块内部的__name__就是该模块自身的名字
金庸前辈:
print(__name__)
# 此时如果运行该文件,则__name__是__main__
金庸前辈二号:
import 金庸前辈
#此时打印的结果是"金庸前辈"我们可以利用这个特性来控制模块内哪些代码是在被加载的时候就运行的,哪些是在模块被别人导入的时候就要执行的,也可以屏蔽掉一些不希望别人导入就运行的代码,尤其是测试代码.
if __name__ == ‘__main__‘:
yitian.main_person_man = "灭绝师太" # 此时, 只有从该模块作为入口运行的时候才
会把main_person_man设置成灭绝师太
print("哇哈哈哈哈哈") # 只有运行该模块才会打印,import的时候是不会执行这里的代
码的我们还可以对导入的模块进行重新命名:
import yitian as yt # 导入yitian. 但是名字被重新命名成了yt. 就好比变量赋值一样.
a = 1 b = a
yt.fight_in_shaolin() # 此时可以正常运行
# yitian.fight_in_shaolin() # 此时程序报错. 因为引入的yitian被重命名成了yt
print(globals())
{‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘__package__‘: None,
‘__loader__‘: <_frozen_importlib_external.SourceFileLoader object at
0x103209438>, ‘__spec__‘: None, ‘__annotations__‘: {}, ‘__builtins__‘:
<module ‘builtins‘ (built-in)>, ‘__file__‘:
‘/Users/sylar/PycharmProjects/oldboy/模块/模块/金庸.py‘, ‘__cached__‘: None,
‘yt‘: <module ‘yitian‘ from ‘/Users/sylar/PycharmProjects/oldboy/模块/模
块/yitian.py‘>}一次可以引入多个模块
import time, random, json, yitian-----------------------------------
import time, random, json, yitian =====================
from yitian import fight_in_shaolin
fight_in_shaolin()此时是可以正常运行的,但是我们省略了之前的模块.函数() 直接函数()就可以执行了, 并且from语句也支持一行语句导入多个内容
from yitian import fight_in_shaolin, fight_on_light_top, main_person_man
fight_in_shaolin()
fight_on_light_top()
print(main_person_man)同样支持as
from yitian import fight_in_shaolin, fight_on_light_top, main_person_man as
big_lao
fight_in_shaolin()
fight_on_light_top()
print(big_lao)最后看一下from的坑,当我们从一个模块中引入一个变量的时候,如果当前文件中出现了重名的变量时,会覆盖掉模块引入的那个变量.
from yitian import main_person_man
main_person_man = "超级大灭绝"
print(main_person_man)所以,不要重名,切记,不要重名! 不仅仅是变量名不要重复,我们自己创建的py文件的名字不要和系统内置的模块重名,否则引入的模块都是python内置的模块. 切记, 切记.
我们现在知道可以使用import和from xxx import xxx来导入一个模块中的内容,那有一种特殊的写法: from xxx import * 我们说此时是把模块中的所有内容都导入, 注意,如果模块中没有写出__all__ 则默认所有内容都导入,如果写了__all__ 此时导入的内容就是在__all__列表中列出来的所有名字.
# haha.py
__all__ = ["money", "chi"]
money = 100
def chi():
print("我是吃")
def he():
print("我是呵呵")
# test.py
from haha import *
chi()
print(money)
# he() # 报错四.包
包是一种通过 ‘.模块名‘来组织python模块名称空间的方式,那什么样的东西是包呢? 我们创建的每个文件夹都可以被称之为包,但是我们要注意, 在python2中规定,包内必须存在__init__.py文件,创建包的目的不是为了运行, 而是被导入使用,包只是一种形式而已,包的本质就是一种模块
为何要使用包? 包的本质就是一个文件夹, 那么文件夹唯一的功能就是将文件组织起来,随着功能越写越多, 我们无法将所有功能都放在一个文件中, 于是我们使用模块去组织功能随着模块越来越多, 我们就需要用文件夹将模块文件组织起来, 以此来提高程序的结构性和可维护性
首先, 我们先创建一些包,用来作为接下来的学习,包很好创建,只要是一个文件夹, 有__init__.py就可以
import os
os.makedirs(‘glance/api‘)
os.makedirs(‘glance/cmd‘)
os.makedirs(‘glance/db‘)
l = []
l.append(open(‘glance/__init__.py‘,‘w‘))
l.append(open(‘glance/api/__init__.py‘,‘w‘))
l.append(open(‘glance/api/policy.py‘,‘w‘))
l.append(open(‘glance/api/versions.py‘,‘w‘))
l.append(open(‘glance/cmd/__init__.py‘,‘w‘))
l.append(open(‘glance/cmd/manage.py‘,‘w‘))
l.append(open(‘glance/db/__init__.py‘,‘w‘))
l.append(open(‘glance/db/models.py‘,‘w‘))
map(lambda f:f.close() ,l)创建好目录结构
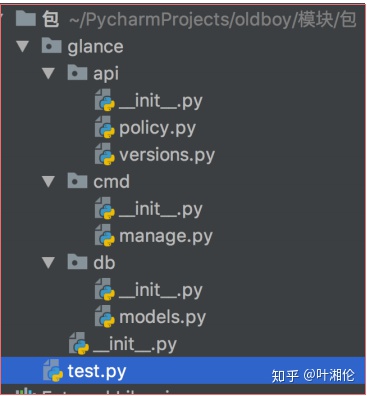
我们接下来给每个文件中添加一些方法:
#policy.py
def get():
print(‘from policy.py‘)
#versions.py
def create_resource(conf):
print(‘from version.py: ‘,conf)
#manage.py
def main():
print(‘from manage.py‘)
#models.py
def register_models(engine):
print(‘from models.py: ‘,engine)
接下来我们在test中使用包中的内容,并且我们导入包的时候可以使用import或者from xxx import xxx这种形式.
