





Python ast和json模块的区别
Python中ast模块,json模块,都具有处理数据的能力,都常用于解析request()返回的内容。
ast模块:如果需要把一大长串的字符串数据转化为json数据,那么我会第一个想到使用ast模块,因为他比json模块使用更加简单。
data_json = ast.literal_eval(data)json模块:如果 具有单引号形式 data = '{"name":"123", "password":123}' ,则json.loads(data)可以直接处理。但如果具有双引号形式 data = "{'name':'123', 'password':123}" ,则需要把数据转化为单引号形式 data = '{"name":"123", "password":123}' 再使用json.loads方法,还有要注意的是,如果数据中有None,需要先这样 data.replace('None', '""'), 否则直接使用json.loads数据也会一直报错。需要注意的是,json模块有这样两个方法loads,load, 常用loads。这两者的差别百度之。
补充:形如data = '{'name': '123', 'password':123}' 和 data = "{"name":"123", "password":123} " 的字符串本身就是错误的,和JSON格式无关。对于这种和dict有关的字符串,外层用双引则内层用单引号,或者相反,内外不能同时用一种,会报错。可参见第二例,很明显
JSON格式的标准:双引号而非单引号!因此直接json模块解析单引号字符串会报错
JSONDecodeError Expecting property name enclosed in double quotes line 1 column 2 (char 1)首先 JSON 格式数据本身规定字符串必须使用双引号来包裹,而 loads() 方法又没有做这方面的处理,想要解决 BUG 笨点办法就是用双引号替换单引号。当然更好的办法就是使用 ast 模块
import ast
text = "{'name': 'wxnacy'}"
res = ast.literal_eval(text)
print(res) #
输出: {'name': 'wxnacy'}第二例:json.loads()读取字符串报错:json.decoder.JSONDecodeError解决办法
import json
str = """
[{ 'name':'zhang san', 'gender':'male', 'birthday':'1992-01-05'},
{ 'name':'li si', 'gender':'female', 'birthday':'1991-12-13'} ]
"""
print(type(str))
data = json.loads(str)
print(data)
print(type(data))
# 报错str字符串里面的标识字符用了单引号括起来,将其换成双引号后再次运行,则正确。注意:将标识字符的单引号替换为双引号时,需要先将外面的三双引号替换为三单引号
str = '''
[{ "name":"zhang san", "gender":"male", "birthday":"1992-01-05"},
{ "name":"li si", "gender":"female", "birthday":"1991-12-13" }]
'''
print(type(str))
data = json.loads(str)
print(data)
print(type(data))
# 输出
<class 'str'>
[{'name': 'zhang san', 'gender': 'male', 'birthday': '1992-01-05'}, {'name': 'li si', 'gender': 'female', 'birthday': '1991-12-13'}]
<class 'list'>eval和ast.literal_val()的区别
eval函数在Python中做数据类型的转换还是很有用的。它的作用就是把数据还原成它本身或者是能够转化成的数据类型。eval在做计算前并不知道需要转化的内容是不是合法的(安全的)python数据类型。只是在调用函数的时候去计算。如果被计算的内容不是合法的python类型就会抛出异常。ast.literal则会判断需要计算的内容计算后是不是合法的python类型,如果是则进行运算,否则就不进行运算。因此,推荐使用ast.literal_eval
Python3 str.strip([chars]) 方法
Python strip() 方法用于移除字符串头尾指定的字符(无参数时,默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
1、strip() 处理的时候,如果不带参数,默认是清除两边的空白符,例如:/n, /r, /t, ' ')。
2、strip() 带有参数的时候,这个参数可以理解一个要删除的字符的列表,是否会删除的前提是从字符串最开头和最结尾是不是包含要删除的字符,如果有就会继续处理,没有的话是不会删除中间的字符的。
