





以下内容引用 :An Introduction to Machine Learning with Python by Andreas C. Müller and Sarah Guido (O’Reilly). Copyright 2017 Sarah Guido and Andreas Müller, 978-1-449-36941-5.
书籍 :《Python机器学习基础教程》--图灵程序设计丛书
scikit_learn重要网址 :
http://scikit-learn. org/stable/documentation (算法字典)
https://scikit-learn.org/stable/
Andreas Müller 创建的视频课程“scikit-learn 高等机器学习"(Advanced Machine Learning with scikir-learn)https://www.oreilly.com/library/view/advanced-machine-learning/9781771374927/
代码示例: https://github.com/amueller/introduction_to_ml_with_python
定义
无监督学习算法只有输入数据是已知的,没有为算法提供输出数据。
无监督学习的类型
本文研究两种类型的无监督学习:数据集变换与聚类。
数据集的无监督变换(unsupervised transformation)是创建数据新的表示的算法,与数据的原始表示相比,新的表示可能更容易被人或其他机器学习算法所理解。
无监督变换的一个常见应用是降维(dimensionality reduction),它接受包含许多特征的数据的高维表示,并找到表示该数据的一种新方法,用较少的特征就可以概括其重要特性。降维的一个常见应用是为了可视化将数据降为二维。
另一个应用是找到“构成”数据的各个组成部分。
聚类算法(clustering algorithm)将数据划分成不同的组,每组包含相似的物项。
无监督学习的挑战和运用
挑战
无监督学习的一个主要挑战就是评估算法是否学到了有用的东西。无监督学习算法一般用于不包含任何标签信息的数据,所以我们不知道正确的输出应该是什么。因此很难判断一个模型是否“表现很好”。
评估无监督算法结果的唯一方法就是人工检查。
运用
用于探索性的目的,而不是作为大型自动化系统的一部分。
作为监督算法的预处理步骤。学习数据的一种新表示,有时可以提高监督算法的精度,或者可以减少内存占用和时间开销。
预处理和缩放
4种预处理
StandardScaler确保每个特征的平均值为0、方差为1,。但这种缩放不能保证特征任何特定的最大值和最小值。
RobustScaler使用的是中位数和四分位数。RobustScaler会忽略与其他点有很大不同的数据点(比如测量误差)。这些与众不同的数据点也叫异常值(outlier)。
