





接下来我们讨论自底向上的语法分析。自底向上的语法分析过程同样对应于为一个输入串构造语法分析树的过程,只不过是从叶子节点(底部)逐渐向上到达根节点(顶部)。
自底向上分析法的解析力量比自顶向下分析法要强大的多,和自顶向下分析法相比,它可以解析更为复杂、更为广泛的语法。但自底向上分析法的构造过程也复杂的多。分析器构造工具(如 bison )就是将用户定义的语法规则转化成一个自底向上分析器。
看一个自底向上例子:
对于以下文法:
S -> aABe
A -> Abc | b
B -> d对于输入abbcde是怎么样进行自底而上分析的呢?
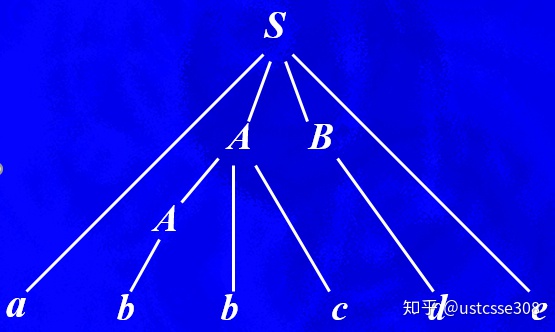
规约是推导的逆过程,因此,自底向上分析的目标是反向构造一个推导过程,这个规约过程对应着以下的最右推导:
再使用下面的文法:
E -> E + T | T
T -> T * F | F
F -> ( E ) | id
对字符串
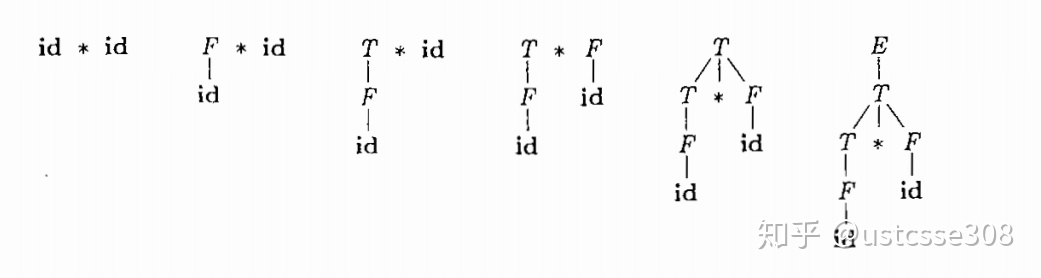
自底向上的语法分析过程可以看成是一个将串
这个过程中,首先发现的是
上面的规约过程对应着下面的推导过程(最右推导):
这里引入一个概念“句柄“,句柄是和某个产生式体匹配的子串,一旦发现句柄,则立刻进行规约,因此形成了最左规约,也对应着最右推导。
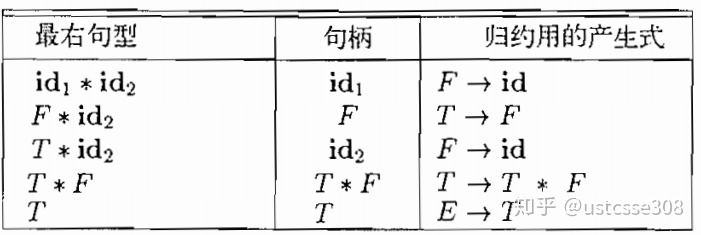
这里的问题是何时进行规约;以及选用哪个产生式进行规约。在上面的例子中,虽然T是产生式E->T的体,但是符号T并不是最右句型
考虑:如果是
练习:
对于文法
- 000111
- 00S11
再看一个例子,体会一下使用栈进行移入-规约的过程。
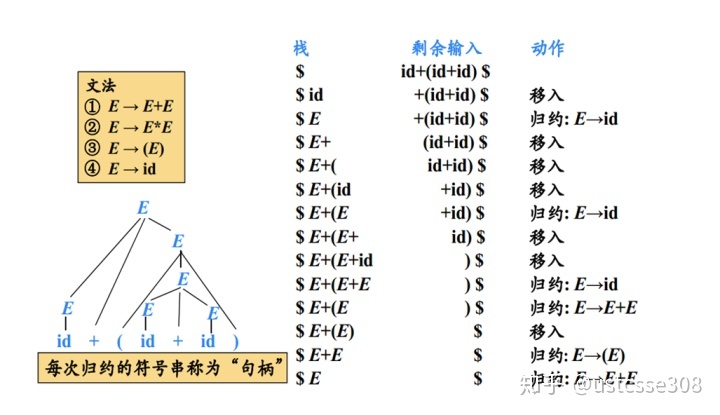
在上面的例子中,处理输入串的时候都是用了移入和规约两个动作,一个移入-规约语法分析器可以采取以下四种可能的动作:
- 移入(shift):降下一个输入符号移到栈的顶端;
- 规约(reduce):被规约的符号串的右端必然是栈顶。语法分析器在栈中确定串的左端,并决定用哪个非终结符号来确定这个串。
- 接收(accept):宣布语法分析过程成功完成。
- 报错(error):发现语法错误,调用错误回复子例程。
通过以上的例子,对自下而上分析应该有一个直观了解。简而言之,对输入进行从左到右的扫描,并在扫描过程中对核某个产生式体相匹配的最右子串进行规约,就可以反向构造出一个最右推导。
这一部分中我们介绍的文法分析是LR,L就表示“从左至右“扫描,R就是反向构造出最右推导。直观地将,只要存在这样一个从左到右扫描的移入-规约语法分析器,总是能够在某文法的最右句型的句柄出现在栈顶时识别出这个句柄,那么这个文法就是LR的。
目前最流行的自底向上文法分析器都是基于LR(
