





提出问题:
hdfs是什么?
hdfs是一个分布式的文件系统,其核心思想是分而治之,即将大文件和大批量文件分布式存放在大量独立的服务器上,以便采取分而治之的方式对海量数据进行运算分析。是 Hadoop 应用程序使用的主要分布式存储。 HDFS 被设计成适合运行在通用硬件上的分布式文件系统。
HDFS 是一个主/从体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行 CRUD(Create、Read、Update 和 Delete)操作
文件系统:是操作系统提供的磁盘空间管理服务,该服务只需要用户指定文件的存储位置及文件读取路径,而不需要用户了解文件在磁盘上是如何存放的。
为什么要用hdfs?
我们知道文件是放在磁盘里面,假设现在有一般硬盘都是TB级别的,但是数据是PB级别这种问题怎么办?
可能会说我用磁盘阵列,将多个磁盘组成一个超大磁盘系统。形成独立磁盘冗余阵列简称RAID。这样可行。但是单个台服务器的容量始终有一个边界值,随着数据的增加,单台服务器很难放得下海量的数据。所以需要多台服务器来存储数据,而hdfs就是分布式的文件存储系统。可以存储多台服务器上的数据。那么hdfs是如何让实现的?原理是什么?下面将详细介绍!
是什么原理实现的?
HDFS将一个大文件分为一个个DataBlock块,默认每块128M(为什么是128?1秒定律!,1.0版本是64M,为什么每块这么大?减少寻址时间。),这里面的块是逻辑上的划分 。HDFS中小于一个块大小的文件不会占据整个块的空间。
当有一个超大文件的时候,hdfs将文件按照128M每块进行数据切分,并放到不同DataNode节点,使用namenode进行统一的元数据管理。使用分而治之的思想。HDFS 是个抽象层,底层依赖很多独立的服务器,对外提供统一的文件管理功能。
用户访问 HDFS 中的 /a/b/c.mpg 这个文件时,HDFS 负责从底层的相应服务器中读取该文件,然后返回给用户,这样用户就只需和 HDFS 打交道,而不用关心这个文件是如何存储的。
为了解决存储结点负载不均衡的问题,HDFS 首先把一个文件分割成多个块,然后再把这些文件块存储在不同服务器上。
这种方式的优势就是不怕文件太大,并且读文件的压力不会全部集中在一台服务器上,从而可以避免某个热点文件会带来的单机负载过高的问题。
但是如果某台服务器坏了,那么文件就会读不全。如果磁盘不能恢复,那么存储在上面的数据就会丢失。为了保证文件的可靠性,HDFS 会把每个文件块进行多个备份,一般情况下是 3 个备份。
HDFS的整体构架
HDFS是主从构架,NameNode和DataNode,其中NameNode是管理元数据的,而DataNode是真正存储数据的。
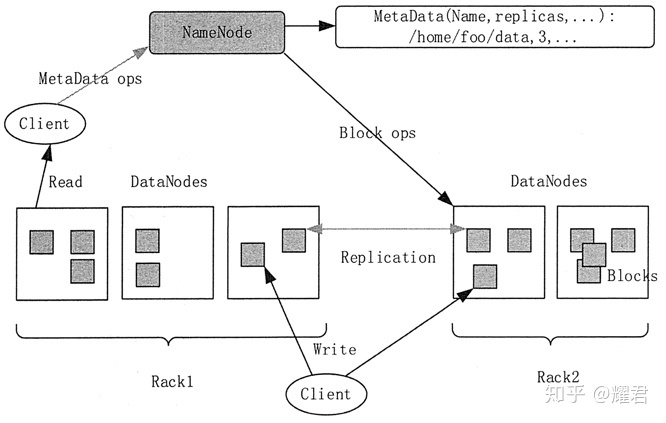
HDFS 会对外暴露一个文件系统命名空间,并允许用户数据以文件的形式进行存储。在内部,一个文件被分成多个块并且这些块被存储在一组 DataNode 上。
1)NameNode
文件的元数据采用集中式存储方案存放在 NameNode 当中。NameNode 负责执行文件系统命名空间的操作,如打幵、关闭、重命名文件和目录。NameNode 同时也负责将数据块映射到对应的 DataNode 中。
2)DataNode
DataNode 是文件系统的工作结点。它们根据需要存储并检索数据块,并且定期向 NameNode 发送他们所存储的块的列表。文件数据块本身存储在不同的 DataNode 当中,DataNode 可以分布在不同机架上。
DataNode 负责服务文件系统客户端发出的读/写请求。
DataNode 同时也负责接收 NameNode 的指令来进行数据块的创建、删除和复制。
总而言之DataNode 真正的工作是有DataNode 做的,所以DataNode 又叫做工作节点
3)Client
HDFS 的 Client 会分别访问 NameNode 和 DataNode 以获取文件的元信息及内容。HDFS 集群的 Client 将直接访问 NameNode 和 DataNode,相关数据会直接从 NameNode 或者 DataNode 传送到客户端。
NameNode 和 DataNode 都是被设计为在普通 PC 上运行的软件程序。HDFS 是用 Java 语言实现的,任何支持 Java 语言的机器都可以运行 NameNode 或者 DataNode。
Java 语言本身的可移植性意味着 HDFS 可以被广泛地部署在不同的机器上。
HDFS 数据复制
hdfs为了容错是,将每个数据块进行了备份,如果放在同一集群,万一集群挂了怎么办?如果放在别的机架,数据恢复的又太慢。所以备份的策略是,在本地的机架的相同节点放一个副本,本地不同节点放一个副本,不同机架放一个副本。
HDFS的读写流程
读取流程:
客户端向namenode发送连接
连接成功之后,客户端请求读取hdfs上的某个文件的某个数据块,namenode首先查看datanode有没有这个数据块
没有就返回没有,有的话向客户端返回数据块信息,具体在那些服务器上。
客户端接受到namenode返回的信息,去找对应的datanode进行连接,客户端选择距离最近的机器进行读取。最后关闭连接
写入流程:
客户端连接namenode,成功之后
向客户端向namenode发出写的请求,namenode查看是否有写的权限,要写的文件是否已存在
符合要求 namenode根据客户端的情况(写文件大小、客户端位置),分配给客户端写在数据的位置(在那些机器上)
客户端向datanode写入数据
datanode对数据进行复制
复制完成之后各个节点,上报新的block位置信息
datanode通知客户端写完了
checkpoint流程:
当datanode出现故障的时候,namenode会通过心跳机制(datanode每三秒会向namenode发送一次心跳,十秒没有接受到,就默认datanode出现故障。)知道了。namenode根据datanode的块信息回复数据,如果记录的信息有三分数据,而心跳只返回两条。就去别的机器备份的恢复。
如果namenode出现故障,备用的namenode转为active状态,根据本地磁盘fsimage恢复数据,如果不全那么会根据editlog日志恢复。














 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