MinMaxScaler移动数据,使所有特征都刚好位于0到1之间。,MinMaxScaler(以及其他所有缩放器)总是对训练集和测试集应用完全相同的变换。transform方法总是减去训练集的最小值,然后除以训练集的范围,而这两个值可能与测试集的最小值和范围并不相同。最后可能导致测试集缩放后最大值和最小值不是1和0。
Normalizer用到一种完全不同的缩放方法。它对每个数据点进行缩放,使得特征向量的欧式长度等于1。换句话说,它将一个数据点投射到半径为1的圆上(对于更高维度的情况,是球面)。这意味着每个数据点的缩放比例都不相同(乘以其长度的倒数)。如果只有数据的方向(或角度)是重要的,而特征向量的长度无关紧要,那么通常会使用这种归一化。
注:对训练数据和测试数据进行相同的缩放。
降维、特征提取与流形学习
利用无监督学习进行数据变换可能有很多种目的。最常见的目的就是可视化、压缩数据,以及寻找信息量更大的数据表示以用于进一步的处理。
以下主要学习主成分分析、非负矩阵分解(NMF)和t-SNE。前者通常用于特征提取,后者通常用于二维散点图的可视化。
主成分分析(principal component analysis,PCA)
一种旋转数据集的方法,旋转后的特征在统计上不相关。在做完这种旋转之后,通常是根据新特征对解释数据的重要性来选择它的一个子集。
主成分分析的数据变化流程case
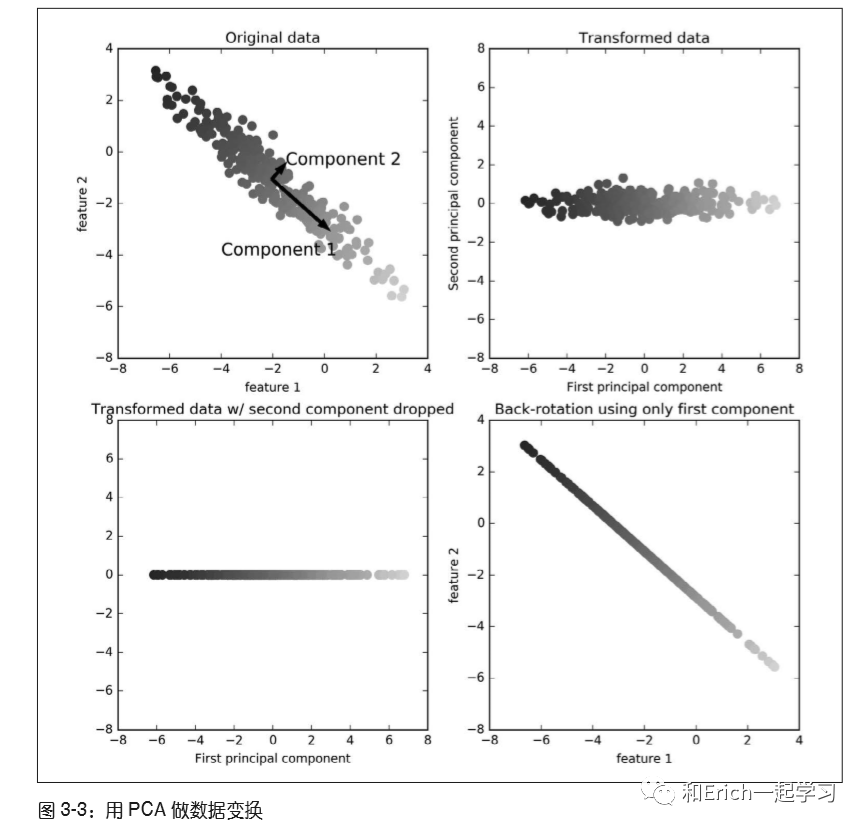
第一张图(左上)显示的是原始数据点,用不同颜色加以区分。算法首先找到方差最大的方向,将其标记为“成分 1”( Component 1)。这是数据中包含最多信息的方向(或向量),换句话说,沿着这个方向的特征之间最为相关。然后,算法找到与第一个方向正交(成直角)且包含最多信息的方向。在二维空间中,只有一个成直角的方向,但在更高维的空间中会有(无穷)多的正交方向。简单来说,将原本的两个特征,使用正交两个方向的向量表示,其中成分1包含了最多信息,成分2包含的信息较少。
右上图,将数据进行旋转,使得第一主成分与x轴平行且第二主成分与y轴平行。在旋转之前,从数据中减去平均值,使得变换后的数据以零为中心。在PCA找到的旋转表示中,两个坐标轴是不相关的,也就是说,对于这种数据表示,除了对角线,相关矩阵全部为零。个人理解,观察数据的方向改变并不会改变数据所包含的信息。(试想,一个三角形,从不同角度看,三角形本身会发生改变么?)
通过仅保留一部分主成分来使用PCA进行降维。在这个例子中,我们仅保留第一个主成分,如第三种图(左下图)。(可以理解剔除了不必要的信息,抓取了主要信息,从而实现降维)
反向旋转并将平均值重新加到数据中,得到第四张图(右下图)。这些数据点位于原始特征空间中,但我们仅保留了第一主成分中包含的信息。这种变换有时用于去除数据中的噪声影响,或者将主成分中保留的那部分信息可视化。
注:之前在监督学习中提过画散点图(二维)来观察数据,这里也提到了另外一种办法,直方图(一维)。

很方便观察某一变量和两个分类之间关系。但无法向我们展示变量之间的相互作用以及这种相互作用与类别之间的关系。
将PCA应用于数据集并可视化