接下来,介绍LR语法分析的基本概念,然后进入最简单的构造移入-规约语法分析器的方法,这个方法称为SLR(简单LR)。虽然现在可以使用Bison等工具自动生成语法分析器,但是理解它的工作原理仍然是有帮助的。在理解SLR之后,将继续介绍规范LR和LALR,它们被用于大多数的LR语法分析器中。
LR语法分析器和LL语法分析器一样,也是表格驱动的。如果我们能够为一个文法构造出语法分析表,那么这个文法就可以成为LR文法(LR Grammar)。直观地讲,只要存在这样一个从左到右扫描的从左到右扫描的移入-规约语法分析器,总是能够在某文法的最右句型的句柄出现时识别出这个句柄,这个语法就是LR的。
LR语法分析技术:
- 几乎所有的程序设计语言构造,只要能够写出该构造的上下文无关文法,就能够构造出识别该构造的LR语法分析器。
- LR语法分析方式是一致的最通用的无回溯移入-规约分析技术。
- LR语法分析器可以在从左到右扫描时尽早检测到错误。
- 可以使用LR方法进行分析的文法类是可以用预测方法或者LL方法进行语法分析的真超集。直观理解,LR(k)是当我们在最右句型中看到某个产生式的右部时,再朝前看k个符号来决定是否进行规约。对于LL(k)文法,只能看该产生式右部推导出的串的前k个符号,来决定是否使用该产生式。
LR方法的主要 缺点是为典型的语言手工构造LR分析器的工作量非常大。
为什么工作量很大呢?
譬如前面我们看到符号T并不是最右句型
我们还可以再看一个例子。对于文法
S -> var IDS : T
IDS -> i | IDS, i
T -> real | int问题:如何分析串
var i1, i2 : real上面这个文法就是变量串的声明,这个问题很简单。可以使用最右推导得出:
S => var IDS : T =>var IDS: real => var IDS, i2 : real => var i1, i2 : real相对应于上面的推导过程,一个自底向上的分析过程如下:
var i1 IDS->i var IDS
var IDS, i2 IDS -> IDS, i var IDS
var IDS : T S -> var IDS : T S但是,我们在分析过程中也可能有这样的疑问:
var i1 IDS->i var IDS
var IDS, i2 IDS -> i var IDS,IDS
这样将i2规约成IDS的话,后面的输入移入完成的时候就没办法规约了。
所以,语法分析器必须知道何时移入,何时规约。移入-规约语法分析器怎么知道何时进行移入,何时进行规约呢?LR分析器通过维护一些状态,这些状态来表明我们在语法分析中所处的位置,从而做出移入-规约决定。
状态是“项”的集合。直观上讲,项表示在分析过程中的给定点上,我们经看到了产生式的哪些部分。形式上来看,文法G的LR(0)项是G的一个产生式再加上一个位于它的体中的某处的点。因此,产生式
- A ->·XYZ
- A ->X·YZ
- A ->XY·Z
- A ->XYZ·
产生式
以上的项表示什么意思呢?