addr = '123@163.com'
addr1 = addr.strip('12')
addr2 = addr.strip('23')
结果分别为:
3@163.com
123@163.com3、注意删除多个字符时:只要头尾有对应其中的某个字符即删除,不考虑顺序,直到遇到第一个不包含在其中的字符为止。示例如下:
str = '123132231213321312==321312213231123132'
print(str.strip('123'))以上代码输出结果为:
==处理dict字典对象的相关语句 可参见<Python dict字典方法完全攻略 >比较全
字典是Python语言中唯一的映射类型。爬虫所获得的JSON内容,多和dict相关
1、Python dict()使用
dic = dict() # 即 dic={}
list1 = [('k1', 12345), ('k2', 1233),('k3','sssssss')]
dic = dict(list1) # 参数是形如此的元组组成的列表
输出:dic = {'k1': 12345, 'k2': 1233, 'k3': 'sssssss'}2、d1.items()/d1.keys()/d1.values()基本使用
a = {'数学': 95, '语文': 89, '英语': 90}
for k in a.keys():
print(k,end=' ') # 获取字典的键的列表
print("n---------------")
for v in a.values():
print(v,end=' ') # 获取字典的值的列表
print("n---------------")
for k,v in a.items(): # 获取字典的键值对的列表
print("key:",k," value:",v)
#输出:
数学 语文 英语
---------------
95 89 90
---------------
key: 数学 value: 95
key: 语文 value: 89
key: 英语 value: 903、Python dict追加数据
# 直接赋予字典对象key和value即可,注意对于已经存在的key,赋予新value值,将会覆盖旧value值
dic = dict() # 即 dic={}
dic['k1']=123 -> dic = {'k1':123}
dic['k2']=1233 -> dic = {'k1':123, 'k2':1233}
dic['k1']=12345 -> dic = {'k1':12345, 'k2':1233}
# 更多的一些不常用方法可见:https://blog.csdn.net/huyangshu87/article/details/526814784、Python中字典合并的四种方法
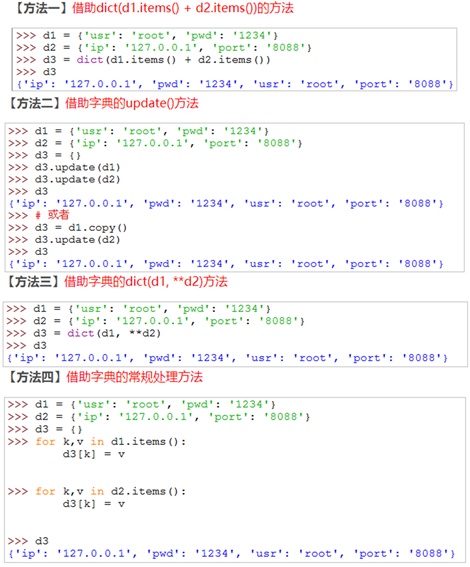
5、判断字典中key是否存在的方法
d = {'name':{},'age':{},'sex':{}}
#打印返回值,其中d.keys()是列出字典所有的key
print(name in d.keys())
#结果返回True
print(name not in d.keys())
#结果返回False
此外还有print(d.has_key('name'))方法,但是属于python2.2之前的方法,不推荐处理list列表对象的相关语句
1、python list 增加元素的三种方法
# append方法
li=['a', 'b']
li.append([2,'d'])
li.append('e')
#输出为:['a', 'b', [2, 'd'], 'e']
# insert 方法
li=['a', 'b']
li.insert(0,"c")
#输出为:['c', 'a', 'b']
# extend方法, 我在写知乎爬虫的时候,这个方法似乎没起作用,不知为什么。采用切片方式插入更加稳妥
li=['a','b']
li.extend([2,'e'])
#输出为:['a', 'b', 2, 'e']
append多用于把元素作为一个整体插入
insert多用于固定位置插入
extend多用于list中多项分别插入注意:与以上方法紧密相关的报错error是AttributeError: 'NoneType' object has no attribute 'append' 。其他list和dict方法类似
list1=[]
m='ssss'
list1 = list1.append(m) # 会报错,正确应使用 list1.append(m)请注意:list1 = list1.append(m) 是不对的,【与之区分的是常用的a+=1】 list1.append(m)执行后的返回值是NoneType ,而显然不能把此返回值再赋值list1,即list1 不能=NoneType。 正确的写法是【直接用 list1.append(m)就可以了】















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