以上我们提到直方图无法展示变量之间的相互作用以及这种相互作用与类别之间的关系。利用PCA,我们可以获取到主要的相互作用,并得到稍为完整的图像。我们可以找到前两个主成分,并在这个新的二维空间中用散点图将数据可视化。
在应用PCA之前,我们利用StandardScaler缩放数据,使每个特征的方差均为1。
解答为什么应用PCA前,要对数据进行 预处理/ 缩放/标准化。
引用于: https://blog.csdn.net/lizz2276/article/details/106268115?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v25-2-106268115.nonecase&utm_term=pca%E4%B9%8B%E5%89%8D%E9%9C%80%E8%A6%81%E6%A0%87%E5%87%86%E5%8C%96%E5%90%97

大概能懂了第一点(主要原因),第二点看不懂。
应用PCA。默认情况下,PCA仅旋转(并移动)数据,但保留所有的主成分。为了降低数据的维度,我们需要在创建PCA对象时指定想要保留的主成分个数

画出第一、二主成分和类别的散点图,如下图。重要的是要注意,PCA是一种无监督方法,在寻找旋转方向时没有用到任何类别信息。它只是观察数据中的相关性。对于这里所示的散点图,我们绘制了第一主成分与第二主成分的关系,然后利用类别信息对数据点进行着色。可以看到,在这个二维空间中两个类别被很好地分离。这让我们相信,即使是线性分类器(在这个空间中学习一条直线)也可以在区分这个两个类别时表现得相当不错。
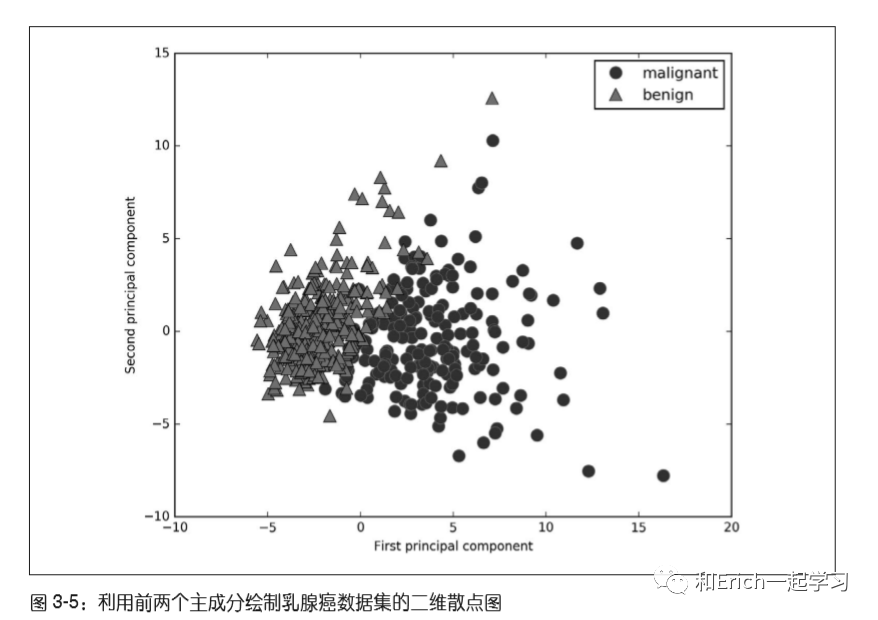
PCA的一个缺点
通常不容易对图中的两个轴做出解释。主成分对应于原始数据中的方向,所以它们是原始特征的组合,但这些组合往往非常复杂。
PCA应用于特征提取---以图像为case
特征提取背后的思想是,可以找到一种数据表示,比给定的原始表示更适合于分析。
书中案例:
一共有 3023 张图像,每张大小为 87 像素 ×65 像素,分别属于 62 个不同的人。但这个数据集有些偏斜,其中包含 George W. Bush(小布什)和 Colin Powell(科林 • 鲍威 尔)的大量图像。
为了降低数据偏斜,我们对每个人最多只取 50 张图像(否则,特征提取将会被 George W. Bush 的可能性大大影响)。
使用K近邻分类,测试集精度为26.6%>1/62。
想要度量人脸的相似度,计算原始像素空间中的距离是一种相当糟糕的方法。用像素表示来比较两张图像时,我们比较的是每个像素的灰度值与另一张图像对应位置的像素灰度值。这种表示与人们对人脸图像的解释方式有很大不同,使用这种原始表示很难获取到面部特征。例如,如果使用像素距离,那么将人脸向右移动一个像素将会发生巨大的变化,得到一个完全不同的表示。我们希望,使用沿着主成分方向的距离可以提高精度。启用 PCA 的白化(whitening)选项,将主成分缩放到相同的尺度。网上关于白化的解释:
由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得学习算法的输入具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。
使用PCA(启用白化)后,再次使用k近邻分类,测试集精度提高到35.7%。
PCA的理解
先旋转数据,然后删除方差较小的成分。
尝试找到一些数字(PCA旋转后的新特征值),使我们可以将测试点表示为主成分的加权求和,例如:

仅使用一些成分对原始数据进行重建。我们分别利用 10 个、50 个、 100 个和 500 个成分对一些人脸进行重建并将其可视化,如下图。如果使用的成分个数与像素个数相等,意味着我们在旋转后 不会丢弃任何信息,可以完美重建图像。

非负矩阵分解
算法理解(比较难理解,以后继续慢慢理解)
非负矩阵分解(non-negative matrix factorization,NMF)目的在于提取有用的特征。它的工作原理类似于PCA,也可以用于降维。与PCA相同,我们试图将每个数据点写成一些分量的加权求和。但在PCA中,我们想要的是正交分量,并且能够解释尽可能多的数据方差;而在NMF中,我们希望分量和系数均为非负,即,我们希望分量和系数都大于或等于0。
将数据分解成非负加权求和的这个过程,对由多个独立源相加(或叠加)创建而成的数据特别有用,比如多人说话的音轨或包含多种乐器的音乐。
以下为网上资料和个人理解:
引用 https://blog.csdn.net/SophisticatedWolf/article/details/104104308 。 |
个人理解,PCA是将数据拆分为多维的正交向量,且尽量某些向量包含尽可能多的信息(有用的主成分,未必很好解释),某些向量包含尽可能少的信息(没用的主成分,白噪音);而NMF,是将每个数据点均拆分为标准的基础向量的加权求和(权重均不为负),基础向量可解释度很高。举例,某个颜色=30个红色+20个蓝色(红色和蓝色作为基础向量,这种办法为NMF),若使用PCA,则这种颜色=25个“怪”色(无法知道具体是什么颜色)+0.1个正交的“非怪”色。
将NMF应用于模拟数据--加强对NMF的理解
与使用PCA不同,我们需要保证数据是正的。
以下图为例:|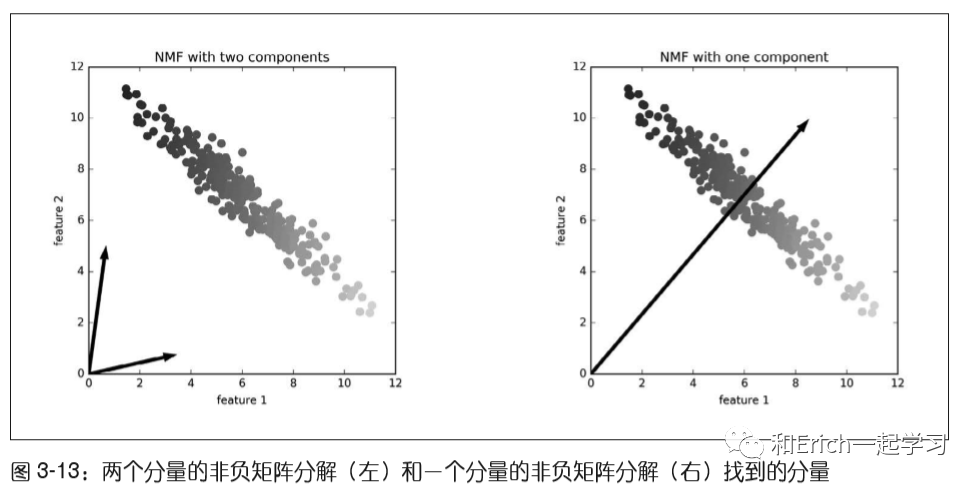
对于两个分量的NMF(如左图所示),显然所有数据点都可以写成这两个分量的正数组合。如果有足够多的分量能够完美地重建数据(分量个数与特征个数相同),那么算法会选择指向数据极值的方向。
如果我们仅使用一个分量,那么NMF会创建一个指向平均值的分量,因为指向这里可以对数据做出最好的解释。可以看到,与PCA不同,减少分量个数不仅会删除一些方向,而且会创建一组完全不同的分量!NMF的分量也没有按任何特定方法排序,所以不存在“第一非负分量”:所有分量的地位平等。
NMF的参数和特点
NMF的主要参数是我们想提取的分量个数。通常来说,这个数字要小于输入特征的个数(否则的话,将每个特征作为单独的分量就可以对数据进行解释)。
分量越多,反向变化的数据质量就越好。但同样数据集,比PCA稍差,因为PCA找到的是重建的最佳方向。NMF通常并不用于对数据进行重建或编码,而是用于在数据中寻找有趣的模式。