譬如A ->·XYZ就表示,接下来我们希望看到由XYZ推导得到的串;而A ->X·YZ表示我们已经看到了X推导得出的串,接下来我们希望看到由YZ推导得出的串;A ->XYZ·表示我们已经看到了XYZ推导得出的串,接下来可以进行规约了。
对于产生式
S -> BB状态:
S -> ·BB 移入状态
S -> B·B 待约状态
S -> BB· 规约状态使用称为规范LR(0)的项可以集构建一个确定有穷自动机,这个自动机可以做出语法分析决定。这个LR(0)的自动机的每一个状态代表了规范LR(0)集族中的一个项集。
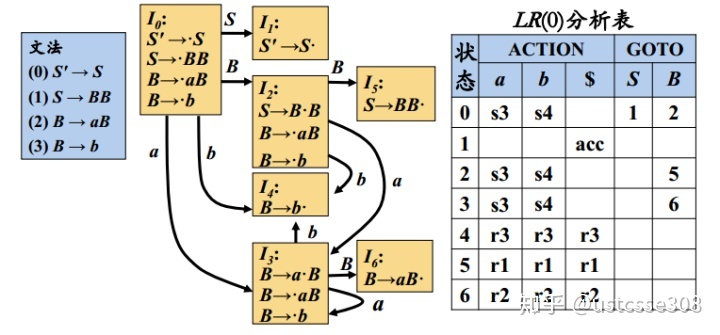
这个分析表比LL分析表更复杂一点,其中,主体部分是ACTION动作表,其中s表示shift,移入;r表示reduce规约。s5表示移入,并且进入状态5;r3表示使用第三个产生式进行规约。和LL不同,这里的非终结符成为了GOTO表的一部分,也即,当状态遇到非终结符时应该进入到什么状态。有了上面的分析表,我们可以对输入串进行分析,譬如对于输入串bb
栈 符号 输入 动作
0 $ bb$ 移入到状态4
04 $b b$ 使用3 B->b进行规约
02 $B b$ 移入到状态4
024 $Bb $ 使用3 B->b进行规约
025 $BB $ 使用1 S ->BB进行规约
01 $S $ 接受这里要注意,在进行规约的时候,要注意将符号和栈中的状态一起弹出;譬如第一次使用B->b进行规约的时候,栈中的状态是04,当b规约成B的时候,4也弹出了;此时相当于栈顶的状态是0,遇到B的时候,进入了状态2。这个结合上面的状态转换图也容易理解。
下面可以再做一个例子aabb。首先可以看一下aabb的最右推导过程。
S->BB->Bb->aBb->aaBb->aabb我们可以看一下,进行LR(0)分析的过程是不是恰好对应着最右推导的逆过程。
具体过程如下:
栈 符号 输入 动作
0 $ aabb$ 移入到状态3
03 $a abb$ 移入到状态3
033 $aa bb$ 移入到状态4
0334 $aab b$ 使用3 B->b进行规约;弹出状态4;进入状态6
0336 $aaB b$ 使用2 B->aB进行规约;弹出状态36;进入状态6
036 $aB b$ 使用2 B->aB进行规约;弹出状态36;进入状态2
02 $B b$ 移入到状态4
024 $Bb $ 使用3 B->b进行规约;弹出状态4;进入状态5
025 $BB $ 使用1 S ->BB进行规约
01 $S $ 接受LR语法分析算法描述如下:

另外,在构建以上自动机的时候,首先定义了一个增广文法G'。增广文法G'就是在文法G中增加了新的开始符号S'和产生式S'->S而得到的文法。引入这个新的产生式的目的是使得文法开始符号仅出现在一个产生式的左边,从而使得分析器只有一个接受状态。从而可以明确地告诉语法分析器何时停止语法分析并执行accept动作。也即,仅当使用规则S'->S进行规约时,输入符号串被接受。
在上图中,也即在状态I1中,当接受$时,可以进入accept动作。整个自动机中,也仅有这一个accept动作。
项集的闭包
接下来考虑下自动机的构造。自动机中的每个状态是项的集合,具体来讲,是等价的项目组成的项目集。
可以想象,产生式右部长度为
在计算每个动作的时候,需要使用Closure函数,也即闭包函数。什么是项集的闭包呢?

