





http 响应码 301 和 302 代表的是什么?有什么区别?
1、什么是301重定向?
301重定向/跳转一般,表示本网页永久性转移到另一个地址。
301是永久性转移(Permanently Moved),SEO常用的招式,会把旧页面的PR等信息转移到新页面;
2、什么是302重定向?
302重定向表示临时性转移(Temporarily Moved),当一个网页URL需要短期变化时使用。
3、301重定向与302重定向的区别
301重定向是永久的重定向,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址。
302重定向是临时的重定向,搜索引擎会抓取新的内容而保留旧的网址。因为服务器返回302代码,搜索引擎认为新的网址只是暂时的。
官方的比较简洁的说明:
301 redirect: 301 代表永久性转移(Permanently Moved)
302 redirect: 302 代表暂时性转移(Temporarily Moved )
301 Moved Permanently
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
302 Found
请求的资源现在临时从不同的 URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
区别:
301 表示被请求 url 永久转移到新的 url;302 表示被请求 url 临时转移到新的 url。
301 搜索引擎会索引新 url 和新 url 页面的内容;302 搜索引擎可能会索引旧 url 和 新 url 的页面内容。
302 的返回码可能被别人利用,劫持你的网址。因为搜索引擎索引他的网址,他返回 302 跳转到你的页面。
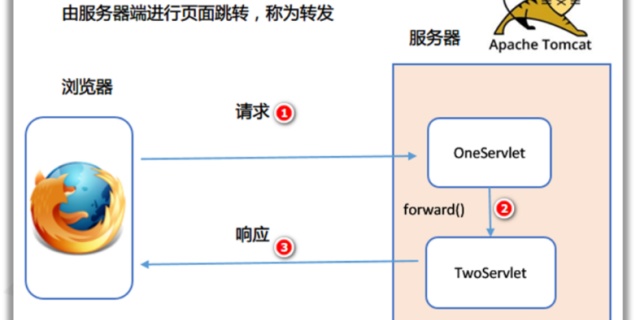
forward 和 redirect 的区别?
- 问:什么时候使用转发,什么时候使用重定向? 如果要保留请求域中的数据,使用转发,否则使用重定向。 以后访问数据库,增删改使用重定向,查询使用转发。
- 问:转发或重定向后续的代码是否还会运行? 无论转发或重定向后续的代码都会执行
两者的区别总结:
1. 从地址栏显示来说:
1)forword是服务器内部的重定向,服务器直接访问目标地址的 url网址,把里面的东西读取出来,但是客户端并不知道,因此用forward的话,客户端浏览器的网址是不会发生变化的。
2)redirect是服务器根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,所以地址栏显示的是新的地址。
2。 从数据共享来说:
1)由于在整个定向的过程中用的是同一个request,因此forward会将request的信息带到被重定向的jsp或者servlet中使用。即可以共享数据
2)redirect不能共享
3. 从运用的地方来说
1)forword 一般用于用户登录的时候,根据角色转发到相应的模块
2) redirect一般用于用户注销登录时返回主页面或者跳转到其他网站
4。 从效率来说:
1)forword效率高,而redirect效率低
5. 从本质来说:
forword转发是服务器上的行为,而redirect重定向是客户端的行为
6. 从请求的次数来说:
forword只有一次请求;而redirect有两次请求,
参考:
forward和redirect的区别是什么?_Python_hongjie_lin-CSDN博客blog.csdn.net
简述 tcp 和 udp的区别?
UDP 是面向无连接的通讯协议,UDP 数据包括目的端口号和源端信息。
优点:UDP 速度快、操作简单、要求系统资源较少,由于通讯不需要连接,可以实现广播发送
缺点:UDP 传送数据前并不与对方建立连接,对接收到的数据也不发送确认信号,发送端不知道数据是否会正确接收,也不重复发送,不可靠。
TCP 是面向连接的通讯协议,通过三次握手建立连接,通讯完成时四次挥手
优点:TCP 在数据传递时,有确认、窗口、重传、阻塞等控制机制,能保证数据正确性,较为可靠。
缺点:TCP 相对于 UDP 速度慢一点,要求系统资源较多。
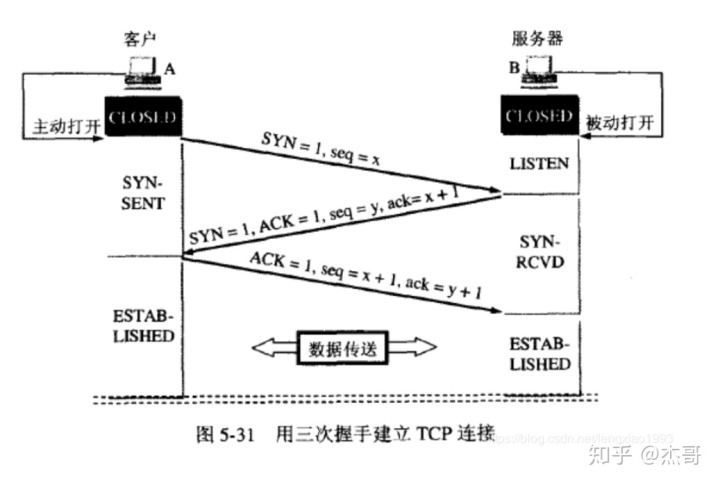
tcp 为什么要三次握手,两次不行吗?为什么?
原因如下:
两次握手只能保证单向连接是畅通的。
Step1 A -> B : 你好,B。
Step2 A <- B : 收到。你好,A。
这样的两次握手过程, A 向 B 打招呼得到了回应,即 A 向 B 发送数据,B 是可以收到的。
但是 B 向 A 打招呼,A 还没有回应,B 没有收到 A 的反馈,无法确保 A 可以收到 B 发送的数据。
只有经过第三次握手,才能确保双向都可以接收到对方的发送的 数据。
Step3 A -> B : 收到,B。
这样 B 才能确定 A 也可以收到 B 发送给 A 的数据。