与PCA不同,减少分量个数不仅会删除一些方向,而且会创建一组完全不同的分量!NMF的分量也没有按任何特定方法排序,所以不存在“第一非负分量”:所有分量的地位平等
附:其他将每个数据点分解为一系列固定分量的加权求和的算法。推荐学习scikitlearn用户指南中关于独立成分分析(ICA)、因子分析(FA)和稀疏编码(字典学习)等的内容,所有这些内容都可以在关于分解方法的页面中找到( http://scikit-learn.org/stable/modules/decomposition.html )。
用t-SNE进行流形学习
流形学习介绍
PCA通常是用于变换数据的首选方法,使你能够用散点图将其可视化,但这一方法的性质(先旋转然后减少方向)限制了其有效性。
流形学习算法(例如t-SNE算法)主要用于可视化,因此很少用来生成两个以上的新特征。其中一些算法(包括t-SNE)计算训练数据的一种新表示,但不允许变换新数据,意味着不能用于测试集:更确切地说,它们只能变换用于训练的数据。
流形学习对探索性数据分析是很有用的,但如果最终目标是监督学习的话,则很少使用。
t-SNE原理
t-SNE背后的思想是找到数据的一个二维表示,尽可能地保持数据点之间的距离。t-SNE首先给出每个数据点的随机二维表示,然后尝试让在原始特征空间中距离较近的点更加靠近,原始特征空间中相距较远的点更加远离。t-SNE重点关注距离较近的点,而不是保持距离较远的点之间的距离。换句话说,它试图保存那些表示哪些点比较靠近的信息。
聚类
聚类(clustering)是将数据集划分成组的任务,这些组叫作簇(cluster)。其目标是划分数据,使得一个簇内的数据点非常相似且不同簇内的数据点非常不同。与分类算法类似,聚类算法为每个数据点分配(或预测)一个数字,表示这个点属于哪个簇。
k均值聚类
原理
k均值聚类试图找到代表数据特定区域的簇中心(cluster center)。算法交替执行以下两个步骤:将每个数据点分配给最近的簇中心,然后将每个簇中心设置为所分配的所有数据点的平均值。如果簇的分配不再发生变化,那么算法结束。
实现流程case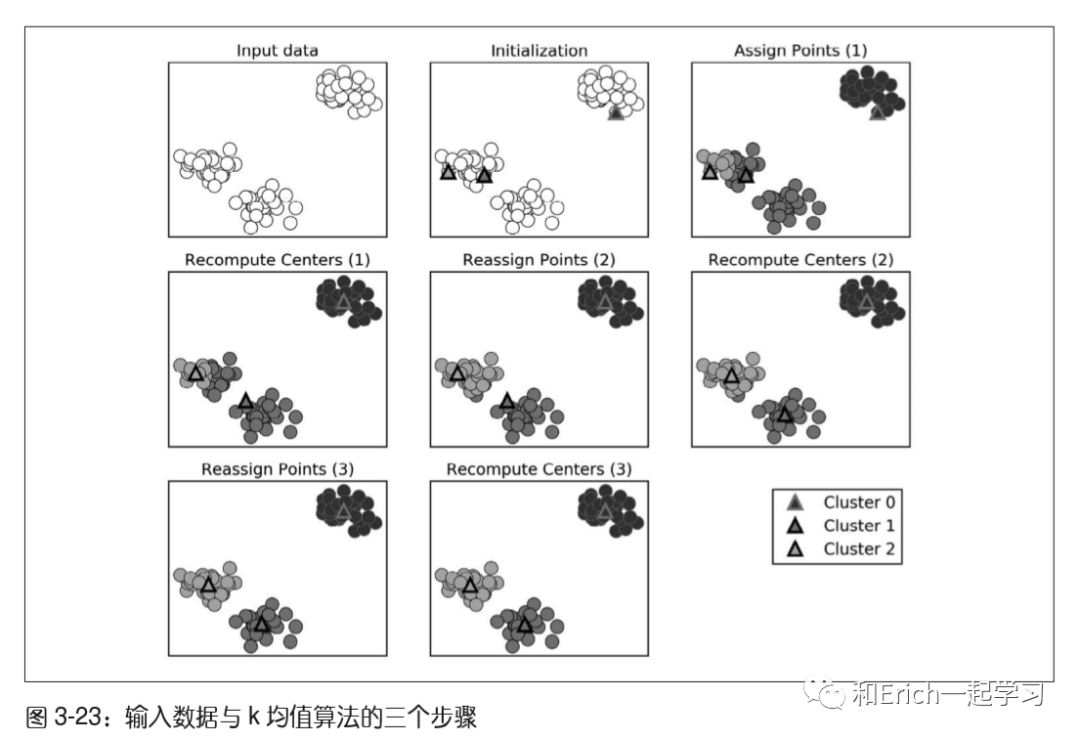
簇中心用三角形表示,而数据点用圆形表示。颜色表示簇成员。
我们指定要寻找三个簇,所以通过声明三个随机数据点为簇中心来将算法初始化(见图中“Initialization”/“初始化”)。然后开始迭代算法。
首先,每个数据点被分配给距离最近的簇中心(见图中“Assign Points(1)”/“分配数据点(1)”)。接下来,将簇中心修改为所分配点的平均值(见图中“Recompute Centers(1)”/“重新计算中心(1)”)。
然后将这一过程再重复两次。
在第三次迭代之后,为簇中心分配的数据点保持不变,因此算法结束。
给定新的数据点,k均值会将其分配给最近的簇中心。
k均值的失败案例
书上有case,但没有明白为什么是失败案例。后续跟进。
矢量量化,或者将k均值看作分解
如何理解将k均值看作分解?
