





作者:王宁柯、陈康
背景
由于各种新型号的移动终端层出不穷,为满足测试需要,公司投入测试的移动设备数量增长迅速,如何把散落在公司各个角落的移动设备有效的管理起来,提高资源利用率,如何快速适配各种品牌型号的终端设备,提升测试效率,如何能更快捷的接入自动化测试等,这些问题促就了知乎移动云测平台的诞生。
系统设计的主要目标在于提升知乎 App 的稳定性、优化用户体验、有效提升研发测试效率,主要功能如下:
- 设备管理:支持设备的自动接入,处理设备的使用申请。
- 远程调试:通过 web 页面在线进行单机控制或多机同步控制,提供设备屏幕实时画面展示和系统日志的展示。
- 自动化测试:支持兼容性自动化测试(Monkey)和 UI 功能自动化测试(Appium),提供自动化测试报告。
- 兼容性测试:安装、覆盖安装、启动、智能探索等 App 测试,观察不同设备下 App 的稳定性和容错性。
- 定向稳定性测试:在兼容性测试的基础上长时间循环执行定向智能探索脚本等对 App 进行测试,观察不同设备下 App 的稳定性。
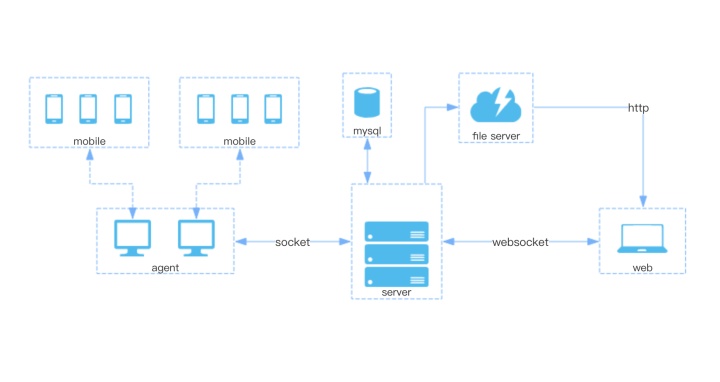
架构
知乎云测平台从结构上主要分为 web 前端、后端 server 和 agent client 三个部分:其中 web 前端专注于用户交互和数据展示;后端 server 主要负责业务控制处理,包括设备注册及状态维护,指令下发,数据收集等功能;agent client 用于管理所搭载移动终端设备,包括设备信息上报,指令执行,测试报告数据回传等功能。具体实现如下:
- web 前端
基于 React 实现,在显示设计上采用阿里的 ICE 集成方案,ICE 一套基于 React 的中后台应用解决方案,它提供了大量的可复用物料,包含了一条从设计端到开发端的完整链路,配套桌面工具能够极速构建中后台应用,即使在没有 UI 设计支持的情况下, ICE 集成的内容也基本能满足设计需求,因此我们选用了 ICE。 - 后端 server
基于 Spring Boot 框架进行开发,选用 Gradle 进行项目构建 ,集成了 Spring Data JPA、Spring Security OAuth 等组件,数据库选用 MySQL;为提升数据传输效率,我们 在 Spring Boot 中整合了 Netty 用于和 agent client 进行 Socket 通信,并选用了 Protobuf 做为数据交换格式;在「设备远程调试」功能的前后端交互设计上,我们选用了 WebSocket 协议,通过后端数据推送的方式,以保证设备操作的实时性,相较于需要使用推送实时数据到客户端甚至通过维护两个 HTTP 连接来模拟全双工连接的旧的轮询或长轮询(Comet)来说,使用 WebSocket 可以极大的减少不必要的网络流量与延迟。 - agent client