首先, 我们看import
import glance.db.models
glance.db.models.register_models(‘mysql‘)没问题, 很简单, 我们还可以使用from xxx import xxx 来导入包内的模块
from glance.api.policy import get
get()也很简单, 但是要注意,from xxx import xxx这种形式, import后面不可以出现"点" 也就是说from a.b import c是ok的,但是 from a import b.c 是错误的
好了, 到目前为止, 简单的包已经可以使用了,那包里的__init__.py是什么鬼? 其实不论我们使用哪种方式导入一个包, 只要是第一次导入包或者是包的任何其他部分, 都会先执行__init__.py文件,这个文件可以是空的,但也可以存放一些初始化的代码. (随意在glance中的__init__.py都可以进行测试)
那我们之前用的from xxx import *还可以用么? 可以,我们要在__init__.py文件中给出_all__来确定* 导入的内容.
print("我是glance的__init__.py文件. ")
x = 10
def hehe():
print("我是呵呵")
def haha():
print("我是哈哈")
__all__ = [‘x‘, "hehe"]test.py
from glance import *
print(x) # OK
hehe() # OK
haha() # 报错. __all__里没有这个鬼东西接下来, 我们来看一下绝对导入和相对导入, 我们的最顶级包glance是写给别人用的,然后再glance包内部也会有彼此之间互相导入的需求, 这时候就有绝对导入和相对导入两种方式了.
1. 绝对导入: 以glance作为起始
2. 相对导入: 用. 或者..作为起始
例如, 我们在glance/api/version.py中使用glance/cmd/manage.py
# 在glance/api/version.py
#绝对导入
from glance.cmd import manage
manage.main()
#相对导入
# 这种情形不可以在versions中启动程序.
# attempted relative import beyond top-level package
from ..cmd import manage
manage.main()测试的时候要注意,python包路径跟运行脚本所在的目录有关系,说白了就是你运行的py文件所在的目录,在python中不允许你运行的程序导包的时候超过当前包的范围(相对导入). 如果使用绝对导入,没有这个问题,换个说法,如果你在包内使用了相对导入,那在使用该包内信息的时候,只能在包外面导入.
接下来我们来看一个大坑,比如,我们想在policy中使用verson中的内容.
# 在policy.py
import versions如果我们程序的入口是policy.py 那此时程序是没有任何问题的,但是如果我们在glance外面import了glance中的policy就会报错 ,原因是如果在外面访问policy的时候,sys.path中的路径就是外面, 所以根本就不能直接找到versions模块,所以一定会报错:
ModuleNotFoundError: No module named ‘versions‘在导包出错的时候,一定要先看sys.path 看一下是否真的能获取到包的信息.
最后, 我们看一下如何单独导入一个包.
# 在test.py中
import glance此时导入的glance什么都做不了,因为在glance中的__init__.py中并没有关于子包的加载,此时我们需要在__init__.py中分别去引入子包中的内容.
1. 使用绝对路径
2. 使用相对路径
包的注意事项:
1. 关于包相关的导入语句也分为import和from xxx import xxx两种, 但无论使用哪种,无论在什么位置, 在导入时都必须遵循一个原则: 凡是在导入时d带点的,点左边都必须是一个包,否则报错,可以带一连串的点, 比如a.b.c
2. import导入文件时,产生名称空间中的名字来源于文件, import 包, 产生的名称空间中的名字同样来源于文件, 即包下的__init__,py, 导入包本质就是在导入该文件
3. 包A和包B下有同名模块也不会冲突, 如A.a和B.a来自两个名称空间
更多精彩文章关注微信公众号【python社区营】
python开发IT技术交流群:887934385
相关问题及免费领取相关资料助理微信:sixstar668















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