PCA试图找到数据中方差最大的方向,而NMF试图找到累加的分量,这通常对应于数据的“极值”或“部分”。两种方法都试图将数据点表示为一些分量之和
与之相反,k均值则尝试利用簇中心来表示每个数据点。你可以将其看作仅用一个分量来表示每个数据点,该分量由簇中心给出。这种观点将k均值看作是一种分解方法,其中每个点用单一分量来表示,这种观点被称为矢量量化(vector quantization)。
k均值做矢量量化的一个有趣之处在于,可以用比输入维度更多的簇来对数据进行编码。利用PCA或NMF,我们对这个数据无能为力,因为它只有两个维度。使用PCA或NMF将其降到一维,将会完全破坏数据的结构。但通过使用更多的簇中心,我们可以用k均值找到一种更具表现力的表示。
使用k均值,每个数据点多了n个新特征(其中一个不为0,表示该点对应的簇中心,其他为0)
提问,是否可以使用该点到10个簇中心的距离来表示该数据点???
优点
容易理解和实现。
运行速度相对较快。
可以轻松扩展到大型数据集。
缺点
依赖于随机初始化。默认情况下,scikit-learn用10种不同的随机初始化将算法运行10次,并返回最佳结果。
就是对簇形状的假设的约束性较强(???哪些假设),而且还要求指定所要寻找的簇的个数(在现实世界的应用中可能并不知道这个数字)。
凝聚聚类
原理
凝聚聚类(agglomerative clustering)指的是许多基于相同原则构建的聚类算法,这一原则是:算法首先声明每个点是自己的簇,然后合并两个最相似的簇,直到满足某种停止准则为止。scikit-learn中实现的停止准则是簇的个数,因此相似的簇被合并,直到仅剩下指定个数的簇。还有一些链接(linkage)准则,规定如何度量“最相似的簇”。这种度量总是定义在两个现有的簇之间。scikit-learn 中实现了以下三种度量方式:
ward,默认选项。ward挑选两个簇来合并,使得所有簇中的方差增加最小。这通常会得到大小差不多相等的簇。
average,链接将簇中所有点之间平均距离最小的两个簇合并。
complete链接(也称为最大链接)将簇中点之间最大距离最小的两个簇合并。
注:ward适用于大多数数据集。如果簇中的成员个数非常不同(比如其中一个比其他所有都大得多),那么average或complete可能效果更好。
由于算法的工作原理,凝聚算法不能对新数据点做出预测。
凝聚聚类方法为选择正确的个数提供了一些帮助。如下的层次聚类与树状图。
层次聚类与树状图
层次聚类:聚类过程迭代进行,每个点都从一个单点簇变为属于最终的某个簇。每个中间步骤都提供了数据的一种聚类(簇的个数也不相同)。
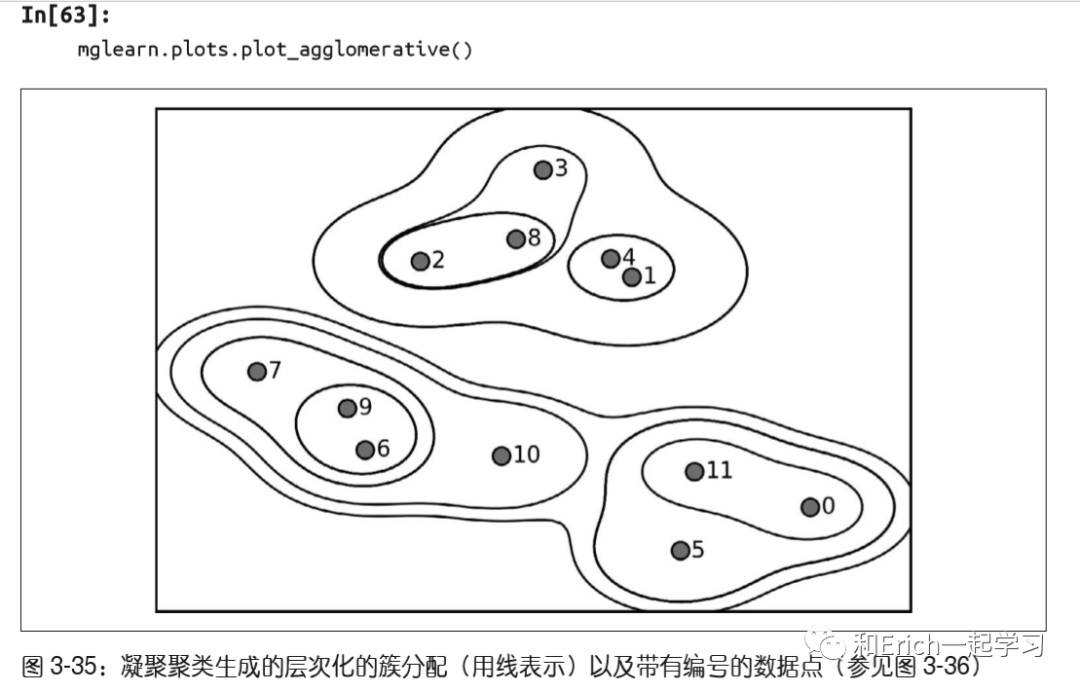
这种可视化为层次聚类提供了非常详细的视图,但它依赖于数据的二维性质,因此不能用于具有两个以上特征的数据集。
树状图:不同于层次聚类,树状图可以处理多维数据集。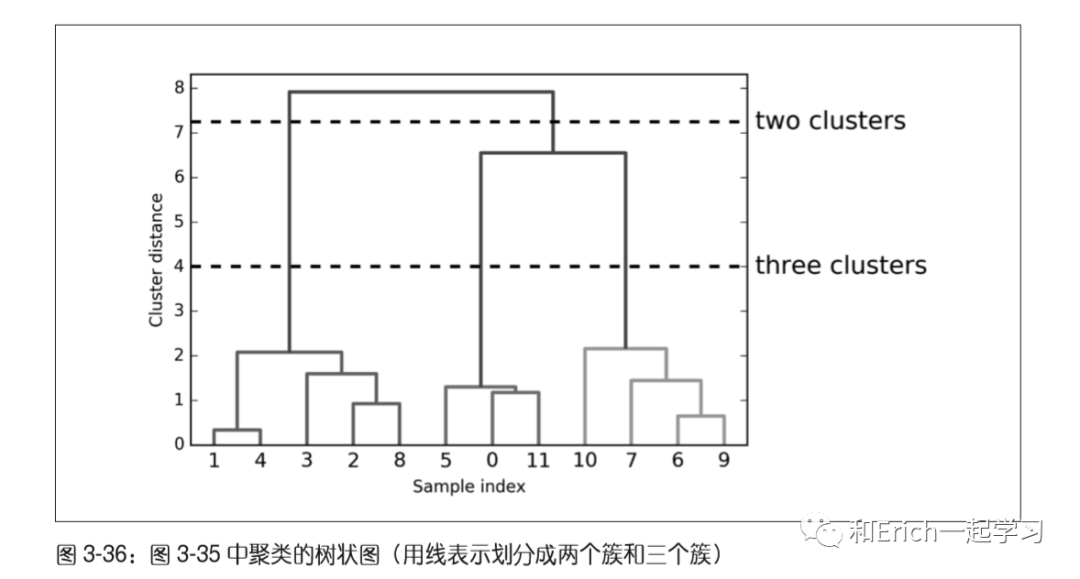
