






的话
在前面的 秘籍一 中,我们主要关注了模型加速之轻量化网络,对目标检测模型的实时性难点进行了攻克。但是要想获得较好的检测性能,检测算法的细节处理也极为重要。
在众多的细节处理中,先来介绍非极大值抑制、回归损失函数这2个问题。本文主要介绍秘籍二:非极大值抑制与回归损失的优化之路。
秘籍二. 非极大值抑制与回归损失优化之路
当前的物体检测算法为了保证召回率,对于同一个真实物体往往会有多于1个的候选框输出。由于多余的候选框会影响检测精度,因此需要利用NMS过滤掉重叠的候选框,得到最佳的预测输出。
基本的NMS方法,利用得分高的边框抑制得分低且重叠程度高的边框。然而基本的NMS存在一些缺陷,简单地过滤掉得分低且重叠度高的边框可能会导致漏检等问题。针对此问题陆续产生了一系列改进的方法,如Soft NMS、Softer NMS及IoU-Net等。
目标检测主要的任务:1)对象是什么?2)对象在哪里?其中,对象是什么主要分清楚对象的类别。而对象在哪里,需要寻找这个对象在图像中的位置。回归损失问题就是探讨如何更好地学习对象在哪里。当然最近anchor free的方法有很多,但是主流应用上目前还是基于anchor的方式。
对于有先验框的目标检测,位置是通过学习给定的先验框和真实目标框的距离来进行预测。而这个距离的刻画主要通过距离公式来度量,比如曼哈顿距离L1和欧式距离L2。
那么利用欧式距离来计算存在什么问题呢?继续往下看,下面将详细介绍。一起来看攻克目标检测难点秘籍二:非极大值抑制和回归损失优化之路。
1 NMS:非极大值抑制优化
为了保证物体检测的召回率,在Faster RCNN或者SSD网络的计算输出中,通常都会有不止一个候选框对应同一个真实物体。如下图左图是人脸检测的候选框结果,每个边界框有一个置信度得分(confidence score),如果不使用非极大值抑制,就会有多个候选框出现。右图是使用非极大值抑制之后的结果,符合我们人脸检测的预期结果。

非极大值抑制,顾名思义就是抑制不是极大值的边框,这里的抑制通常是直接去掉冗余的边框。这个过程涉及以下两个量化指标。
预测得分:NMS假设一个边框的预测得分越高,这个框就要被优先考虑,其他与其重叠超过一定程度的边框要被舍弃,非极大值即是指得分的非极大值。
IoU:在评价两个边框的重合程度时,NMS使用了IoU这个指标。如果两个边框的IoU超过一定阈值时,得分低的边框会被舍弃。阈值通常会取0.5或者0.7。
NMS算法输入包含了所有预测框的得分、左上点坐标、右下点坐标一共5个预测量,以及一个设定的IoU阈值。算法具体流程如下:
(1)按照得分,对所有边框进行降序排列,记录下排列的索引order,并新建一个列表keep,作为最终筛选后的边框索引结果。
(2)将排序后的第一个边框置为当前边框,并将其保留到keep中,再求当前边框与剩余所有框的IoU。
(3)在order中,仅仅保留IoU小于设定阈值的索引,重复第(2)步,直到order中仅仅剩余一个边框,则将其保留到keep中,退出循环,NMS结束。
利用PyTorch,可以很方便地实现NMS模块。
def nms(self, bboxes, scores, thresh=0.5): x1 = bboxes[:,0] y1 = bboxes[:,1] x2 = bboxes[:,2] y2 = bboxes[:,3] areas = (x2-x1+1)*(y2-y1+1) _, order = scores.sort(0, descending=True) keep = [] while order.numel() > 0: if order.numel() == 1: i = order.item() keep.append(i) break else: i = order[0].item() keep.append(i) xx1 = x1[order[1:]].clamp(min=x1[i]) yy1 = y1[order[1:]].clamp(min=y1[i]) xx2 = x2[order[1:]].clamp(max=x2[i]) yy2 = y2[order[1:]].clamp(max=y2[i]) inter = (xx2-xx1).clamp(min=0) * (yy2-yy1).clamp(min=0) iou = inter / (areas[i]+areas[order[1:]]-inter) idx = (iou <= threshold).nonzero().squeeze() if idx.numel() == 0: break order = order[idx+1] return torch.LongTensor(keep)NMS方法虽然简单有效,但在更高的目标检测需求下,也存在如下缺点:
将得分较低的边框强制性地去掉,如果物体出现较为密集时,本身属于两个物体的边框,其中得分较低的也有可能被抑制掉,降低了模型的召回率。
速度:NMS的实现存在较多的循环步骤,GPU的并行化实现不是特别容易,尤其是预测框较多时,耗时较多。
将得分作为衡量指标。NMS简单地将得分作为一个边框的置信度,但在一些情况下,得分高的边框不一定位置更准。
阈值难以确定。过高的阈值容易出现大量误检,而过低的阈值则容易降低模型的召回率,超参很难确定。
1.1 Soft NMS:抑制得分
NMS方法虽有效过滤了重复框,但也容易将本属于两个物体框中得分低的框抑制掉,从而降低了召回率。造成这种现象的原因在于NMS的计算公式。
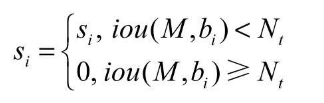
公式中Si代表了每个边框的得分,M为当前得分最高的框,bi为剩余框的某一个,Nt为设定的阈值,可以看到,当IoU大于Nt时,该边框的得分直接置0,相当于被舍弃掉了,从而有可能造成边框的漏检。
而SoftNMS算法对于IoU大于阈值的边框,没有将其得分直接置0,而是降低该边框的得分,具体方法是:
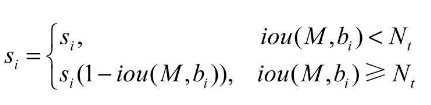
从公式中可以看出,利用边框的得分与IoU来确定新的边框得分,如果当前边框与边框M的IoU超过设定阈值Nt时,边框的得分呈线性的衰减。
但是,上式并不是一个连续的函数,当一个边框与M的重叠IoU超过阈值Nt时,其得分会发生跳变,这种跳变会对检测结果产生较大的波动。
因此还需要寻找一个更为稳定、连续的得分重置函数,最终Soft NMS给出了如下式所示的重置函数。
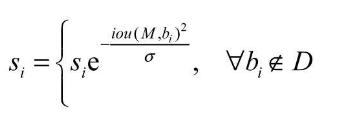
采用这种得分衰减的方式,对于某些得分很高的边框来说,在后续的计算中还有可能被作为正确的检测框,而不像NMS那样“一棒子打死”,因此可以有效提升模型的召回率。
Soft NMS的计算复杂度与NMS相同,是一种更为通用的非极大值抑制方法,可以将NMS看做Soft NMS的二值化特例。
Soft NMS优缺点分析
优点:
1、Soft-NMS可以很方便地引入到object detection算法中,不需要重新训练原有的模型、代码容易实现,不增加计算量(计算量相比整个object detection算法可忽略)。并且很容易集成到目前所有使用NMS的目标检测算法。
2、Soft-NMS在训练中采用传统的NMS方法,仅在推断代码中实现soft-NMS。作者应该做过对比试验,在训练过程中采用soft-NMS没有显著提高。
