





在实际项目中,如果遇到需要大计算量的操作,按需fork(分叉)其实不是一个好的选择。
因为fork的子进程也是V8(NodeJS的核心引擎)的新实例,每创建一个新实例,需要约30毫秒启动时间,和至少10MB的初始内存。
也就是说,创建进程是有代价的,你不能创建太多,也不能频繁创建。那样,达不到提高进程效率的目的。
那么,该如何高效优雅的使用子进程呢?工作池!
工作池!
合理的办法是创建一个可用的工作池,在池中存放足够多的进程,并可以随时分配使用。
我们对上一节讲的内容进行升级:当父进程发送一个任务给子进程时,子进程执行任务。并将结果向主进程反馈。
在父进程中,需要的代码会是这样的:
function doWork(job,cb){ var child = cp.fork("./worker"); //发送工作给子进程 child.send(job); //希望子进程返回一个确切的消息 child.once("message",function(result){ cb(null,result); })}嗯...这样讲有些凌乱,这一章比较复杂,最好的办法,还是写一个完整的代码,做为例子:
1、father.js,主进程
var http = require("http");var makePool = require("./pooler");var runJob = makePool("./worker");http.createServer(function(req,res){ runJob("some dummy job",function(er,data){ console.log("father callback get:",data); if(er){ return res.end("get an error:"+er.message) } res.end("work pool"); }) }).listen(8000)当有客端访问时,触发runjob,开始启行工作。
2、worker.js
process.on("message",function(job){ console.log("worker get msg:",job); for(var i=0;i<10;i++){ console.log("worker send:",job,i); process.send("finish job:"+job+i); } })收到father主进程发来的消息时,使用process.send()方法调用子进程,向工作池发出工作任务。
3、pool.js(工作池)
接收worker消息,用工作池完成操作,并反馈给主程序。
代码中做了详细的注释 ,就不单独对代码做解析了:
var cp = require("child_process");//获取CPU数量,有几个CPU就创建几个子进程,这样就可以最大化的利用机器性能var cpus = require("os").cpus().length;//模块导出函数module.exports = function(workModule){ //等待任务队列,当工作任务被下发,但没有闲工作进程时,放到此队列 var awaiting = []; //存放准备就绪的工作进程 var readyPool = []; //当前的工作子进程数量(工作池的大小) var poolSize = 0; return function doWork(job,cb){ //如果工作池数量已经最大,并且没有准备就绪的工作子进程,也就是所有工作子进程都在工作中,那么:排队等待 if(!readyPool.length && poolSize >cpus){ //压入到等待队列,等待后续处理 return awaiting.push([dowork,job.cb]); } //取得一个可用的工作子进程,或fork(分叉)一个新的子进程(增加工作池的大小) var child = readyPool.length ? readyPool.shift() : (poolSize++, cp.fork(workModule)); { //子进程是否完成回调的标记 var cbTriggered = false; //初始阶段,移除子进程上的监听,确保每个子进程只拥有一次监听 child.removeAllListeners(); //错误 child.once("error",function(err){ //未回调 if(!cbTriggered){ //回调返回为错误 cb(err); //回调标识改为true:已回调 cbTriggered = true; } //结束子进程 child.kill(); //这里不用操作工作池poolSize--,因为kill会触发exit事件,在exit事件中操作工作池 }); //子进程退出了(不明原因的意外退出、被kill()等都触发) child.once("exit",function(code,signal){ //未回调 if(!cbTriggered){ //回调,返回信息 cb(new Error("Child exited with code:"+code)) } //工作池(正在工作的子进程数)大小减一 poolSize --; //退出的子进程,是否在准备好的子进程数组中 var childIdx = readyPool.indexOf(child); if(childIdx > -1){ //从准备好的子进程数组中移除 readyPool.splice(childIdx,1); } }) //获取父进程发来的消息 child.on("message",function(msg){ console.log("pool get msg:",msg); cb(null,msg); cbTriggered = true; readyPool.push(child); //如何等待区有内容,处理之 if(awaiting.length){ setImmediate.apply(null,awaiting.shift()); } //向父进程发送消息 }).send(job); } //child区域结束 }}执行效果
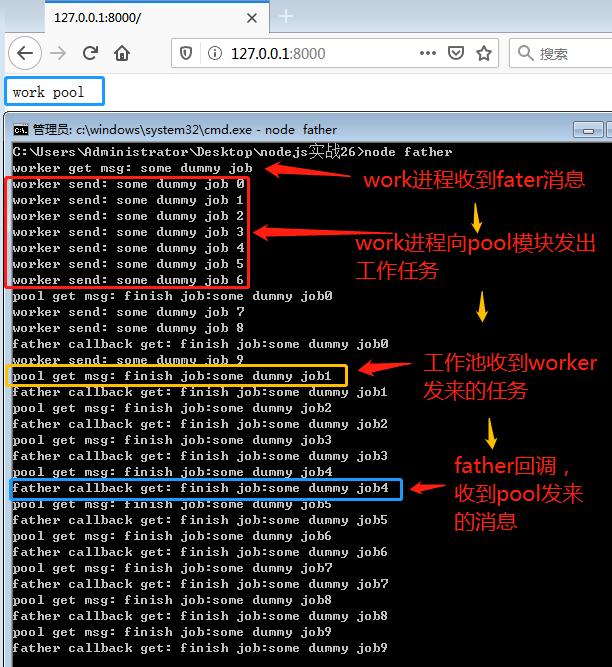
图中展示的是工作流程,可见此种方法可以达到我们的预期,工作池很OK。
对于实际编程中遇到的消耗比较大的情况,使用此种方法可以极大的提高效率,且本文已经将工作池写成了模块(pooler.js)
建议收藏,nodejs开发,在某个时候一定会遇到适合的场景的。
更多本系列文章:
Node.JS实战25:重要!大运算量?用Fork、让子进程来做
Node.JS实战24:分离子进程
Node.JS实战23:方便活灵的exec
Node.JS实战22:外部应用程序中的串联调用
Node.JS实战21:流和外部应用程序、实时数据输出















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









