






spark stream中的Dstream是对RDD的更高层次抽象,Dstream其实就是RDD的模板,在spark stream中对Dstream的操作最终都会转换为对RDD的操作!
我们来看看Dstream的继承结构,是不是感觉跟RDD的继承结构有些类似呢?
下面通过简单的wordCount 程序来研究Dstream之间的关系
1 val lines = ssc.socketTextStream("localhost", 9999)
2 val words = lines.flatMap(_.split(" "))
3 val pairs = words.map(word => (word, 1))
4 val wordCounts = pairs.reduceByKey(_ + _)
5 wordCounts.print()
======================================
第1行产生的类型为SocketInputDStream
第2行产生的类型为FlatMappedDStream
第3行产生的类型为MappedDStream
第4行产生的类型为ShuffledDStream
第5行产生的类型为ForeachDStream
这些Dstream的依赖关系底层其实都是RDD的依赖关系,在spark core中DAG图中当Action动作触发的时候,才会从后往前进行回溯整个过程。在spark stream中这是这样一个过程。
下面我们根据代码来回溯这个过程:
在第5行wordCounts.print() 代码中会有一个Action的动作。

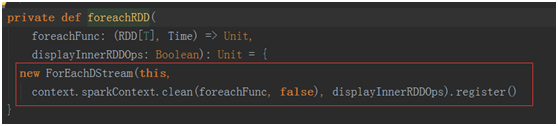
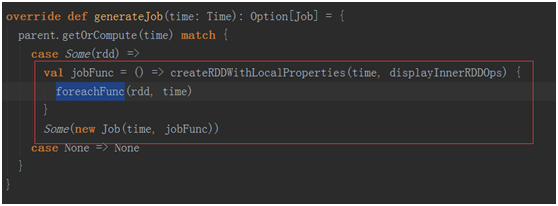
最终会产生一个 ForEachDStream
进入ForEachDStream 看一下它的generateJob方法。这个方法会被JobGenerator中的generateJobs(time: Time) 进行调用。
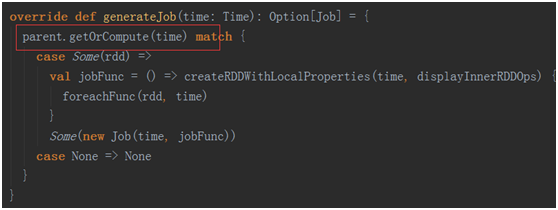
在这里调用了当前Dstream依赖的父Dstream,在我们这个例子中是ShuffledDStream。那么我们进入ShuffledDStream找到getOrComputer方法(应为继承与实现的关系,我们在Dsstream中找到了getOrComputer,儿该方法调用实现类的Computer方法)

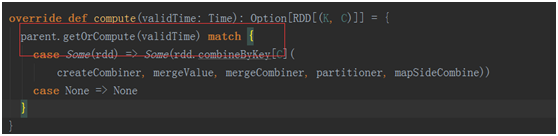
在发方法中我们有看到了parent.getOrCompute(validTime)这样的代码,继续回溯父Dstream。
在接下来的
第2行产生的类型为FlatMappedDStream 第3行产生的类型为MappedDStream
跟上面分析过程是一样的,直到我们回溯到了Dstream最开始的地方,也就是产生第一个Dstream的第一行代码:SocketInputDStream,在这个Dstream中我们将会真正得到数据!然后将得到的数据封装成RDD一层一层的返回给子Dstream,从而完成Dstream的回溯!
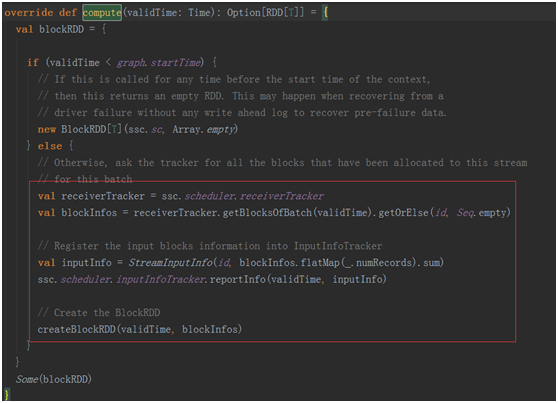
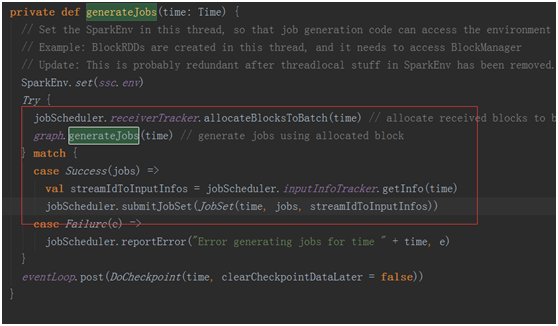
回到最开始的ForEachDStream,最终将封装进Job对象中,返回给JobScheduler
JobScheduler,收到Job进行调度

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