3、NMS是Soft-NMS特殊形式,当得分重置函数采用二值化函数时,Soft-NMS和NMS是相同的。Soft-NMS算法是一种更加通用的非最大抑制算法。
缺点:
Soft-NMS也是一种贪心算法,并不能保证找到全局最优的检测框分数重置。除了以上这两种分数重置函数,我们也可以考虑开发其他包含更多参数的分数重置函数,比如Gompertz函数等。但是它们在完成分数重置的过程中增加了额外的参数。
1.2 Softer NMS:加权平均
NMS与Soft NMS算法都使用了预测分类置信度作为衡量指标,即假定分类置信度越高的边框,其位置也更为精准。但很多情况下并非如此。
NMS时用到的score仅仅是分类置信度得分,不能反映Bounding box的定位精准度,既分类置信度和定位置信非正相关的,直接使用分类置信度作为NMS的衡量指标并非是最佳选择。
NMS只能解决分类置信度和定位置信度都很高的,但是对其它三种类型:“分类置信度低-定位置信度低”,“分类置信度高-定位置信度低”,“分类置信度低-定位置信度高“都无法解决。
基于此现象,Softer NMS进一步改进了NMS的方法,新增加了一个定位置信度的预测,使得高分类置信度的边框位置变得更加准确,从而有效提升了检测的性能。
首先,为了更加全面地描述边框预测,Softer NMS方法对预测边框与真实物体做了两个分布假设:1.真实物体的分布是狄拉克delta分布,即标准方差为0的高斯分布的极限。2.预测边框的分布满足高斯分布。
基于这两个假设,Softer NMS提出了一种基于KL(Kullback-Leibler)散度的边框回归损失函数KL loss。KL散度是用来衡量两个概率分布的非对称性衡量,KL散度越接近于0,则两个概率分布越相似。
具体到边框上,KL Loss是最小化预测边框的高斯分布与真实物体的狄克拉分布之间的KL散度。即预测边框分布越接近于真实物体分布,损失越小。
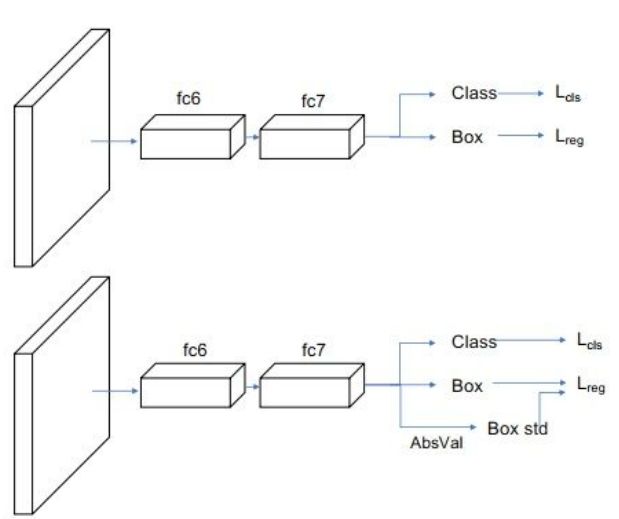
为了描述边框的预测分布,除了预测位置之外,还需要预测边框的标准差。Softer NMS在原Fast RCNN预测的基础上,增加了一个标准差预测分支,从而形成边框的高斯分布,与边框的预测一起可以求得KL损失。
Softer NMS的实现过程,其实很简单,预测的四个顶点坐标,分别对IoU>Nt的预测加权平均计算,得到新的4个坐标点。第i个box的x1计算公式如下(j表示所有IoU>Nt的box):
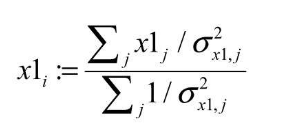
可以看出,Softer NMS对于IoU大于设定阈值的边框坐标进行了加权平均,希望分类得分高的边框能够利用到周围边框的信息,从而提升其位置的准确度。
1.3 IoU-Net:定位置信度
目标检测的分类与定位通常被两个分支预测。对于候选框的类别,模型给出了一个类别预测,可以作为分类置信度,然而对于定位而言,回归模块通常只预测了一个边框的转换系数,而缺失了定位的置信度,即框的位置准不准,并没有一个预测结果。
定位置信度的缺失也导致了在前面的NMS方法中,只能将分类的预测值作为边框排序的依据,然而在某些场景下,分类预测值高的边框不一定拥有与真实框最接近的位置,因此这种标准不平衡可能会导致更为准确的边框被抑制掉。
基于此,旷视提出了IoU-Net,增加了一个预测候选框与真实物体之间的IoU分支,并基于此改善了NMS过程,进一步提升了检测器的性能。
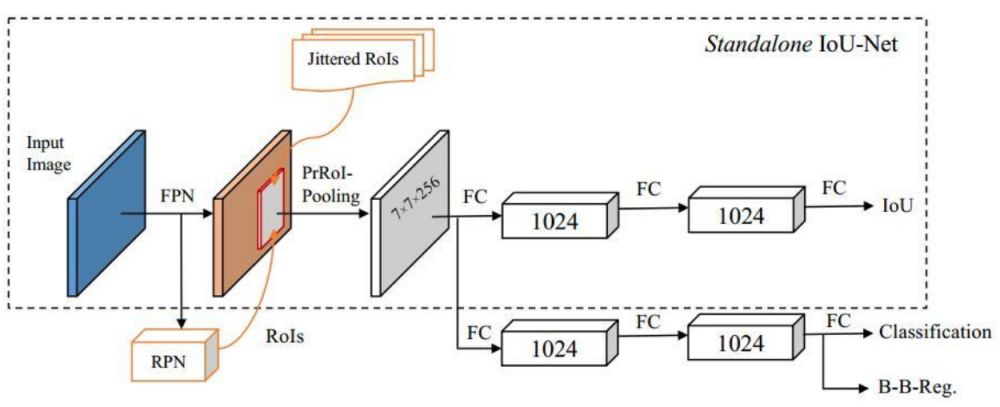