使用 Java 进行开发,最终以 jar 包的形式部署在 PC 机上,分别通过 adb 和 libimobiledevice 管理 PC 上挂载的 Android 设备 和 IOS 设备,设备挂载方式支持 USB 或 WiFi;在设备远程调试功能实现上,针对 Android 设备和 IOS 设备分别采用了不同的解决方案,我们使用了 STF(Smartphone Test Farm) 提供的开源工具 Minicap 和 Minitouch,用于 Android 设备的屏幕截图和指令运行,使用 STF 的 iOS Minicap 和 Facebook 的 WebDriverAgent 框架,用于 iOS 设备的屏幕截图和指令运行,屏幕截图即作为设备远程监控页面渲染的图片流来源;UI 功能自动化测试方案采用 Appium 开源工具进行实现,稳定性自动化测试方案其中 Android 设备采用自带的命令行工具 Monkey 实现,iOS 设备则通过程序随机生成指令进行测试。
功能介绍
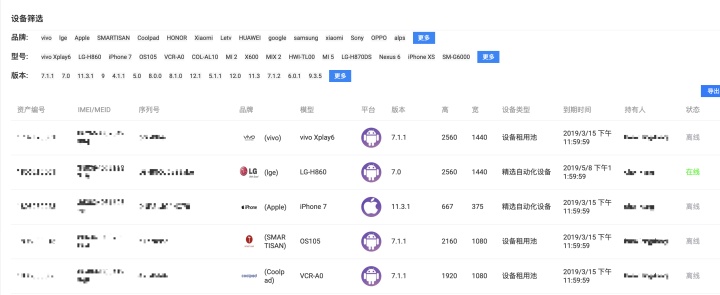
- 设备管理
移动设备以 USB 的接连方式挂载在部署有 agent client 的 PC 上,设备的机序列号、系统类型、系统版本、品牌、型号、 屏幕分辨率等信息会通过 agent 上报给后端 server,设备序列号作为设备唯一标识,进行设备信息的注册或更新操作。设备信息注册成功后,server 端负责维护设备在线状态,当设备离线时,由 agent 端进行状态上报给 server 端,server 端将对应设备状态修改为离线。前端页面上可以查看当前接入的所有手机设备信息及在线状态。
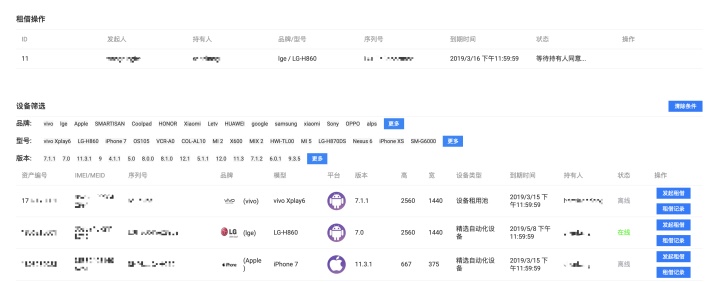
- 设备租借
对公司测试机进行统一登记管理,提供测试机租借服务,用户可通过平台的「设备租借」页面,查找需要的设备,并进行发起租借操作,待设备持有人同意租借后,即可领取测试机设备。
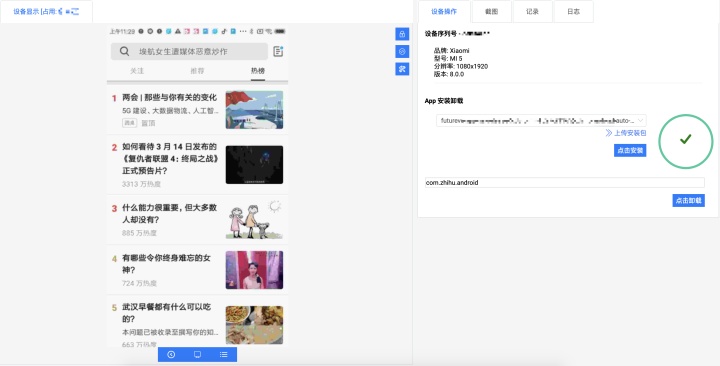
- 设备远程调试
设备远程调试功能支持通过前端页面进行远程控制设备的应用安装、启动、卸载以及常规的点击、长按、滑动等操作。
前端页面上提供一个设备屏幕等比例缩放的图片显示区域,使用 <canvas> 标签动态渲染从后端接收到的设备屏幕截图,以此实现设备屏幕局的远程监控功能。通过捕捉 <canvas> 的 onmousedown、onmousemove、onmouseover、onmouseout、onmouseup 等事件,并根据 <canvas> 控件的长高和光标当前坐标换算出触点在设备屏幕中的相对位置,最终在 agent 上根本系统平台类型生成相应的操作指令,控制设备执行指令。
同时选中多个设备,操作首个设备,其他被选中的设备会同步执行当前操作,以达到多机同步控制的效果。
- 自动化测试任务创建