树状图在底部显示数据点(编号从0到11)。然后以这些点(表示单点簇)作为叶节点绘制一棵树,每合并两个簇就添加一个新的父节点。
树状图的y轴不仅说明凝聚算法中两个簇何时合并,每个分支的长度还表示被合并的簇之间的距离。在这张树状图中,最长的分支是用标记为“three clusters”(三个簇)的虚线表示的三条线。它们是最长的分支,这表示从三个簇到两个簇的过程中合并了一些距离非常远的点。我们在图像上方再次看到这一点,将剩下的两个簇合并为一个簇也需要跨越相对较大的距离。
DBSCAN(density-based spatial clustering of applications with noise,即“具有噪声的基于密度的空间聚类应用”)
原理
识别特征空间的“拥挤”区域中的点,在这些区域中许多数据点靠近在一起。这些区域被称为特征空间中的密集(dense)区域。DBSCAN背后的思想是,簇形成数据的密集区域,并由相对较空的区域分隔开。
实现过程及相关定义
在密集区域内的点被称为核心样本(core sample,或核心点),它们的定义如下。DBSCAN有两个参数:min_samples和eps。如果在距一个给定数据点eps的距离内至少有min_samples个数据点,那么这个数据点就是核心样本。DBSCAN将彼此距离小于eps的核心样本放到同一个簇中。
算法首先任意选取一个点,然后找到到这个点的距离小于等于eps的所有的点。如果距起始点的距离在eps之内的数据点个数小于min_samples,那么这个点被标记为噪声(noise),也就是说它不属于任何簇。如果距离在eps之内的数据点个数大于min_samples,则这个点被标记为核心样本,并被分配一个新的簇标签。
然后访问该点的所有邻居(在距离eps以内)。如果它们还没有被分配一个簇,那么就将刚刚创建的新的簇标签分配给它们。如果它们是核心样本,那么就依次访问其邻居,以此类推。簇逐渐增大,直到在簇的eps距离内没有更多的核心样本为止。然后选取另一个尚未被访问过的点,并重复相同的过程。
最后,一共有三种类型的点:核心点、与核心点的距离在eps之内的点(叫作边界点,boundarypoint)和噪声。如果DBSCAN算法在特定数据集上多次运行,那么核心点的聚类始终相同,同样的点也始终被标记为噪声。但边界点可能与不止一个簇的核心样本相邻。因此,边界点所属的簇依赖于数据点的访问顺序。一般来说只有很少的边界点,这种对访问顺序的轻度依赖并不重要。
参数
增大eps,更多的点会被包含在一个簇中。这让簇变大,但可能也会导致多个簇合并成一个。
参数eps在某种程度上更加重要,因为它决定了点与点之间“接近”的含义。将eps设置得非常小,意味着没有点是核心样本,可能会导致所有点都被标记为噪声。将eps设置得非常大,可能会导致所有点形成单个簇。
增大min_samples,核心点会变得更少,更多的点被标记为噪声。