也即,首先将I状态中的核心项【除
GOTO函数
返回项目集
算法描述如下:

直观上将,GOTO函数用于定义一个文法的LR(0)自动机中的转换。这个自动机的状态对应于项集,而GOTO(I,X)描述了当输入为X时离开I的转换。
譬如
构造LR(0)自动机的状态集
规范LR(0)项集族(Canonical LR(0) collection)
算法如下:

LR(0)分析表构造算法

从上面的过程中,我们其实可以看到,之所以上面的分析方法叫LR(0),是因为处理输入的过程中它不需要向前看输入符号。LR(0)所做出的所有判断都是基于文法本身的。所以,它相对比较简单,也因此它能够处理的语言很有限,能够使用LR(0)方法分析的文法是LR(0)文法。LR(0)是构造其他LR分析器的基础。
LR(0)的不足是什么呢?下面看一下表达式文法
E -> E + T | T
T -> T * F | F
F -> ( E ) | id 的LR(0)自动机。
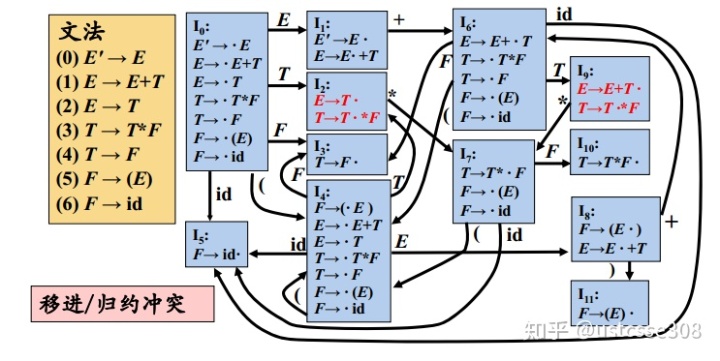
按照LR(0)的算法,在状态
要求对于所有的终结符和$进行规约;而
则要求对 * 进行移入。
可以分析一下,在下一个输入字符是
这里,采用移入的动作更合适。为什么呢?
因为如果采用了归约动作,归约成
也即,在LR(0)中,一旦
一种思路便是,如果
构造SLR分析表的算法如下:

譬如,上面表达式文法
E -> E + T | T
T -> T * F | F
F -> ( E ) | id 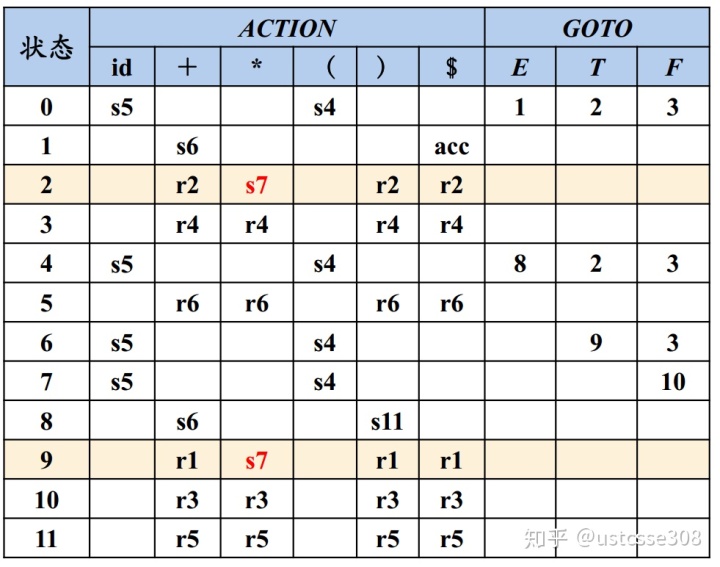
使用这个表就可以对输入进行处理。
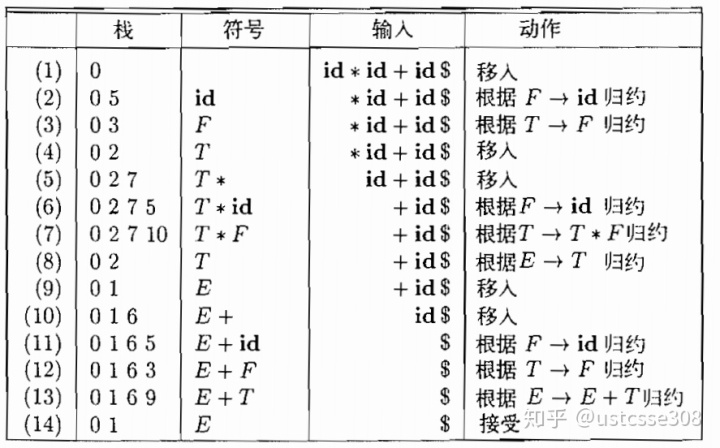
再看一个例子。
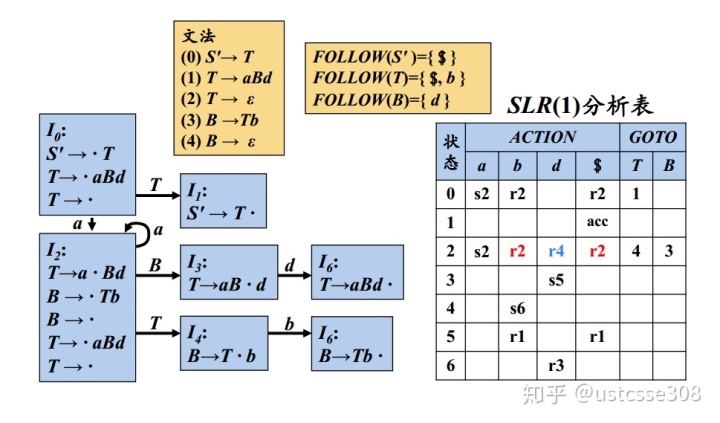
