





——神经网络结构
设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定。
神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
——单个神经元的数学模型
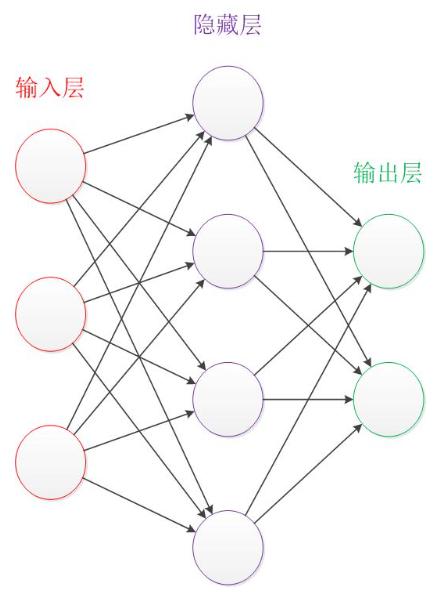
神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。
下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能。
注意中间的箭头线。这些线称为“连接”。每个上有一个“权值”。
——单层神经网络(感知机)
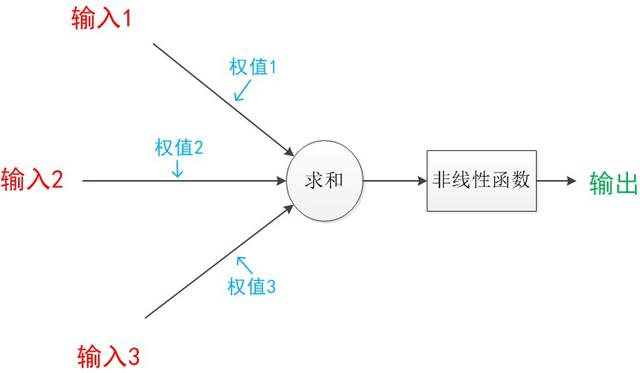
用二维的下标Wx,y来表达一个权值。x代表后一层神经元的序号,y代表前一层神经元的序号。输出计算公式为线性代数方程组。可用矩阵乘法来表达这两个公式。
例如,输入变量a = [a1,a2,a3]T
系数矩阵W = [W1,1 , W1,2, W1,3;
W2,1, W2,2, W2,3]
输出变量z = [z1,z2]T
输出公式可以改写为: z = g(W * a);
——单层神经网络(决策分界)
与神经元模型不同,感知器中的权值是通过训练得到的。因此,根据以前的知识我们知道,感知器类似一个逻辑回归模型,可以做线性分类任务。
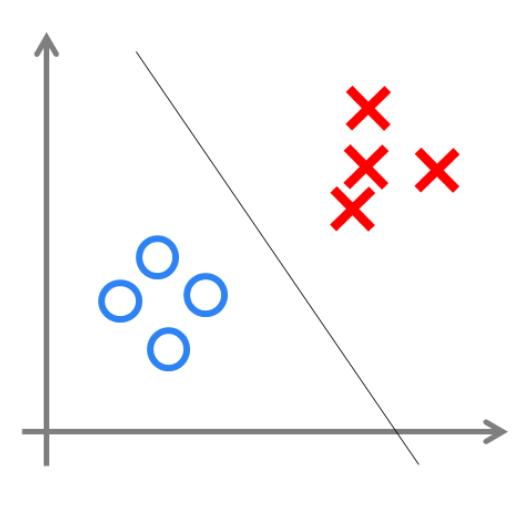
我们可以用决策分界来形象的表达分类的效果。决策分界就是在二维的数据平面中划出一条直线。
当数据的维度是3维的时候,就是划出一个平面,当数据的维度是n维时,就是划出一个n-1维的超平面。
感知器只能做简单的线性分类任务,甚至对XOR(异或)这样的简单分类任务都无法解决。
——两层神经网络(多层感知器)
两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。不过两层神经网络的计算是一个问题,没有一个较好的解法。
反向传播(Backpropagation,BP)算法的提出,解决了两层神经网络所需要的复杂计算量问题。
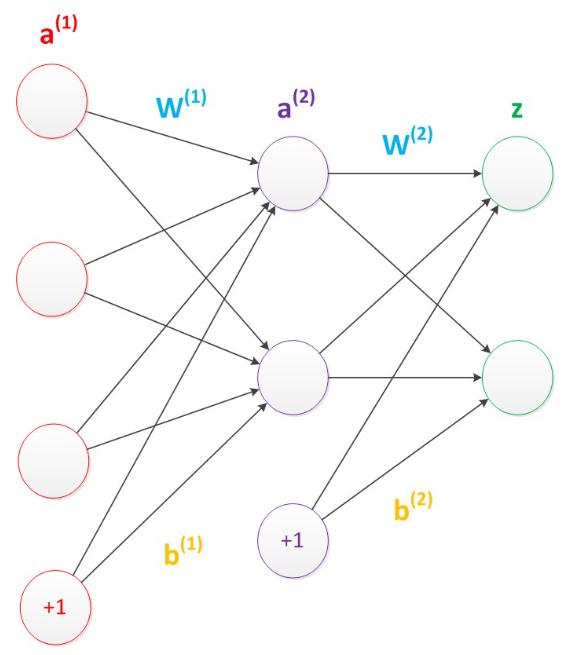
使用矩阵运算来表达是很简洁的,而且也不会受到节点数增多的影响(无论有多少节点参与运算,乘法两端都只有一个变量)。因此神经网络的教程中大量使用矩阵运算来描述。
