






一、引入:
数据结构的划分:zhuanlan.zhihu.com
- 二维数据结构(可以想象成从一维泛化而来)
- 基础:树 tree(一维的链表分叉有两个的时候)、图 graph
- 高级(在树的基础上加了很多的特殊判断和约定条件):二叉搜索树 binary search tree(red-black tree,AVL)、堆 heap、并查集 disjoint set、字典树 Trie、etc
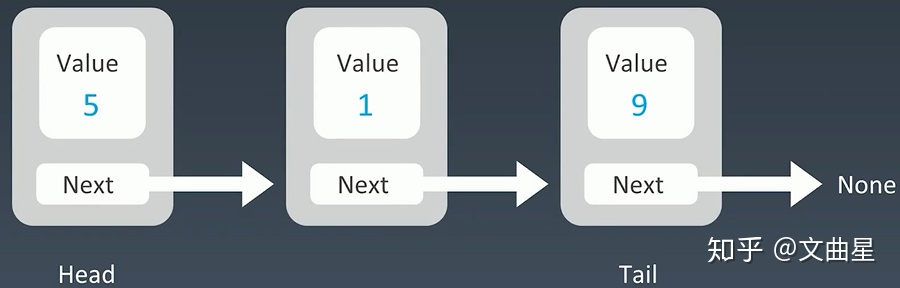
根据上图的单链表的数据结构,如果有next1、next2、next3指向多个结点的话,会变成什么?(见下图)
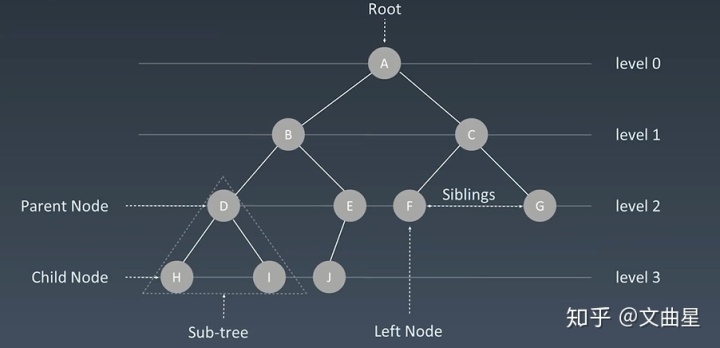
现实中用的最多的就是二叉树:
树于图最关键的差别是:有没有环?(有环为图,无环为树)
链表(Linked List)是特殊化的树(链表有两个next指针就是树) 树(Tree)是特殊话的图(也就是没有环的图就是树)
二、结点的定义
- Python
class TreeNode:
def __init__(self,val):
self.val = val
self.left, self.right = None, None2. C++
struct TreeNode{
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x): val(x),left(NULL),right(NULL){ }
}
3. Java
public classs TreeNode{
public int val;
public TreeNode left,right;
public TreeNode (int val){
this.val = val;
this.left = null;
this.right = null;
}
}三、分析:
为什么会出现树形结构?
人类本身生活在一个三维的世界、思维的世界,人类本身的工程实践,其实就是在二维的基础上解决的,而树本身的话就是人经常会碰到的一种情况,就类似于飞机本身的话并不是人发明创造的,而是它看到鸟在飞之后想到的。
例1:斐波那契的数列,其实它扩散出去的结点是一个树状的结点。
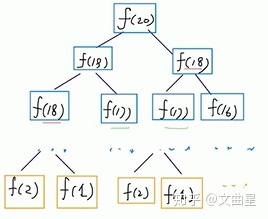
例2:阿尔法狗,或者棋类的游戏
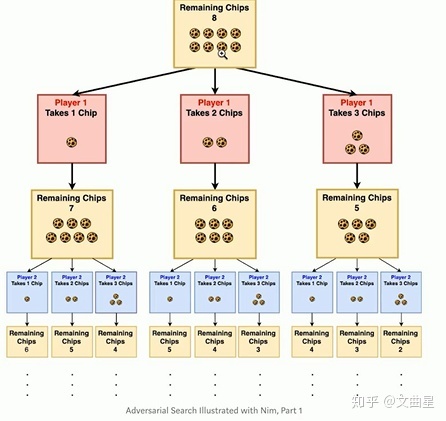