综合上面的过程可以看出,SLR是在LR(0)基础上的一个改进;移入动作仅仅根据产生式便可以得到;规约动作是根据可能的后继符号产生的。【问题在于,一个非终结符号的后继符号可能是由多个不同的产生式产生的;这时相当于是对于该终结符号的所有后继符号,只用一个产生式来进行规约;因此,SLR仍然是一种比较粗糙的做法。】
练习。
为下面的文法的增广文法构造SLR项集,计算这些项集的GOTO函数,给出这个文法的语法分析表。这个文法是SLR文法吗?
首先,构造增广文法:
S’->S
S->SS+
S->SS*
S->a然后构造LR(0)项集:
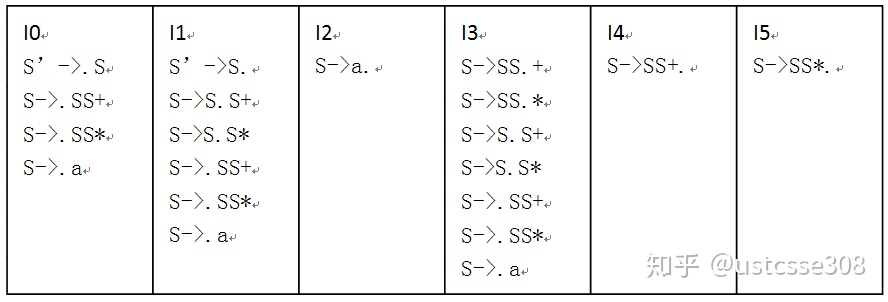
以及GOTO函数:
GOTO(I0,S)=I1 GOTO(I0,a)=I2
GOTO(I1,S)=I3 GOTO(I1,a)=I2 GOTO(I1,$)=acc
GOTO(I3,S)=I3 GOTO(I3,+)=I4 GOTO(I3,*)=I5 GOTO(I3,a)=I2考虑到FOLLOW(S)={+,*,a,$},在状态2、4、5中包含有产生式体结束的项,所以相对应地,在分析表中有对应的规约项。
所以构造语法分析表如下:
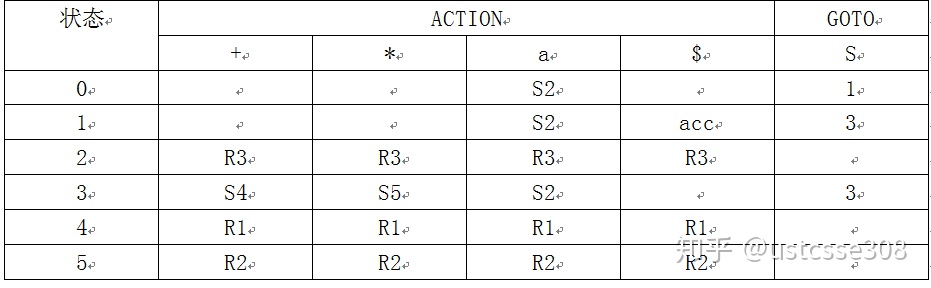
因为在表中不存在冲突,所以,此文法是SLR文法。
使用上述分析表,分析一下输入aa*a+的处理过程。
练习:
- 说明下面的文法
S -> A a A b | B b B a
A -> ε
B -> ε是LL(1)的,但不是SLR(1)的。
【通过这个例子可以体验,SLR不是根据向前看的符号,而是根据FOLLOW集来进行规约,所以引起冲突】
2. 说明下面的文法
S -> S A | A
A -> a是SLR(1)的,但不是LL(1)的。














 4879
4879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