IoU-Net的基础架构与原始的Faster RCNN类似,使用了FPN方法作为基础特征提取模块,然后经过RoI的Pooling得到固定大小的特征图,利用全连接网络完成最后的多任务预测。
同时,IoU-Net与Faster RCNN也有不同之处,主要有3点:
1. 在Head处增加了一个IoU预测的分支,与分类回归分支并行。图中的Jittered RoIs模块用于IoU分支的训练。
2. 基于IoU分支的预测值,改善了NMS的处理过程。
3. 提出了PrRoI-Pooling(Precise RoI Pooling)方法,进一步提升了感兴趣区域池化的精度。
IoU预测分支
IoU分支用于预测每一个候选框的定位置信度。需要注意的是,在训练时IoU-Net通过自动生成候选框的方式来训练IoU分支,而不是从RPN获取。
具体来讲,Jittered RoIs在训练集的真实物体框上增加随机扰动,生成了一系列候选框,并移除与真实物体框IoU小于0.5的边框。实验证明这种方法来训练IoU分支可以带来更高的性能与稳健性。IoU分支也可以方便地集成到当前的物体检测算法中。
在整个模型的联合训练时,IoU预测分支的训练数据需要从每一批的输入图像中单独生成。此外,还需要对IoU分支的标签进行归一化,保证其分布在[-1,1]区间中。
基于定位置信度的NMS
由于IoU预测值可以作为边框定位的置信度,因此可以利用其来改善NMS过程。IoU-Net利用IoU的预测值作为边框排列的依据,并抑制掉与当前框IoU超过设定阈值的其他候选框。此外,在NMS过程中,IoU-Net还做了置信度的聚类,即对于匹配到同一真实物体的边框,类别也需要拥有一致的预测值。具体做法是,在NMS过程中,当边框A抑制边框B时,通过下式来更新边框A的分类置信度。
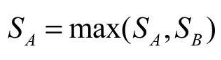
PrRoI-Pooling方法
RoI Align的方法,通过采样的方法有效避免了量化操作,减小了RoIPooling的误差,如图下图所示。但Align的方法也存在一个缺点,即对每一个区域都采取固定数量的采样点,但区域有大有小,都采取同一个数量点,显然不是最优的方法。
以此为出发点,IoU-Net提出了PrRoI Pooling方法,采用积分的方式实现了更为精准的感兴趣区域池化,如下图中的右图所示。
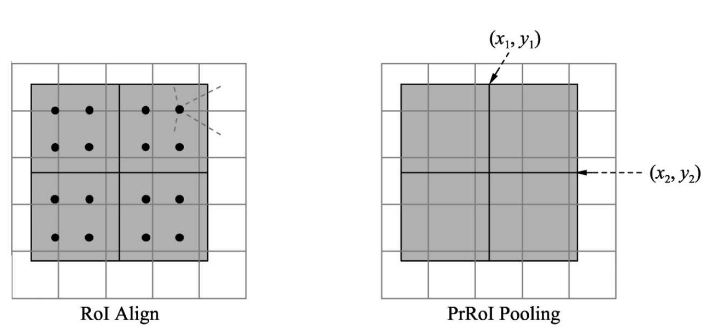
与RoI Align只采样4个点不同,PrRoI Pooling方法将整个区域看做是连续的,采用积分公式求解每一个区域的池化输出值,区域内的每一个点(x, y)都可以通过双线性插值的方法得到。这种方法还有一个好处是其反向传播是连续可导的,因此避免了任何的量化过程。
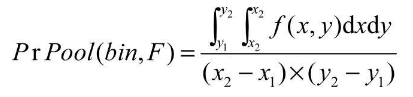
总体上,IoU-Net提出了一个IoU的预测分支,解决了NMS过程中分类置信度与定位置信度之间的不一致,可以与当前的物体检测框架一起端到端地训练,在几乎不影响前向速度的前提下,有效提升了物体检测的精度。
2 回归损失函数优化
正如前面讲到的,对于有先验框的目标检测,位置是通过学习给定的先验框和真实目标框的距离来进行预测。而这个距离的刻画主要通过距离公式来度量,比如曼哈顿距离L1和欧式距离L2。
利用常见的L1和L2距离公式来刻画IoU存在缺陷,主要原因还是距离度量将各个点孤立来进行,而IoU刻画的是整体的重合度问题。在这个问题基础上,IoU系列损失函数被提出来了。
2.1 IoU
由于L1和L2距离损失没有很好的刻画目标检测的最终指标IoU,有学者提出,能否直接用IoU来进行优化呢?
IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchor-based的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。
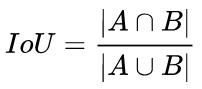
IoU可以反映预测检测框与真实检测框的检测效果。还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性)
def Iou(box1, box2, wh=False): if wh == False: xmin1, ymin1, xmax1, ymax1 = box1 xmin2, ymin2, xmax2, ymax2 = box2 else: xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0) xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0) xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0) xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0) # 获取矩形框交集对应的左上角和右下角的坐标(intersection) xx1 = np.max([xmin1, xmin2]) yy1 = np.max([ymin1, ymin2]) xx2 = np.min([xmax1, xmax2]) yy2 = np.min([ymax1, ymax2]) # 计算两个矩形框面积 area1 = (xmax1-xmin1) * (ymax1-ymin1) area2 = (xmax2-xmin2) * (ymax2-ymin2) inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1])) #计算交集面积 iou = inter_area / (area1+area2-inter_area+1e-6) #计算交并比 return iouIOU作为损失函数会出现的问题:
1.如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。
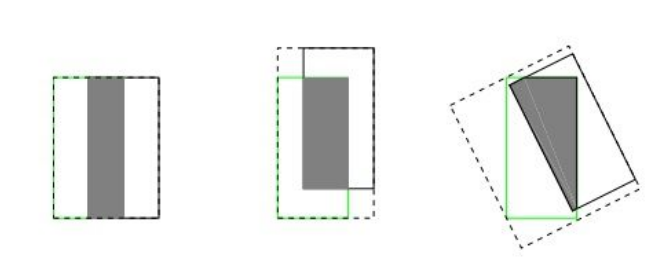
2.IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
2.2 GIoU
考虑到以上IOU的问题,有学者提出了GIoU:
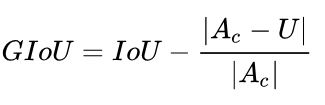
上面公式的意思是:先计算两个框的最小闭包区域面积 (通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
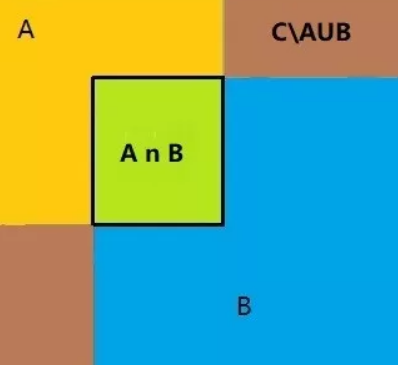
引入C\AUB项可以看出,即使两个目标没有并集,那么GIoU的值也会是-|C\(AUB)|/|C|,而两个目标如果距离的越来越远,这个值大小也会越来越大。因此加入了这一项之后缓解了IoU损失中目标框和预测框无交集,梯度为0而导致的无法优化问题。
GIoU主要特点
GIoU对尺度scale不敏感