棋盘的状态就是向外扩散成不同的状态,每个不同的状态再往下面走,棋盘的状态本身的话也是一个树形结构,叶子结点就是棋盘的某一个终极形态,不同的棋的树的空间叫做状态树的空间,同时还有一个叫博弈的空间,也可以叫做决策树(decision tree)的空间,它们的复杂度不一样,决定了这个棋或者这个游戏它的复杂度。我们的人生状态(做不同的决定)也是类似于树。
四、树的遍历
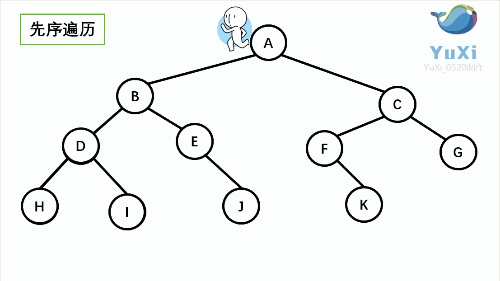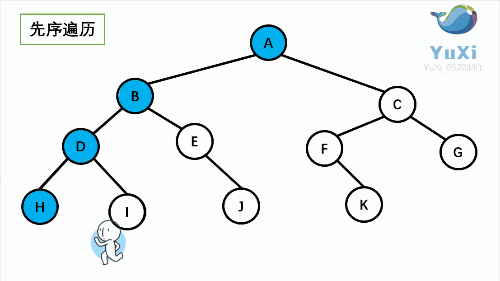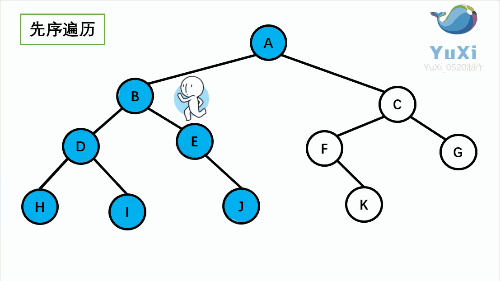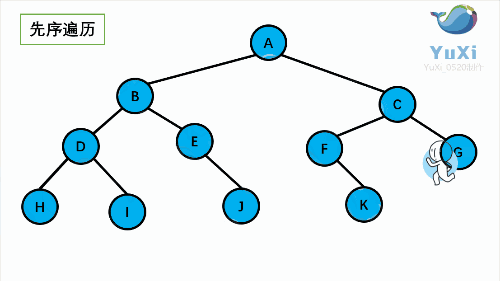
二叉树的遍历:(记忆小技巧:遍历时,先左后右不变,根在前就是前序,根在中就是中序,根在后就是后序)[1]
- 前序(Pre-order):根 - 左 - 右
2. 中序(In-order):左 - 根 - 右
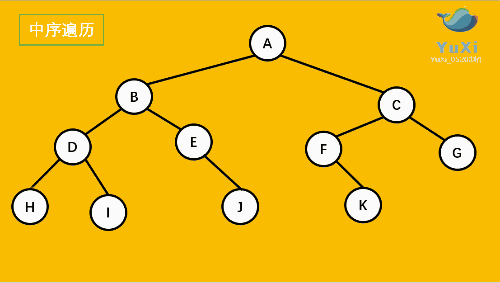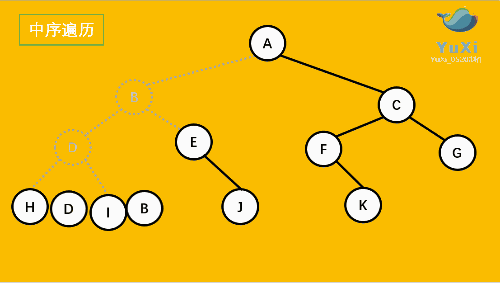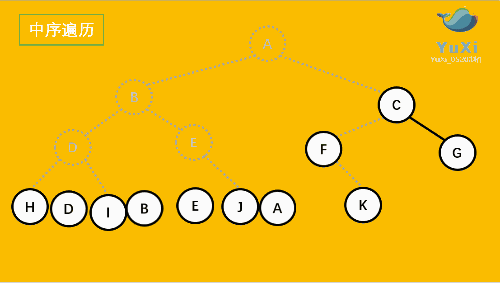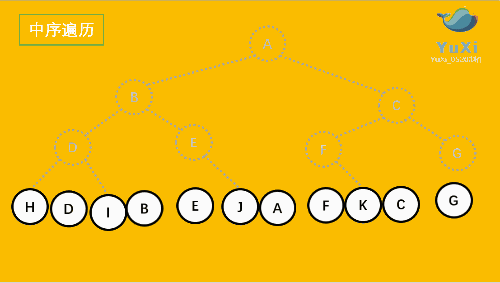
3. 后序(Post-order):左 - 右 - 根
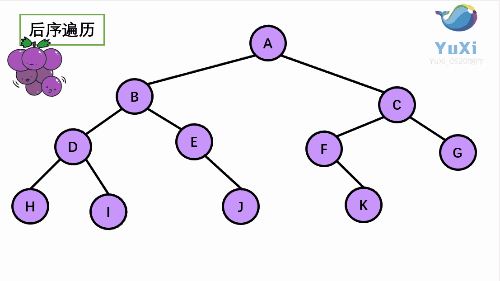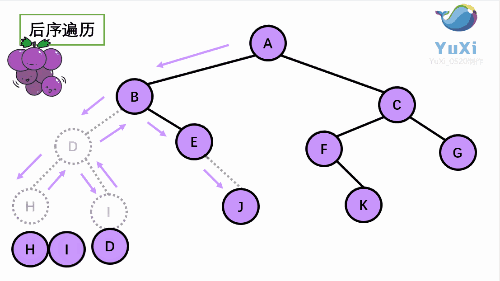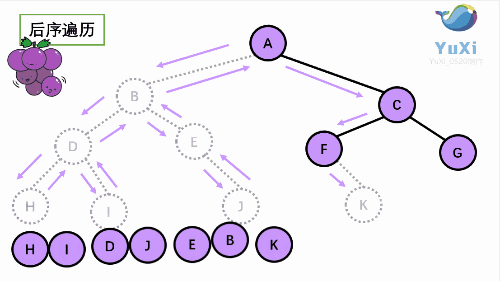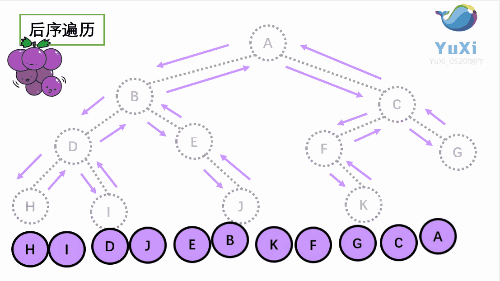
# 需要在心里做成机械化的记忆
def preorder(self,root):
if root:
self.traverse_path.append(root.val)
self.preorder(root.left)
self.preorder(root.right)
def inorder(self,root):
if root:
self.inorder(root.left)
self.traverse_path.append(root.val)
self.inorder(root.right)
def postorder(self,root):
if root:
self.postorder(root.left)
self.postorder(root.right)
self.traverse_path.append(root.val)为什么基于递归实现? 1. 树的定义本身,没法有效的进行所谓的循环,也可以强行循环(比如广度优先遍历),但是很多情况这种结构写循环相对比较麻烦,而写 递归调用相对比较简单,关于树的相关操作,不要怕递归,要拥抱递归。
2. 经常更好的一种方式: 直接对左结点调用相同的遍历函数。
3. 递归本身不存在所谓的效率差、效率低的问题,只要程序本身的算法复杂度没有写残即可!
例如:斐波那契数列如果只是傻递归,没有把中间结果储存起来,导致本身线性可以解决的问题,需要指数级的时间复杂度才能解决,这是不合理的。锅并不在递归,而是没有使用缓存,
4. 递归与非递归: 递归是不是一定会慢一点?其实慢的地方就是它要多开一些栈,如果深度很深的话,的确可能有这样的问题,但是一般情况下,现在的计算机的存储方式和编译器对于递归,特别是尾递归的优化,我们就直接认为递归和循环的效率是一样的。不需要刻意的规避这个问题。
五、二叉搜索树(Binary Search Tree)
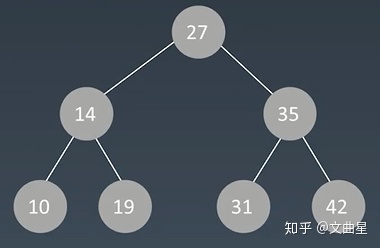
普通的树,查找结点,遍历一遍复杂度为O(n),实际与链表没有区别,没有实际意义。一般情况会把树的结构变得更加的有序:

二叉搜索树常见操作:
- 查询(复杂度不再是O(n),是logn)
- 插入新结点(创建),(复杂度不再是O(n),是logn)
- 删除
示例:
leetcode94 二叉树的中序遍历leetcode-cn.comclass Solution(object):
def inorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
res =[]
if root:
res += self.inorderTraversal(root.left)
res.append(root.val)
res += self.inorderTraversal(root.right)
return res参考
- ^动态图片借鉴 https://www.pianshen.com/article/7106254596/















 3469
3469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