SYN - 创建一个连接
FIN - 终结一个连接
ACK - 确认接收到的数据

参考:
TCP 为什么三次握手而不是两次握手(正解版)blog.csdn.net

说一下 tcp 粘包是怎么产生的?
1、什么是 tcp 粘包?
发送方发送的多个数据包,到接收方缓冲区首尾相连,粘成一包,被接收。
2、原因
TCP 协议默认使用 Nagle 算法可能会把多个数据包一次发送到接收方。
应用程读取缓存中的数据包的速度小于接收数据包的速度,缓存中的多个数据包会被应用程序当成一个包一次读取。
3、处理方法
发送方使用 TCP_NODELAY 选项来关闭 Nagle 算法
数据包增加开始符和结束,应用程序读取、区分数据包。
在数据包的头部定义整个数据包的长度,应用程序先读取数据包的长度,然后读取整个长度的包字节数据,保证读取的是单个包且完整。
参考:
什么是TCP粘包?怎么解决这个问题_网络_weixin_41047704的博客-CSDN博客blog.csdn.net
OSI 的七层模型都有哪些?
OSI是什么:
OSI是Open System Interconnection的缩写,意为开放式系统互联。国际标准化组织(ISO)制定了OSI模型,该模型定义了不同计算机互联的标准,是设计和描述计算机网络通信的基本框架。OSI模型把网络通信的工作分为7层,分别是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。

get 和 post 请求有哪些区别?
Get请求和post请求区别
在浏览器进行回退操作时,get请求是无害的,而post请求则会重新请求一次
get请求参数是连接在url后面的,而post请求参数是存放在request body内的
get请求因为浏览器对url长度有限制(不同浏览器长度限制不一样)对传参数量有
限制,而post请求因为参数存放在requestbody内所以参数数量没有限制(事实上
get请求也能在requestbody内携带参数,只不过不符合规定,有的浏览器能够获取
到数据,而有的不能)
因为get请求参数暴露在url上,所以安全方面post比get更加安全
get请求浏览器会主动cache,post并不会,除非主动设置
get请求参数会保存在浏览器历史记录内,post请求并不会
get请求只能进行url编码,而post请求可以支持多种编码方式
get请求产生1个tcp数据包,post请求产生2个tcp数据包
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
浏览器在发送get请求时会将header和data一起发送给服务器,服务器返回200状态码,而在发送post请求时,会先将header发送给服务器,服务器返回100,之后再将data发送给服务器,服务器返回200 OK