支持 Monkey 和 Appium 的自动化测试,通过前端页面新建测试任务,配置相应的任务参数,任务创建成功后,由 server 端负责将任务下发给对应设备当前所挂载的 agent client,agent 收到任务即控制对应设备进行测试操作,并记录测试任务结果数据最终返回给 server 端。
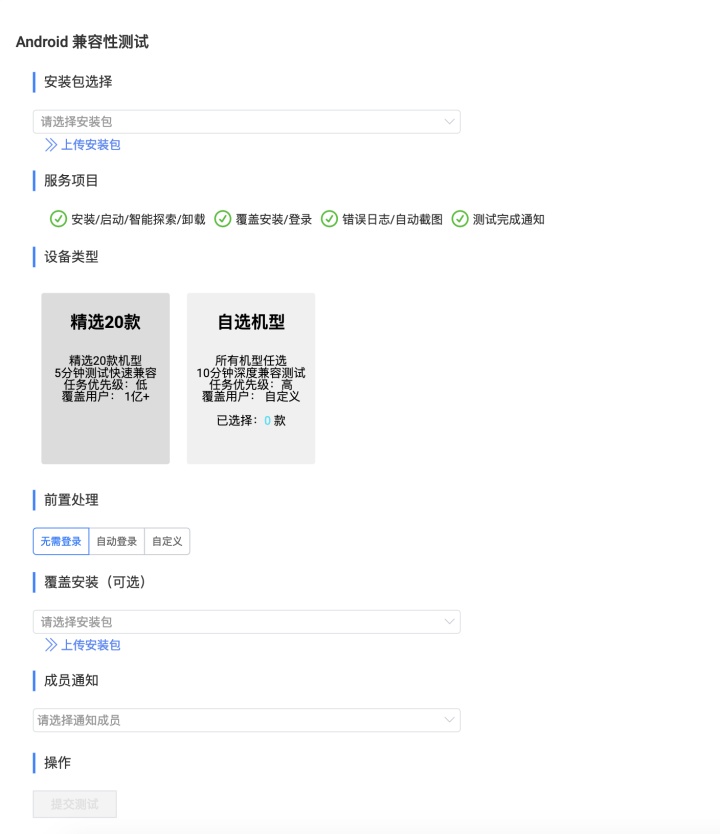
- 任务报告展示
后台 server 会对接入的每个自动化测试任务的结果做统计汇总,并按照设备维度对任务的异常统计,截图,日志等信息进行展示,以快速定位测试中遇到的问题。

远程控制界面画质处理
由于需要实时操作处理,需要实时查看远程设备的显示并交互操作指令,指令数据是以 Json 的形式进行交互,只占用很少的带宽,而实时画面显示则需要将设备的实时画面以图片流的方式渲染到对应的 web 页面上,那么在使用时图片的大小、网络传输速度、渲染性能等都会影响使用体验,其中可以主动优化的就是图片大小,由于手动编译的 stf 提供的 minicap,它本身也提供了图片压缩功能,如下是测试数据:
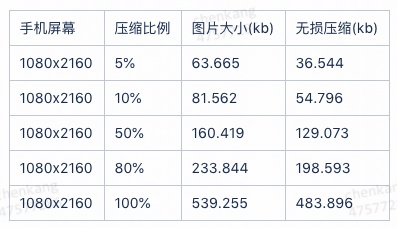
另外设备上图片的显示内容也会影响图片的大小,像图中这种留空比较多的图片也不会特别大。实际使用中需要考虑网络占用上限以及使用体验,调研发现设备实际使用过程中用户比较关注的一般都是截图和录屏,而平台单独提供了高清的截图和单独的录屏功能,所以对实时显示的画质没有特殊要求,选取 5% 的压缩比例在公司内网 2~3 M/S 的网络速度下比较流畅,另外对流畅度优化还可以体现在图片传输帧率上,可以按照一定的比例去掉中间的部分图片,用户使用过程中会感觉到图片跳动渲染,类似 gif 图片展示,由于已经选取了 5% 的压缩比例,所以没有做此优化。
远程控制多机同步
在单机远程控制上添加了多机功能,如图中选取设备:
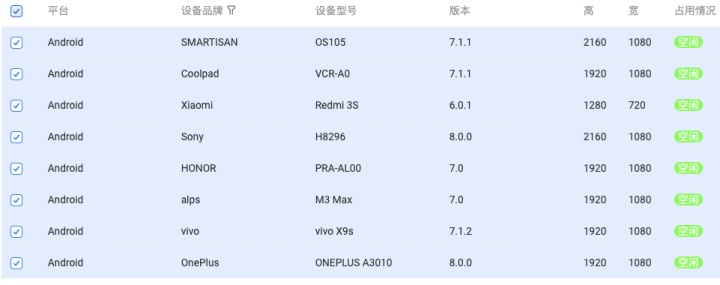
操作第一个设备时,指令同时分发到其他的设备上执行,如图展示:
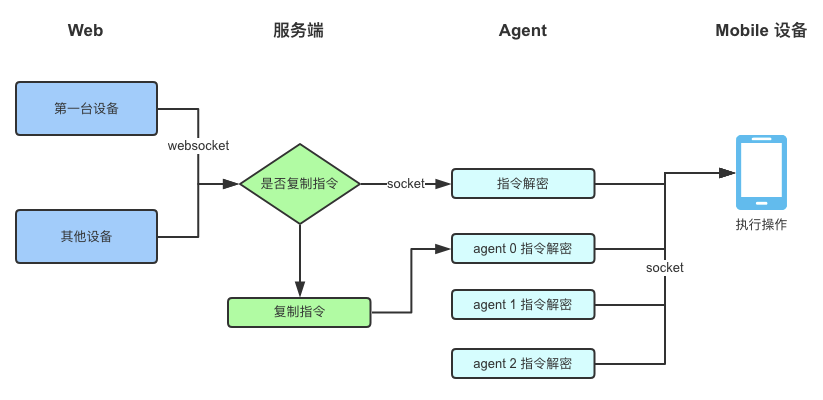
其他的设备界面也可以同时进行操作,这个地方处理主要通过 websocket 交互传递数据,在多机界面展示图片流做了降帧处理,同时限制 10~20 台的设备使用数量,在架构上用户操作的指令主要由服务端对 agent 进行复制分发,过程如图:
最后
我们期待有志于质量保证工作的知友们加入知乎质量保障团队,与知乎一起扬帆远航。详细职位可以点击 这里,期待你的加入,与我们一起做很酷的事情。
平台会继续规划集成不同类型自动化测试,提供不同类型的自动化测试能力,开放 api 接口,接入持续集成平台,下一篇文章会继续讲解系统架构中 Agent 的实现,主要关注设备控制、维护、任务运行、服务端交互等内容,敬请期待。















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