设置min_samples主要是为了判断稀疏区域内的点被标记为异常值还是形成自己的簇。如果增大min_samples,任何一个包含少于min_samples个样本的簇现在将被标记为噪声。因此,min_samples决定簇的最小尺寸。
虽然DBSCAN不需要显式地设置簇的个数,但设置eps可以隐式地控制找到的簇的个数。使用StandardScaler或MinMaxScaler对数据进行缩放之后,有时会更容易找到eps的较好取值,因为使用这些缩放技术将确保所有特征具有相似的范围。
优点
不需要用户先验地设置簇的个数,可以划分具有复杂形状的簇。
找出不属于任何簇的点。
比凝聚聚类和k均值稍慢,但仍可以扩展到相对较大的数据集。
聚类算法的对比与评估
用真实值评估聚类
调整rand指数(adjusted rand index,ARI)和归一化互信息(normalized mutual information,NMI),二者都给出了定量的度量,其最佳值为1,0表示不相关的聚类(虽然ARI可以取负值)。
在没有真实值的情况下评估聚类
在实践中,使用诸如ARI之类的指标有一个很大的问题。在应用聚类算法时,
通常没有真实值来比较结果。
有一些聚类的评分指标不需要真实值,比如轮廓系数(silhouette coeffcient)。但它们在实践中的效果并不好。轮廓分数计算一个簇的紧致度,其值越大越好,最高分数为1。虽然紧致的簇很好,但紧致度不允许复杂的形状。
在人脸数据集上比较算法
用聚类算法对数据进行分类(例如对100个PCA进行分类),对每个簇进行人工观察。
聚类方法小结
聚类的应用与评估是一个非常定性的过程,通常在数据分析的探索阶段很有帮助。
k均值、DBSCAN和凝聚聚类,这三种算法都可以控制聚类的粒度(granularity)。k均值和凝聚聚类允许你指定想要的簇的数量,而DBSCAN允许你用eps参数定义接近程度,从而间接影响簇的大小。
三种方法都可以用于大型的现实世界数据集,都相对容易理解,也都可以聚类成多个簇。
k均值可以用簇的平均值来表示簇。它还可以被看作一种分解方法,每个数据点都由其簇中心表示。
凝聚聚类可以提供数据的可能划分的整个层次结构,可以通过树状图轻松查看。
DBSCAN可以检测到没有分配任何簇的“噪声点”,还可以帮助自动判断簇的数量。与其他两种方法不同,它允许簇具有复杂的形状。DBSCAN有时会生成大小差别很大的簇,这可能是它的优点,也可能是缺点。
小结与展望
以上介绍了一系列无监督学习算法,可用于探索性数据分析和预处理。找到数据的正确表示对于监督学习和无监督学习的成功通常都至关重要,预处理和分解方法在数据准备中具有重要作用。
分解、流形学习和聚类都是加深数据理解的重要工具,在没有监督信息的情况下,也是理解数据的仅有的方法。即使是在监督学习中,探索性工具对于更好地理解数据性质也很重要。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