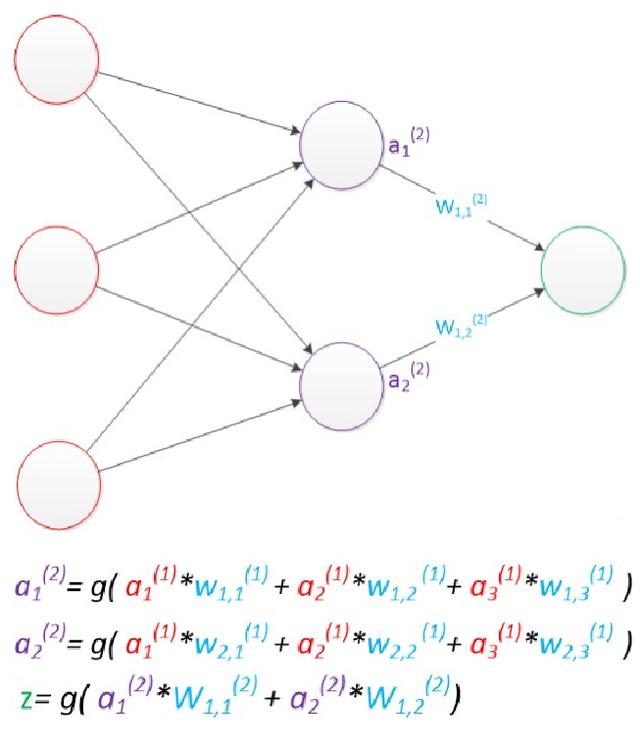
在考虑偏节点的情况下,偏置节点默认存在,它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。一般情况下,我们都不会明确画出偏置节点。
在考虑了偏置以后的一个神经网络的矩阵运算如下:
a(2) = g(W(1) * a(1) + b(1)) ;
z = g(W(2) * a(2) + b(2)) ;
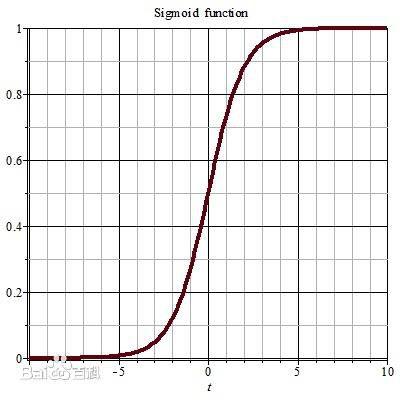
——激活函数(sigmoid)
在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(active function ,又称激励函数)。
如果不用激活函数,每一层节点的输入都是上层输出的线性函数。在两层神经网络中,我们不再使用sgn函数作为激活函数。
神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。
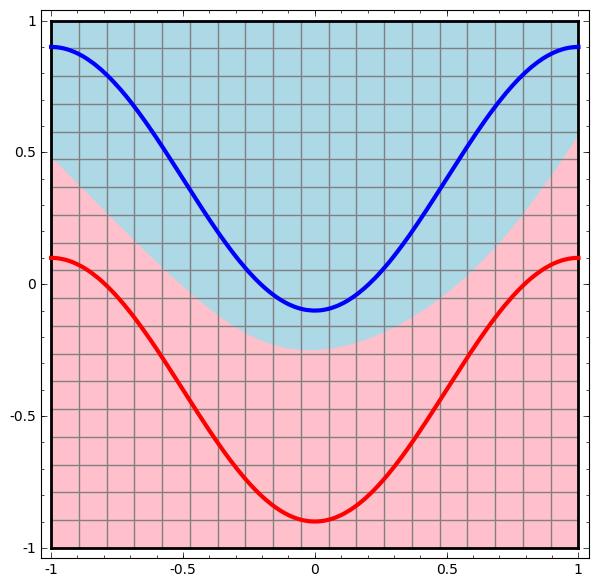
——多层神经网络(决策分界)
红色的线与蓝色的线代表数据。而红色区域和蓝色区域代表由神经网络划开的区域,两者的分界线就是决策分界。
两层神经网络可以做非线性分类的关键——隐藏层。矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换。
隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分。
——损失函数(loss function)
从两层神经网络开始,神经网络的研究人员开始使用机器学习相关的技术进行神经网络的训练。
训练数据中的样本预测目标为yp(z=yp),真实目标为y。那么,定义一个值loss,计算公式:
loss = (yp - y)2
参考文章:
1、 https://blog.csdn.net/illikang/article/details/82019945 神经网络——最易懂最清晰的一篇文章
2、 https://blog.csdn.net/lyl771857509/article/details/78990215 【深度学习】神经网络入门(最通俗的理解神经网络)














 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