GIoU是IoU的下界,在两个框无线重合的情况下,IoU=GIoU。IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。
与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
def Giou(rec1,rec2): #分别是第一个矩形左右上下的坐标 x1,x2,y1,y2 = rec1 x3,x4,y3,y4 = rec2 iou = Iou(rec1,rec2) area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4))*(max(y1,y2,y3,y4)-min(y1,y2,y3,y4)) area_1 = (x2-x1)*(y1-y2) area_2 = (x4-x3)*(y3-y4) sum_area = area_1 + area_2 w1 = x2 - x1 #第一个矩形的宽 w2 = x4 - x3 #第二个矩形的宽 h1 = y1 - y2 h2 = y3 - y4 W = min(x1,x2,x3,x4)+w1+w2-max(x1,x2,x3,x4) #交叉部分的宽 H = min(y1,y2,y3,y4)+h1+h2-max(y1,y2,y3,y4) #交叉部分的高 Area = W*H #交叉的面积 add_area = sum_area - Area #两矩形并集的面积 end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重 giou = iou - end_area return giouGIoU的改进使得预测框和真实框即使无重叠也可以优化,然而其依然存在着两个问题:1)对于预测框和真实框在水平或者竖直情况下,不管其距离远近,其GIoU的计算值几乎相同,接近于0。2)对于预测框包含住真实框的情况下,GIoU退化为IoU,在这种情况下,无法找到最合适的预测框。
基于IoU和GIoU存在的问题,论文《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》作者提出了两个问题:
第一:直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度。
第二:如何使回归在与目标框有重叠甚至包含时更准确、更快。
文中提出了目标检测中回归框主要考虑的三要素:重叠区域,中心距离和宽高比。作者提出了DIoU和CIoU损失,提高了目标检测的精度。
2.3 DIoU
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。
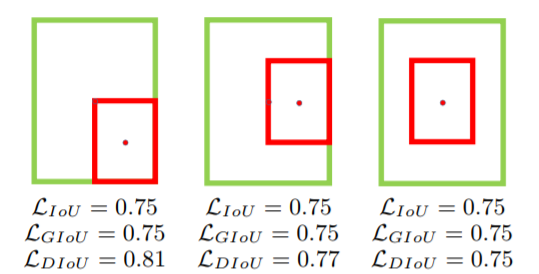
显然从图中可以看出,最右边的图是最理想的预测框情况,然而IoU或者GIoU计算的这三者的值是相等的,所以GIoU的刻画还是无法找到一些最优情况。因此作者提出了DIoU。
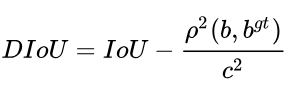
其中,  ,
,  分别代表了预测框和真实框的中心点,且
分别代表了预测框和真实框的中心点,且  代表的是计算两个中心点间的欧式距离。
代表的是计算两个中心点间的欧式距离。  代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
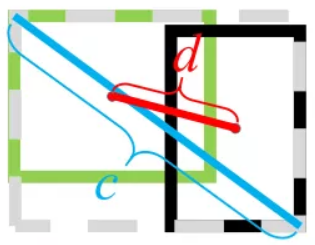
通过上述的改进,DIoU既保留了GIoU的一些保留特性,同时其又带来了几个优势:
1. DIoU能直接优化预测框和真实框的距离,比GIoU更快。
2. DIoU缓解了GIoU在预测框和真实框在水平或者竖直情况下|C-AUB|接近于0的问题。
作者在文中还提到了对NMS进行改进,提出将中心距离也作为其中的一个变量来选择最好的预测框。
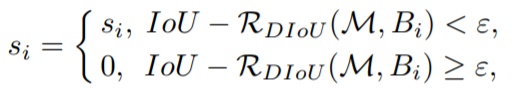
DIoU主要特点
与GIoU loss类似,DIoU loss在与目标框不重叠时,仍然可以为边界框提供移动方向。
DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
2.4 CIOU
论文作者在提出了DIoU的基础上,回答了一个问题,即一个好的回归框损失应该考虑哪几个点?作者给出了答案,三个要素:重叠区域,中心点的距离,宽高比。
DIoU考虑了重叠区域和中心点距离问题,还剩下宽高比没考虑,因此后续提出了CIoU损失。
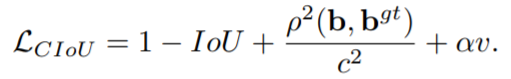
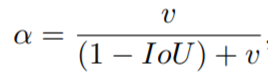
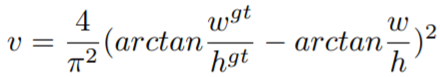
上述CIoU主要是在DIoU的基础上,加入了宽和高的比值,将第三个要素宽高比也加入进来,具体的,多了和这两个参数。其中是用来平衡比例的系数,是用来衡量Anchor框和目标框之间的比例一致性。
因为实际中宽和高都是非常小的值,在进行求梯度的时候要注意防止梯度爆炸的问题。具体的,一般都会对原始的,分别处以原图像的长宽。所以直接将设为常数1,这样不会导致梯度的方向改变,虽然值变了,但这可以加快收敛。
实验分析
试验数据集:采用PASCAL VOC和COCO数据集进行评测。
网络模型:采用了单阶段的SSD和YOLOV3以及双阶段的FasterRCNN网络。
评价指标:AP = (AP50 + AP55+ : : : + AP95) / 10 ,IoU阈值从0.5,0.55到0.95总共10个值的平均。AP75 (mAP@0.75)是IoU阈值为0.75时的值。
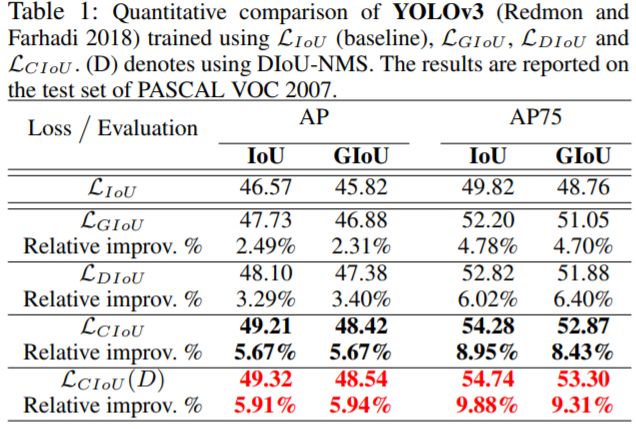
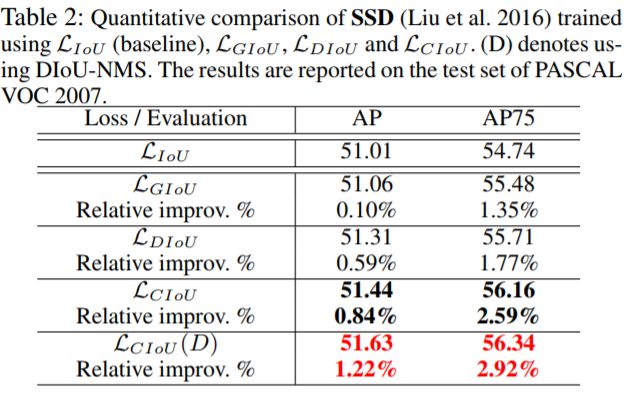
将上述提出的DIoU和CIoU应用到上述的单阶段网络,可以看出,相比较而言,改进的损失都有了一定的提升。特别是阈值为0.75的时候更加的明显。
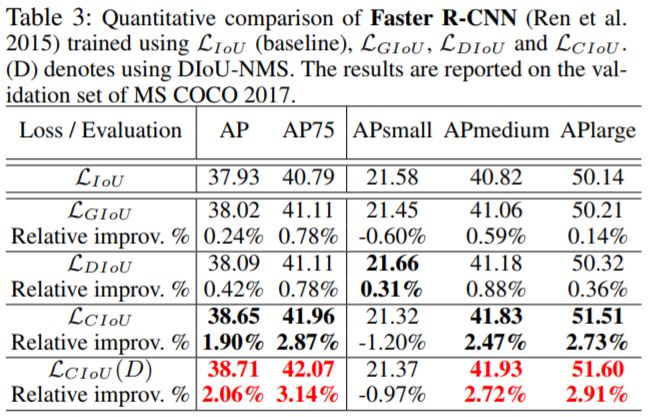
对于FasterRCNN来看,DIoU和CIoU都有一定的提升,且CIoU提升比较大。
代码复现参考
https://github.com/JaryHuang/awesome_SSD_FPN_GIoU
https://github.com/Zzh-tju/DIoU-darknet
参考:
1.深度学习之PyTorch物体检测实战 董洪义2.https://zhuanlan.zhihu.com/p/94799295
3.https://blog.csdn.net/qiu931110/article/details/103330107
4.论文原文:https://arxiv.org/pdf/1911.08287.pdf
-END-















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