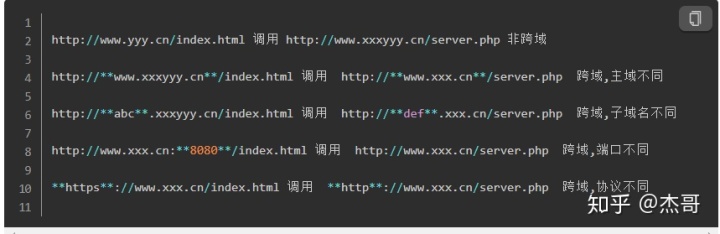
什么是跨域? 如何实现跨域?
首先狭义的同源就是指,域名、协议、端口均为相同。
跨域,是指浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器对JavaScript实施的安全限制。
这里说明一下,无法跨域是浏览器对于用户安全的考虑,如果自己写个没有同源策略的浏览器,完全不用考虑跨域问题了。是浏览器的锅,对。
同源策略限制了一下行为:
Cookie、LocalStorage 和 IndexDB 无法读取
DOM 和 JS 对象无法获取
Ajax请求发送不出去
如何实现跨域请求呢?
1、jsonp
利用了 script 不受同源策略的限制
缺点:只能 get 方式,易受到 XSS攻击
2、CORS(Cross-Origin Resource Sharing),跨域资源共享
当使用XMLHttpRequest发送请求时,如果浏览器发现违反了同源策略就会自动加上一个请求头 origin;
后端在接受到请求后确定响应后会在后端在接受到请求后确定响应后会在 Response Headers 中加入一个属性 Access-Control-Allow-Origin;
浏览器判断响应中的 Access-Control-Allow-Origin 值是否和当前的地址相同,匹配成功后才继续响应处理,否则报错
缺点:忽略 cookie,浏览器版本有一定要求
这种方式分为两种请求:
一种是简单请求,另一种是非简单请求
简单请求跨域:
请求方式为HEAD、POST 或者 GET
非简单请求跨域:
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json
3、代理跨域请求(Nginx)
前端向发送请求,经过代理,请求需要的服务器资源
缺点:需要额外的代理服务器
4、Html5 postMessage 方法
允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本、多窗口、跨域消息传递
缺点:浏览器版本要求,部分浏览器要配置放开跨域限制
5、修改 document.domain 跨子域
相同主域名下的不同子域名资源,设置 document.domain 为 相同的一级域名
缺点:同一一级域名;相同协议;相同端口
6、基于 Html5 websocket 协议
websocket 是 Html5 一种新的协议,基于该协议可以做到浏览器与服务器全双工通信,允许跨域请求
缺点:浏览器一定版本要求,服务器需要支持 websocket 协议
7、document.xxx + iframe
通过 iframe 是浏览器非同源标签,加载内容中转,传到当前页面的属性中
缺点:页面的属性值有大小限制
参考:
什么是跨域?如何实现?www.jianshu.com
说一下 JSONP (JSON+Padding) 实现原理
jsonp跨域是JavaScript设计模式中的一种代理模式。在html页面中通过相应的标签从不同域名下加载静态资源文件是被浏览器允许的(从js中调用不行),所以我们可以通过这个“漏洞”来进行跨域。一般,我们可以动态的创建script标签,再去请求一个带参网址来实现跨域通信。局限是只能get请求。
下面是两种前端实现方式:

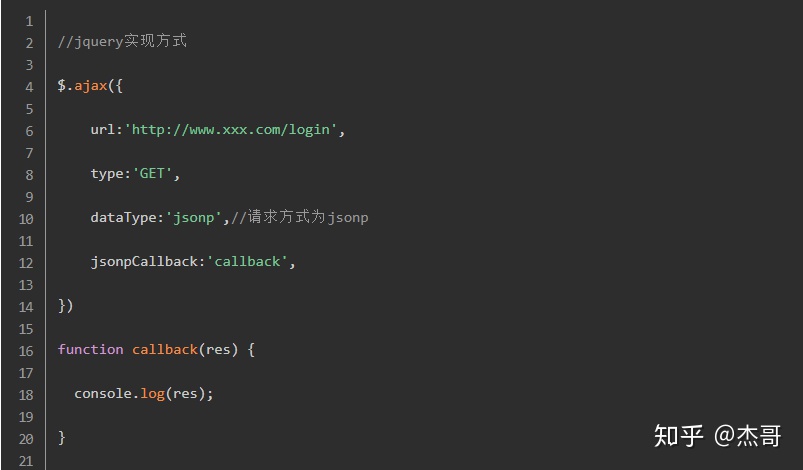
特别注意的是,上面代码里传入的callback参数是服务器传回数据后需要调用的方法,上面代码中方法是callback();
服务器端传回的数据格式应该是callback(数据)
另外有时会出现406错误,这时候就需要在响应头中添加Access-Control-Allow-Origin,值为*,表示的是允许所有域名访问。response.setHeader("Access-Control-Allow-Origin", "*");
Jsonp很好用对吧,但只能get请求。















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









